SpatialFusion: Endowing Unified Image Generation with Intrinsic 3D Geometric Awareness
arXiv cs.CV / 4/30/2026
📰 NewsIdeas & Deep AnalysisModels & Research
Key Points
- The paper introduces SpatialFusion, a new framework aimed at giving unified image generation models intrinsic 3D geometric awareness for better spatially coherent outputs.
- It augments an MLLM with a parallel spatial transformer via a Mixture-of-Transformers design, using shared self-attention so the system can infer metric-depth maps from semantic context.
- Spatial geometric signals are then injected into the diffusion backbone through a dedicated depth adapter to provide explicit spatial constraints during generation.
- Using a progressive two-stage training approach, SpatialFusion improves performance on spatially-aware benchmarks, reportedly outperforming strong baselines like GPT-4o.
- The method is claimed to improve both text-to-image generation and image editing while keeping inference overhead negligible.
Related Articles

Can AI Predict Pollution Before It Happens? The Smart Solution to an Old Problem
Dev.to
THE FIFTH TRANSMISSION: THE GRADIENT IS THE GOVERNMENT
Reddit r/artificial
Looking for feedback on OpenVidya: an open-source AI classroom layer for NCERT/CBSE [R]
Reddit r/MachineLearning
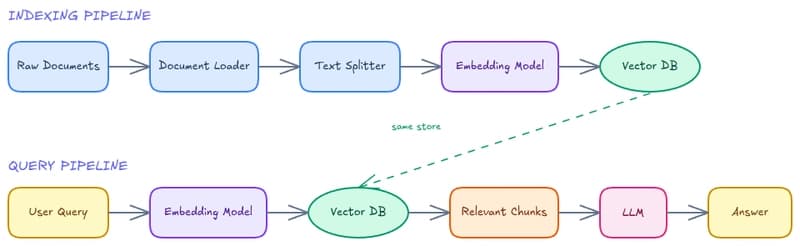
RAG Series (1): Why LLMs Need External Memory
Dev.to

One Open Source Project a Day (No. 54): Warp - The AI-Native Rust Terminal
Dev.to