SFT-GRPO Data Overlap as a Post-Training Hyperparameter for Autoformalization
arXiv cs.LG / 4/16/2026
📰 NewsIdeas & Deep AnalysisModels & Research
Key Points
- The paper presents a controlled ablation study on how the overlap between supervised fine-tuning (SFT) data and Group Relative Policy Optimization (GRPO) prompts affects post-training performance for Lean 4 autoformalization.
- Experiments on Qwen3-8B (with thinking disabled) compare base, SFT-only, GRPO-only, and SFT+GRPO setups with 0%, 30%, or 100% GRPO prompt overlap with the SFT corpus, keeping compute cost constant.
- Results show that keeping SFT and GRPO data disjoint consistently outperforms full overlap at zero additional compute, with performance improving monotonically as overlap decreases.
- On Gaokao-Formal, 0% overlap produces a 10.4 percentage-point semantic gain from GRPO over SFT alone, while at 100% overlap both compilation and semantic metrics flatten, making GRPO effectively redundant.
- The study finds that dual-metric evaluation uncovers large compile-vs-semantic gaps (over 30 points) that would be missed by compile-only benchmarking, positioning SFT-GRPO overlap as a meaningful post-training hyperparameter.
Related Articles

The AI Hype Cycle Is Lying to You About What to Learn
Dev.to

Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to

Inside NVIDIA’s $2B Marvell Deal: What NVLink Fusion Means for AI Ethernet Fabrics
Dev.to

Automating Your Literature Review: From PDFs to Data with AI
Dev.to
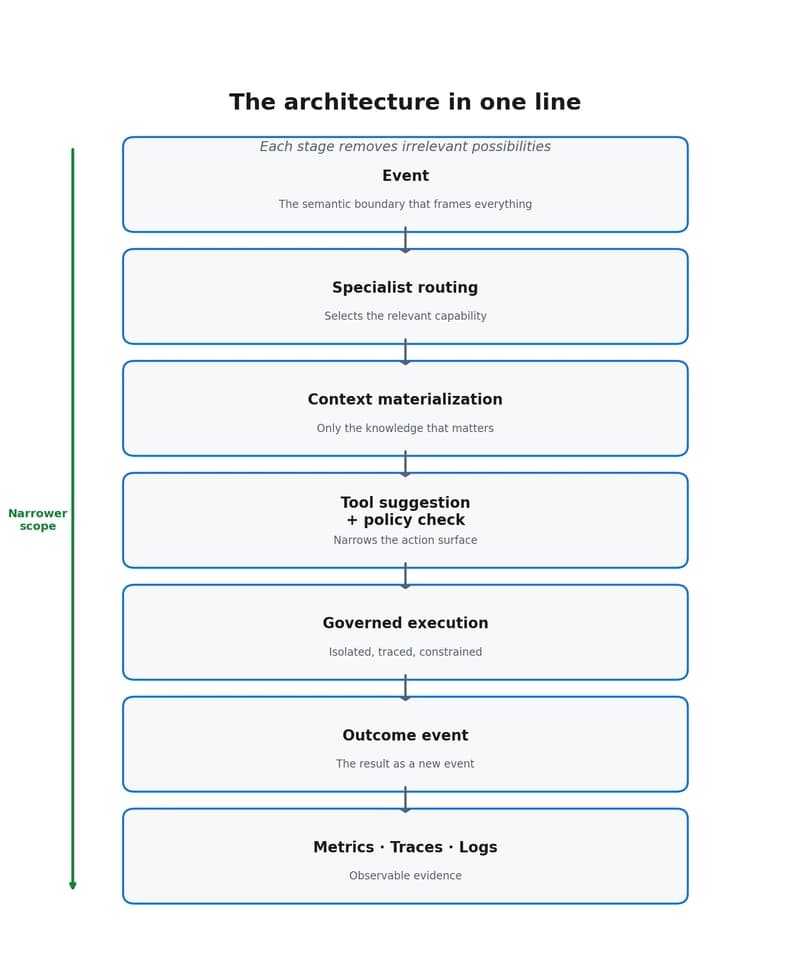
Why event-driven agents reduce scope, cost, and decision dispersion
Dev.to