Embedding-based In-Context Prompt Training for Enhancing LLMs as Text Encoders
arXiv cs.CL / 5/5/2026
📰 NewsModels & Research
Key Points
- The paper introduces EPIC, an embedding-based in-context prompt training method that uses continuous embeddings instead of discrete text demonstrations to reduce token overhead from ICL.
- EPIC leverages contrastive learning to align semantically related text pairs while training the model to treat demonstration embeddings as part of the in-context prompt.
- Models trained with EPIC maintain strong embedding performance both when in-context prompts are provided and when they are omitted at inference.
- Experiments on the MTEB benchmark show EPIC achieves new state-of-the-art results, outperforming frontier models trained only on publicly available retrieval data.
- The authors’ ablation studies support that the proposed mechanism is both effective and necessary for the observed gains.
Related Articles

Singapore's Fraud Frontier: Why AI Scam Detection Demands Regulatory Precision
Dev.to
From OOM to 262K Context: Running Qwen3-Coder 30B Locally on 8GB VRAM
Dev.to

Nano Banana Pro vs DALL-E 3 vs Midjourney: A Practical Comparison From Someone Who Actually Uses All Three
Dev.to
LLMs edited 86 human essays toward a semantic cluster not occupied by any human writer [D]
Reddit r/MachineLearning
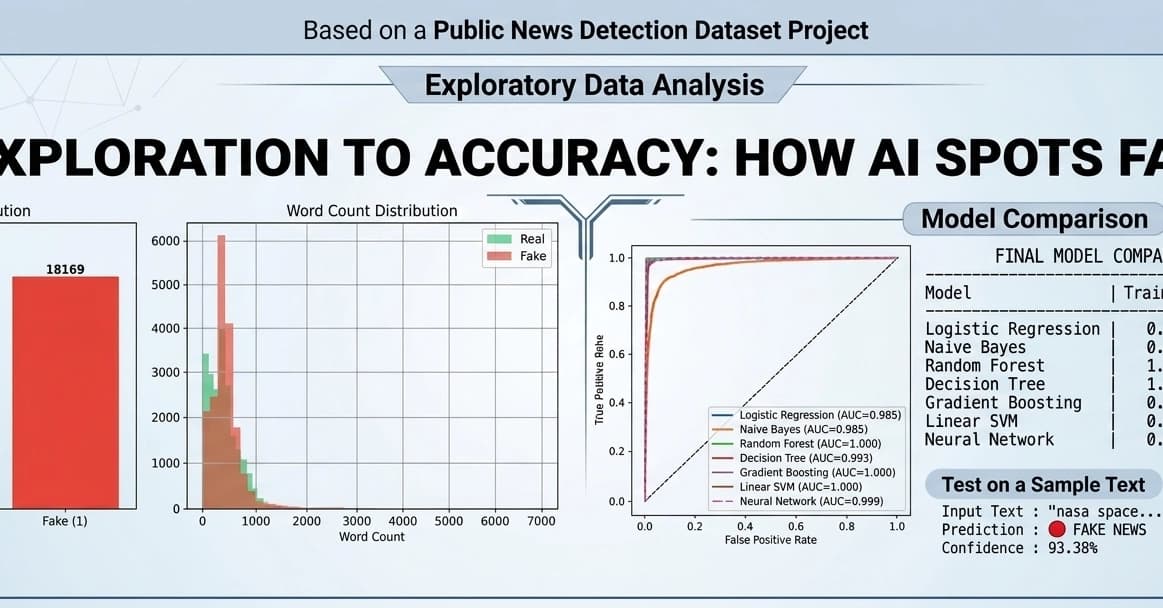
Fake News Detection using Machine Learning & NLP!
Dev.to