Addressing Data Scarcity in Bangla Fake News Detection: An LLM-Based Dataset Augmentation Approach
arXiv cs.CL / 5/5/2026
📰 NewsModels & Research
Key Points
- The paper tackles misinformation detection challenges in Bangla, where progress is constrained by small and imbalanced datasets.
- It proposes an LLM-based dataset augmentation framework that generates synthetic Bangla news using the instruction-tuned Gemma 3 27B IT model, with semantic filtering and subsampling to maintain label consistency and diversity.
- The study compares zero-shot vs. few-shot prompting, multiple augmentation rates, and random vs. similarity-based selection, finding the best results when only the minority class is augmented with a high rate plus random subsampling.
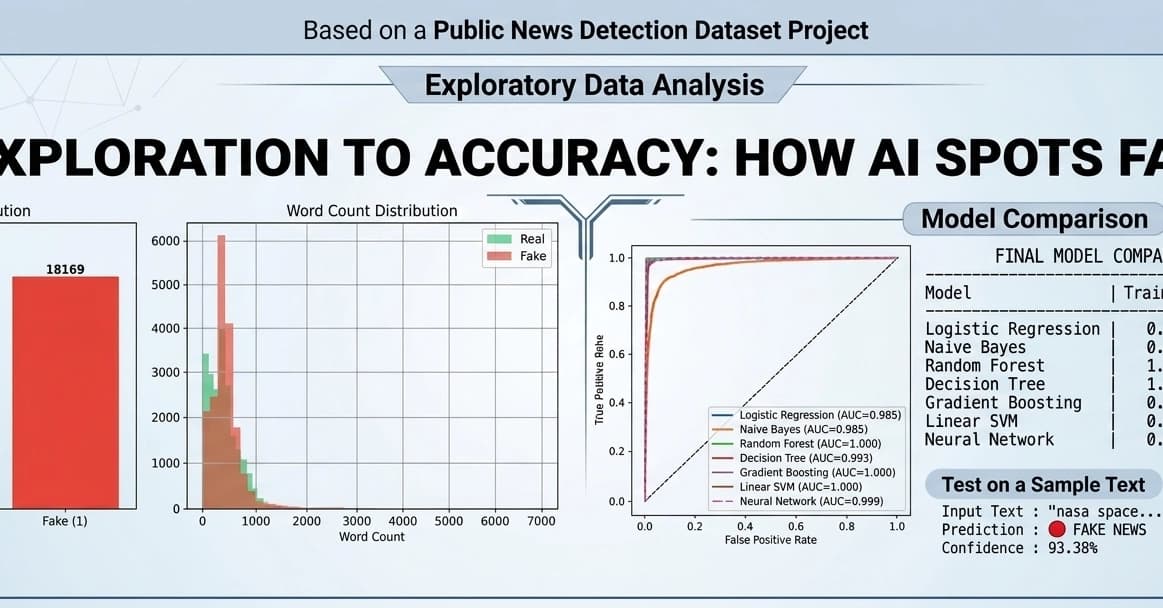
- Using this approach, the Fake News F1 score improves from 0.85 to 0.88.
- To enable reproducibility, the authors publicly release 4,545 synthetic Bangla fake news samples and the full implementation.
Related Articles

Singapore's Fraud Frontier: Why AI Scam Detection Demands Regulatory Precision
Dev.to
From OOM to 262K Context: Running Qwen3-Coder 30B Locally on 8GB VRAM
Dev.to

Nano Banana Pro vs DALL-E 3 vs Midjourney: A Practical Comparison From Someone Who Actually Uses All Three
Dev.to
LLMs edited 86 human essays toward a semantic cluster not occupied by any human writer [D]
Reddit r/MachineLearning
Fake News Detection using Machine Learning & NLP!
Dev.to