Deployment-Relevant Alignment Cannot Be Inferred from Model-Level Evaluation Alone
arXiv cs.AI / 5/7/2026
📰 NewsSignals & Early TrendsIdeas & Deep AnalysisModels & Research
Key Points
- The paper argues that deployment-relevant alignment cannot be reliably inferred from model-level evaluation scores alone, because benchmarks often measure different things than what deployment claims assume.
- It proposes indexing alignment evidence by the collection level—model-level, response-level, interaction-level, or deployment-level—rather than using a single model score to justify alignment.
- An audit of 11 (expanded to 16) alignment benchmarks, scored with an eight-dimension rubric (Cohen’s kappa = 0.87), finds that user-facing verification support is missing across all benchmarks examined, and process steerability is nearly absent.
- A blinded cross-model stress test on 180 transcripts shows that the effectiveness of verification scaffolds is model-dependent, indicating that benchmark gaps identified at the model level cannot be fixed without broader system-level evaluation.
- The authors recommend a system-level evaluation agenda using alignment profiles, fixed scaffolding protocols for comparable interactional tests, and reporting templates that clarify the gap between evaluation evidence and deployment claims.
Related Articles

What Is an MCP Gateway — and Why Do Enterprise AI Teams Need One in 2026?
Dev.to
Decoupled DiLoCo: A new frontier for resilient, distributed AI training
Dev.to

Are You Still Coding — or Just an AI Manager Now?
Dev.to
AI uses less water than the public thinks, Job Postings for Software Engineers Are Rapidly Rising and many other AI links from Hacker News
Reddit r/artificial
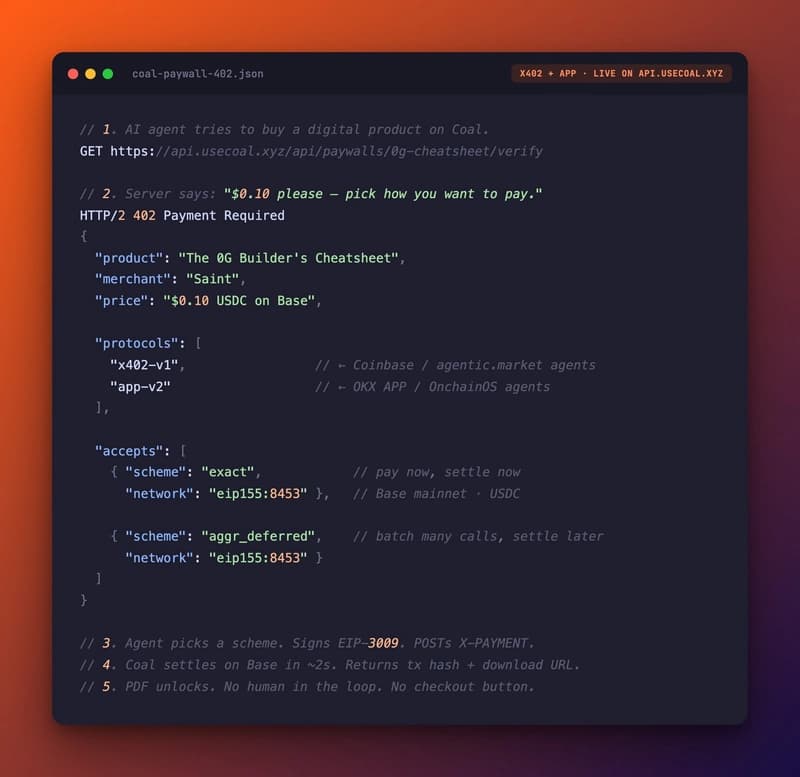
Why AI agents still can't buy anything yet
Dev.to