Sparse Representation Learning for Vessels
arXiv cs.CV / 5/5/2026
📰 NewsModels & Research
Key Points
- The paper presents VAEsselSparse, an efficient encoder-decoder model for learning compact representations of full organ-level vascular networks at sub-millimeter resolution.
- It uses sparse convolutions and attention to exploit the inherent sparsity of 3D tubular structures, achieving a spatial compression rate of 8×8×8.
- Experiments show improved reconstruction quality over dense baselines and prior methods.
- The learned latent space preserves clinically relevant discriminative features that can support classification tasks such as aneurysm/stenosis and circle of Willis variants.
- The compact latent representation is also useful for generative modeling, enabling the synthesis of realistic vasculature using vessel-specific priors.
Related Articles

Singapore's Fraud Frontier: Why AI Scam Detection Demands Regulatory Precision
Dev.to
From OOM to 262K Context: Running Qwen3-Coder 30B Locally on 8GB VRAM
Dev.to

Nano Banana Pro vs DALL-E 3 vs Midjourney: A Practical Comparison From Someone Who Actually Uses All Three
Dev.to
LLMs edited 86 human essays toward a semantic cluster not occupied by any human writer [D]
Reddit r/MachineLearning
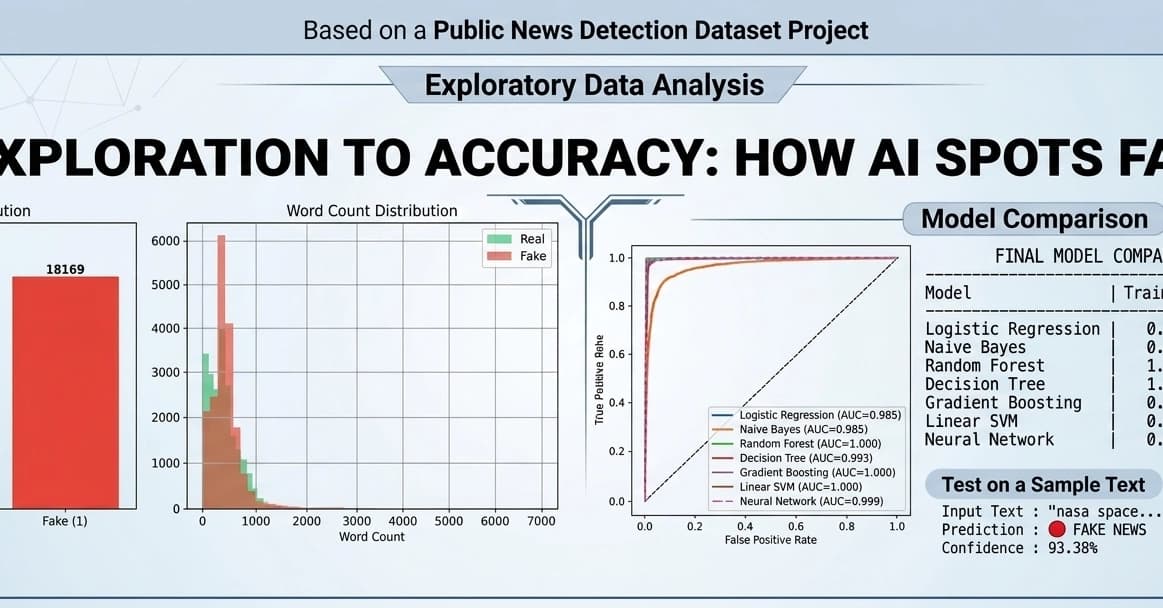
Fake News Detection using Machine Learning & NLP!
Dev.to