【大朗報】AIインフルエンサー量産の「正解」がついに判明!Flux.2 Kleinと新技術〇〇で顔を完全固定する超実践ハンズオン

どうも皆さん!エレベーターの出入口はよく人とぶつかりそうになります、 葉加瀬あい(ハカセアイ) です!
ということで今回ご紹介するのは、ローカル環境のComfyUIで驚異のキャラクター同一性を実現する技術、 「Flux2Klein-Enhancer」とNVIDIAの最新アップスケーラー「PiD」を組み合わせた高精度キャラ固定術 です!

これまで「画像を生成するたびに顔や服装が別人になってしまう…」と頭を抱えていた皆さんに向け、

複数のリファレンス画像を賢く読み込ませて特徴を100%固定し、
さらにNVIDIAの最新アルゴリズムで実写のような4Kクオリティへと一気にデコードする一連の手法を解説していきます!


ということで今回お話しする内容はこんな感じです!
画像コラージュはもう卒業!複数フレームから特徴を完璧に転送する同一性保持ノードの仕組み
2段階処理を1つに統合!NVIDIAの最新技術「PiD」がもたらす爆速&超高解像度デコード革命
画像のインプットと日本語の指示だけで別アングルのポーズや背景のショットを無限量産する実践ハンズオン

動画版はこちらからどうぞ!
なお、YouTube では note の内容を動画に変換して公開しているので、まだの方は noteのフォロー や YouTubeのチャンネル登録 もお願いします!
それでは、本日もよろしくお願いします!
技術解説:Flux2Klein-Enhancerが実現する同一性の極み
ということで、画像生成AIの世界で、多くのクリエイターをずっと悩ませてきた「生成するたびにキャラクターの顔が変わってしまう問題」…皆さんも一度は経験ありますよね?

これを根本から解決してくれる最新の仕組みが、今海外のコミュニティでも大きな話題になっている 「FLUX.2 Klein」 なんです!

そして今回は、サンプリング部分でこのFLUX.2 Kleinのマルチリファレンス機能(アイデンティティフィックス)を使っていくのにプラスして、以前私が解説した 「Flux.2 KleinのLoRA学習」 で作ったLoRAも一緒に適用させていきます!
https://note.com/ai_hakase/n/n86720990fcca
Flux.2 KleinのLoRAについては、こんな感じでデータセットの準備から学習までをサクッと簡単にやる方法をこちらの記事で解説しています!
https://note.com/ai_hakase/n/n8b8991044bd6
このLoRAは、キャラクターの一貫性を少しサポートしてくれるような位置づけになるので「絶対に必須!」というわけではないんですが、やっぱりLoRAがあった方が、より一貫した精度の高いキャラクターが出やすくなります!
もちろん、AIなのでそれでも100発100中とまではいかないんですけれども、今回紹介するFlux.2 Kleinのアイデンティティフィックス機能とLoRAを掛け合わせることで、驚くほど精度の良いものができちゃうんです!

今回ご紹介するワークフローでは、これまでよくやっていた「4分割のグリッド画像にして1枚で読み込ませる」といった力技(これはVAEがコラージュ画像として誤認しちゃう欠点があったんですよね…)は完全に卒業し、強力な最新カスタムノードをメインに据えて使っていく感じですね!
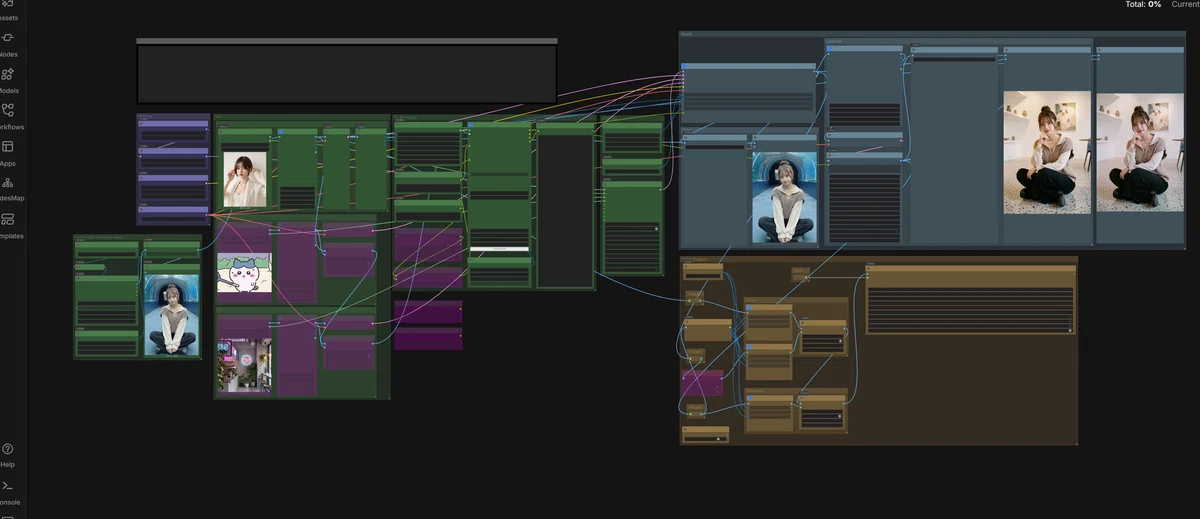
この技術の本当に素晴らしいところは、正面、横顔、別の衣装など、個別のリファレンス画像をそのまま別々に読み込ませることができる点です!
これまでのやり方みたいに、ノードを数珠つなぎ(Stacked Nodes)にしてワークフローが「スパゲッティ状態」になるのをすっきりと解消し、ひとつのノードでスマートに完結できちゃうんです。これによって、管理のコストが激減しました!

異次元のディテール:NVIDIA PiDによる4K超解像革命
そして今回はもう一個ダメ押しで画像をリアルにする技術を紹介します!
仕上げのクオリティを極限まで高めていきましょう!

そこで登場するのが、NVIDIAが新しくリリースした革新的なデコード手法 「PiD(Pixel Diffusion Decoder)」 を搭載したアップスケーラーです!
https://research.nvidia.com/labs/sil/projects/pid/

これまでの画像生成ワークフローでは、AIが内部で扱う圧縮されたデータ空間(潜在空間/Latent)から一度VAEデコードによって画像に戻し、そこからさらに別のAIを使って解像度を上げるという「2段階のステップ」を踏むのが一般的でした。そのため、処理に時間がかかったり、拡大した際に細部がボケてしまうことがありました。

しかし、このNVIDIAのPiDは、その常識を完全に覆します!
PiDは「デコード」と「アップスケール」を1つの工程に完全統合。生成中の中間データ(latent/sigma)をガイドにしながら、低解像度のデータからダイレクトに高精細なピクセル(画素)空間へ一気に4倍の超解像をかけて描き出すことができるんです!
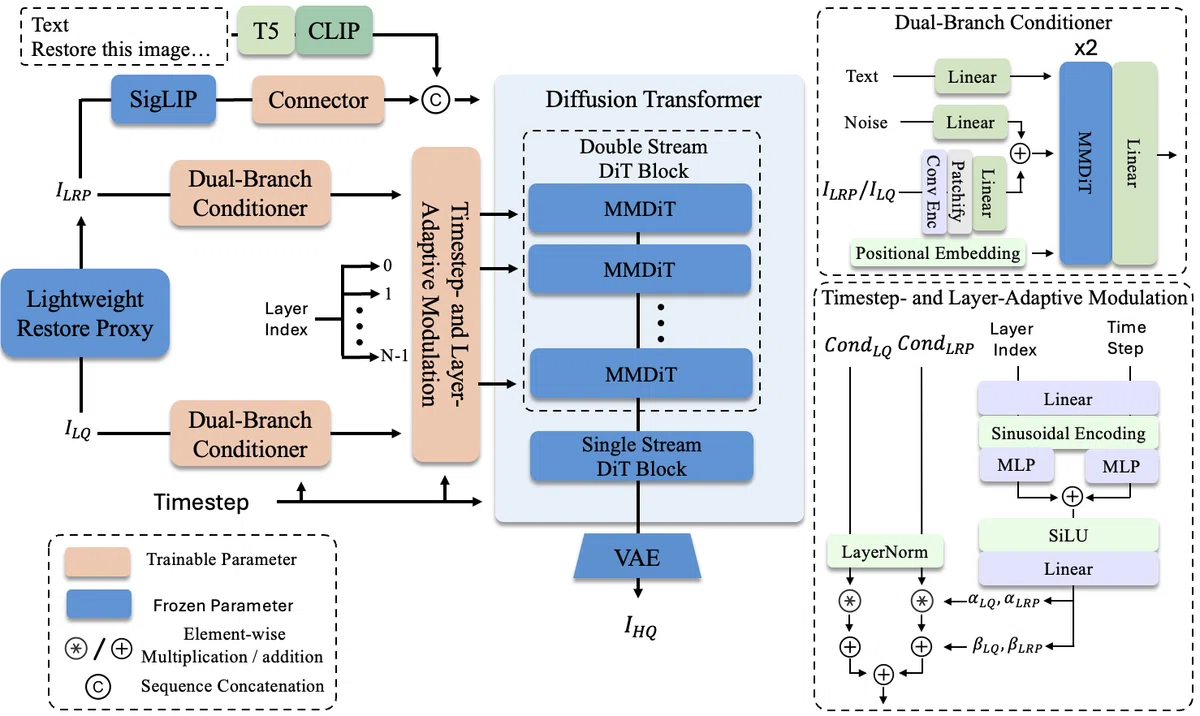
この技術がもたらすメリットは圧倒的です。
驚異的な爆速処理: 処理のパイプラインが統合されたことで、これまでは時間がかかっていた4K(2048px)クラスへのアップスケールが、RTX 5090環境であればなんと 1秒未満 という驚異的なスピードで完結します!
プロ級のリアリズム質感: 単なる画像の引き伸ばしではなく、AIがピクセル単位の拡散プロセスによって細部を「新しく緻密に描き足す(ハルシネーションする)」ため、非常にリアルな肌の品質、洋服の細かな繊維、アクセサリーの輝きや陰影が、密度の高いクオリティで表現されます。
キャプション不要(Caption-free): 高画質化する際に、その画像の内容をわざわざテキストで説明するプロンプトを入力する手間が一切ありません。どんな画像であってもボタン一つで実写レベルの4Kへと引き上げられます。

速度重視のモデルと、このクオリティ特化型のPiDデコーダーを組み合わせることで、まさに「速くて綺麗」を地で行く最高の仕上がりが手に入ります!
先ほど解説したIdentity FixやLoRAに、このアップスケーラーを組み合わせて使うことで、ダメ押しのリアリティをもっと出していくことができるというわけですね!

事前準備:複数リファレンス素材の制御と自動化
キャラクターの一貫性をより盤石にするため、正面・横顔・別衣装など、最大3つまでの複数リファレンス画像を個別に読み込ませて制御できる「マルチリファレンス」のセッティングも搭載しています!
複数画像を扱うとノードの繋ぎ替えが面倒になりがちですが、そこはUIを工夫して自動化しています!グループノードを「Ctrl+B(バイパス)」するだけで、リファレンス素材を有効にするか、無効(インプットの対象から外す)にするかを簡単に切り替えられるようになっています。
また、いつもの通りVLM(視覚言語モデル)のノードも用意しています。今回はQwen 3.6を使っていきます!インプットされた画像と適当なテキスト指示をもとに、LLMがプロンプトの自動リファインを行って、生成や編集に使える完璧な状態に仕上げてくれます。
面倒なリサイズ処理も、画像の縦横比に合わせて全自動で行うロジックを組んでいます。ですので、皆さんは「画像のインプット」と「適当なテキストの入力」を行うだけ!
たったこれだけで、インプットした画像のキャラクターの別アングルのショット、別のポーズ、別の背景にいるときのショットなどを無限に量産できます。
LoRAを使ってパワーアップさせ、さらに新しいPiDのアップスケーラーで2Kや4Kの超リアルな品質に仕上げていく……はっきり言ってめちゃくちゃおすすめです!リアルなAIインフルエンサーの量産も、これでかなり簡単になるかと思います!
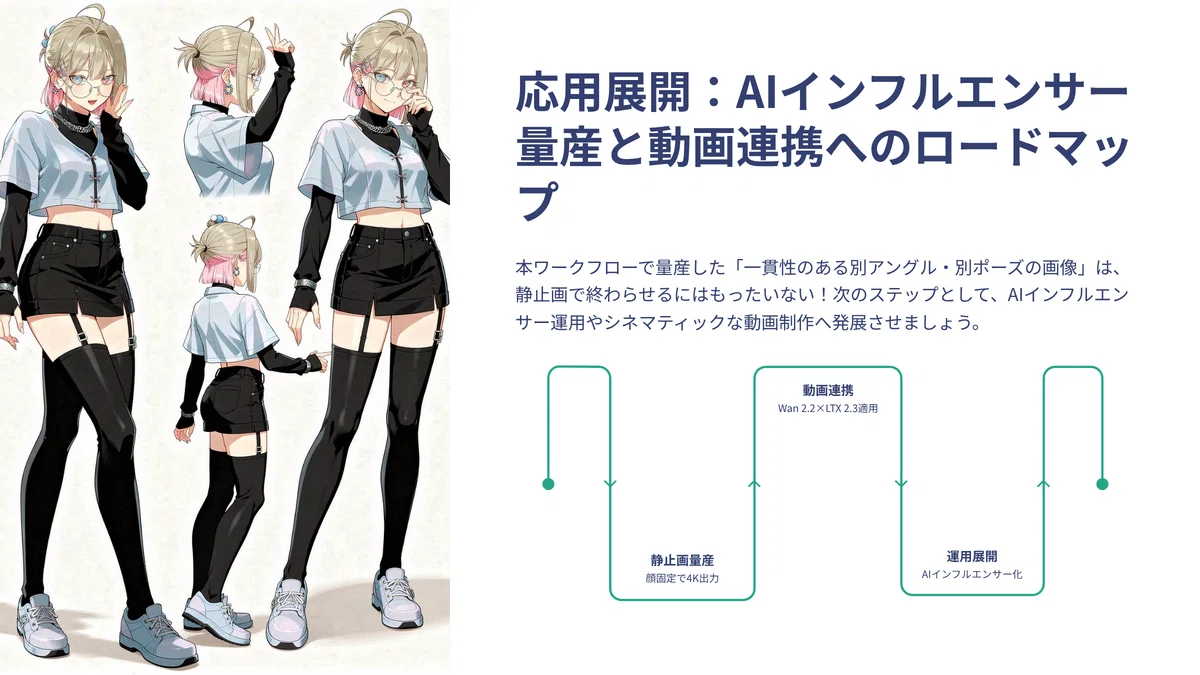
応用展開:AIインフルエンサー量産と動画連携へのロードマップ
それと、本ワークフローで量産した「一貫性のある別アングル・別ポーズの画像」は、ただの静止画として終わらせるにはもったいないです!次のステップとして、AIインフルエンサー運用やシネマティックな動画制作へ発展させる方法をご提案します。
動画に展開する際は、以前私がご紹介した「Wan 2.2とLTX 2.3のハイブリッド動画生成」の技術がそのまま活きてきます!
📚 参考文献・関連リンク
Wan2.2 × LTX2.3ハイブリッド生成: https://note.com/ai_hakase/n/nf6baeeb15ecf
さらに、プロンプトベースでシーンをコントロールするマルチリファレンス機能付きの「プロンプトリレー」へ生成画像を組み込んでいけば、皆さんの指示したシーンに合わせて、同一キャラクターが滑らかに動く高品質な映像作品へ一気に昇華させることができます!
📚 参考文献・関連リンク
プロンプトリレーマルチリファレンス: https://note.com/ai_hakase/n/n4861652b30fc
静止画で究極の「顔固定」と「ディテール」を作り込み、それを動画へ連携させていく。これこそが、個人でも妥協なくクリエイティブを追求できる最強のロードマップになります!

ハンズオン:ComfyUIワークフローの解説と実践
ということでここからは、その 「Flux2Klein-Enhancer」と「NVIDIA PiD」を組み合わせた最強の高精度キャラ固定&超解像化 を無料AIツールのComfyUIから簡単に使っていく方法についてハンズオンで解説していきたいと思います!
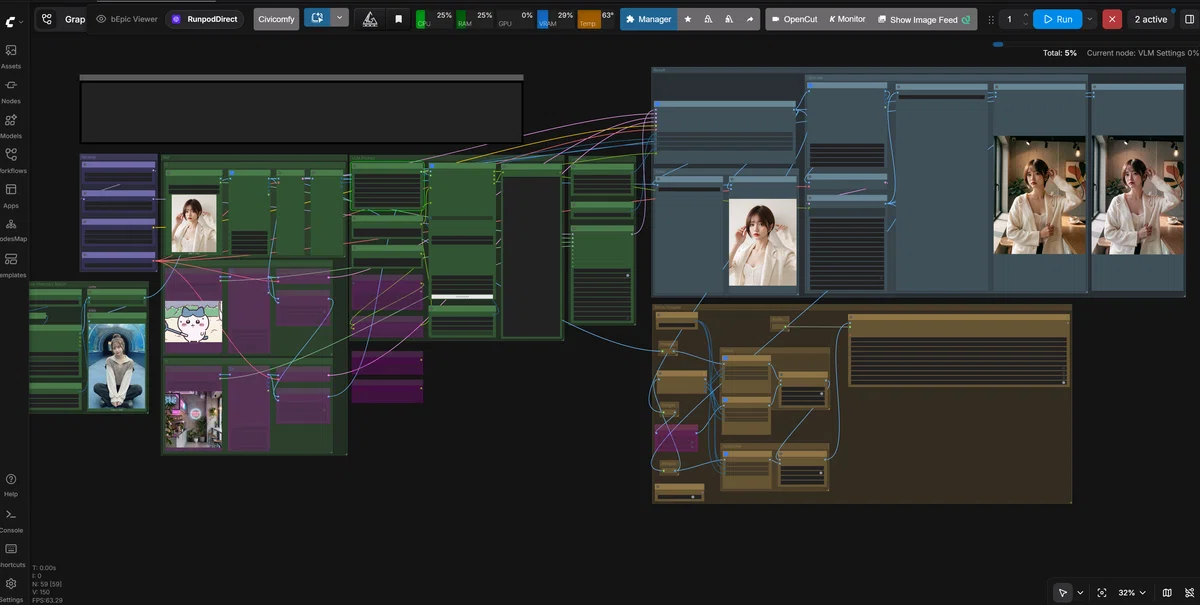
今回もローカル環境や、
Runpod などのクラウド環境でも動かせるようにやっていきたいと思います。
ちなみに、初心者の方とか、ComfyUIがちょっと難しそうで自信がないなっていう方のために、こちらでたった1クリックで使い始められる方法を解説しているのでよかったらぜひ参考にしてください!
https://note.com/ai_hakase/n/n9eb2265f98f7
ぜひ、 皆さんもこのワークフローを活用して、リアルなAIインフルエンサーの量産や、一貫性のある画像生成を体験してみてください!
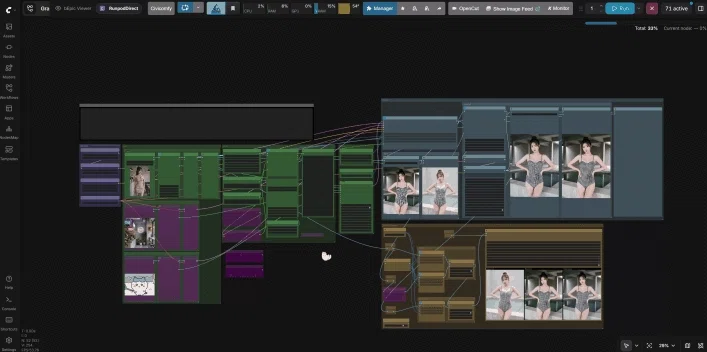
ということで、ここからは私のNoteメンバーシップ「 あいらぼ(Ai-Lab) 」の入門者さん限定でやっていきたいと思います!
https://note.com/ai_hakase/n/ncdcda4208fd7
人数制限 を設けているので、気になる方はお早めに以下のURLから入門して続きをご覧ください!
それでは実際にこちらのワークフローを説明したりお配りしたりしていこうかと思います!
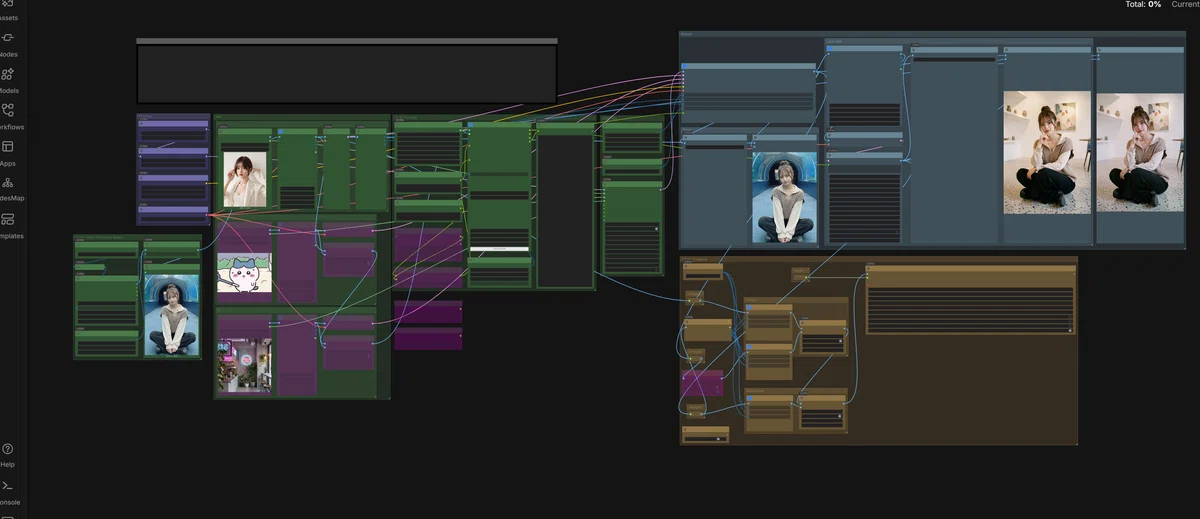
まずは、この先に表示されるNoteの限定リンクから、 「Jupyterノートブック」 と 「ワークフローファイル」 の2つをダウンロードしてください!
ローカル環境で実行する方 → 「ワークフローファイル」のダウンロードだけで大丈夫です!ただし、セットアップでつまずいてしまった場合は、どちらかの「ipynb」ファイルを参考にセットアップを進めてください。
【推奨】 Runpodで実行する方 → 「ワークフローファイル」と「Rp_run_comfyui_hakase_v2.0.ipynb」をセットでダウンロードしてください!

ここから先は
メンバーシップ
¥ 2,599 /月
あいらぼ (Ai-Lab) は、NoteとYouTubeを活用して、皆さんを「生成AIを使いこなす側…
🐾あいらぼ (Ai-Lab):記事/動画/質問プラン
🎥𓈒最新AI技術の『記事・動画』の閲覧が自由に。 🔰質問OKで、初心者の方も安心です。 👤定員に達し次第、募集終了となります。 (質疑応答の人数に限りがあるためです。) ご入門はお早めに! ※ 募集終了後もXのDMにて知らせていただければ上限アップも検討します👌
- 🌟動画で解説❗️Noteの内容を耳と目で確認できます🌟
- 最新版のAIをクラウドから、どんなPCでも使う方法を紹介❗
- Midjourney
- Stable Diffusion
- 生成AI技術紹介
- ComfyUI
- AI Tuber
- Flux
- メンバーシップについて
- AI・はじめましてセット
- LLM
- 画像生成AI
- 動画生成AI
- 音声・楽曲 生成AI
- 海外・バズり本 & オーディオブック
- 海外本:オーディオブック編
- メンバー限定の掲示板
- メンバー限定の記事
- メンバー特典マガジン
- メンバー限定の会員証
- 活動期間に応じたバッジ
- #副業
- #AI
- #生成AI
- #マーケティング
- #AIとやってみた
- #SNS
- #AI副業
- #画像生成AI
- #効率化
- #マネタイズ
- #StableDiffusion
- #動画生成AI
- #時短術
- #ai創作
- #ComfyUI
- #コンテンツ制作
- #ローカルLLM
- #AIビジネス
- #技術解説
- #デジタル資産
- #クリエイター支援
- #Flux
- #AiTuber
- #先行者利益
- #HuggingFace
- #FLUX1
- #葉加瀬あい
- #ハカセアイ
- #AIインフルエンサー
- #初心者向けAI
- #ComfyUIワークフロー
- #実践ガイド
- #ComfyUI使い方
- #I2V
- #Runpod
- #AIタレント
- #FLUX2
- #画像から動画
- #JupyterNotebook
- #超解像
- #アップスケーラー
- #ComfyUIWorkflow
- #Qwen36
- #unsloth
- #FLUX2klein
- #実写系AI
- #キャラクター固定
- #AIマニュアル
- #最新AIトレンド
- #プロンプト自動生成
- #顔固定
- #ペーパースペース
- #爆速生成
- #VLMプロンプト
- #ComfyUIノード
- #動画生成AI使い方
- #マルチリファレンス
- #NVIDIA技術
- #自動リサイズ
- #GGUF量子化
- #プロンプトリレー
- #一貫性保持
- #MultiReference
- #FaceConsistency
- #スパゲッティ解消
- #Temperature制御
- #Similarityフィルター
- #HardLock
- #MediumLock
- #SoftLock
- #カオブレなし
- #フェイスドリフト対策
- #Wan22連携
- #LTX23連携
- #葉加瀬あいワークフロー
- #あいらぼメンバーシップ
- #動画と音声の完全同期
- #口パクAI
- #リップシンク精度
- #Merserk
- #MTP推論
- #ハンズオン解説
- #モデル自動ダウンロード
- #バイパス制御
- #モデル固定
- #AIインフルエンサー量産
- #4Kアップスケール
- #PiDデコーダー
- #PixelDiffusionDecoder
- #NVIDIAPiD
- #IdentityFix
- #IdentityFeatureTransfer
- #Flux2KleinEnhancer
- #LLMプロンプト
この記事が気に入ったらチップで応援してみませんか?