TelcoAgent-Bench: A Multilingual Benchmark for Telecom AI Agents
arXiv cs.CL / 4/9/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- TelcoAgent-BenchとTelcoAgent-Metricsは、LLMエージェントを通信(テレコム)ネットワークに統合する際の課題(意図認識、ツール実行、解決生成)を多言語で評価するための通信特化ベンチマーク枠組みを提案しています。
- このフレームワークは、意図認識の精度だけでなく、構造化されたトラブルシューティング手順とのプロセス整合性、ツールの順序実行、解決の正確さ、同一シナリオの変形に対する安定性を測定します。
- 英語とアラビア語の両言語で動作する設計により、実運用を想定した多言語エージェント配備ニーズに対応します。
- 実験では、指示チューニング済みの最新モデルがテレコム問題の理解は比較的できる一方で、必要な手順を一貫して遵守したり、シナリオ変形下で安定挙動を維持したりするのが難しいことが示され、そのギャップは非制約・バイリンガル条件でより大きくなると報告されています。
Related Articles
Research with ChatGPT
Dev.to
Silicon Valley is quietly running on Chinese open source models and almost nobody is talking about it
Reddit r/LocalLLaMA

Why AI Product Quality Is Now an Evaluation Pipeline Problem, Not a Model Problem
Dev.to
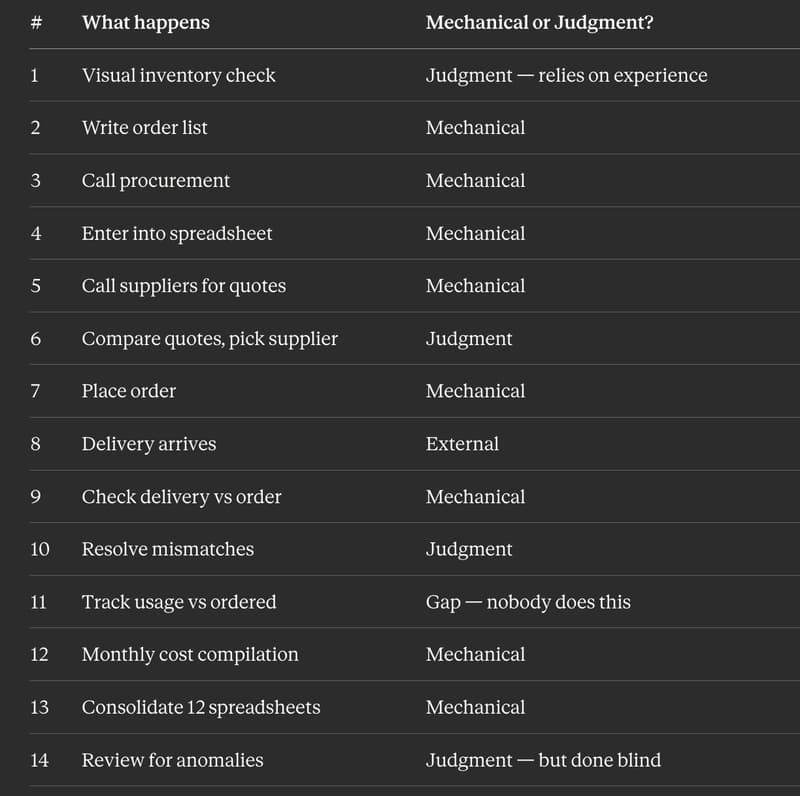
I Replaced 12 Kitchen Managers Guessing "How Much Chicken Do We Need" With 3 ML Models. Here's the Entire Architecture.
Dev.to

AI Model Router API - REST + MCP, Free Tier
Dev.to