![[P] LLM with a 9-line seed + 5 rounds of contrastive feedback outperforms Optuna on 96% of benchmarks](https://external-preview.redd.it/DrorsMXGDmsFscWxhW_Q4WFGyPDS_HszjkX-ehKzT6E.png?width=320&crop=smart&auto=webp&s=ed73b6e035e9e34672b80f518f27c9ae3bfd9b23) | submitted by /u/se4u [link] [comments] |
[P] LLM with a 9-line seed + 5 rounds of contrastive feedback outperforms Optuna on 96% of benchmarks
Reddit r/MachineLearning / 3/30/2026
💬 OpinionIdeas & Deep AnalysisTools & Practical UsageModels & Research
Key Points
- A proposed LLM optimization approach uses only a 9-line “seed” prompt plus 5 rounds of contrastive feedback to guide the search for better solutions.
- The method is reported to outperform Optuna across 96% of benchmarks, suggesting a strong advantage over a popular black-box hyperparameter optimization baseline.
- The linked write-up frames the technique as “contrastive feedback” (likely via iterative prompting/selection) rather than traditional optimizer-driven tuning.
- The results emphasize benchmark-level performance gains, implying improved efficiency and effectiveness for experimentation workflows.
- If validated broadly, this could shift practitioners’ preference from conventional tuning frameworks toward prompt-driven, feedback-based optimization loops.
Related Articles

Black Hat Asia
AI Business
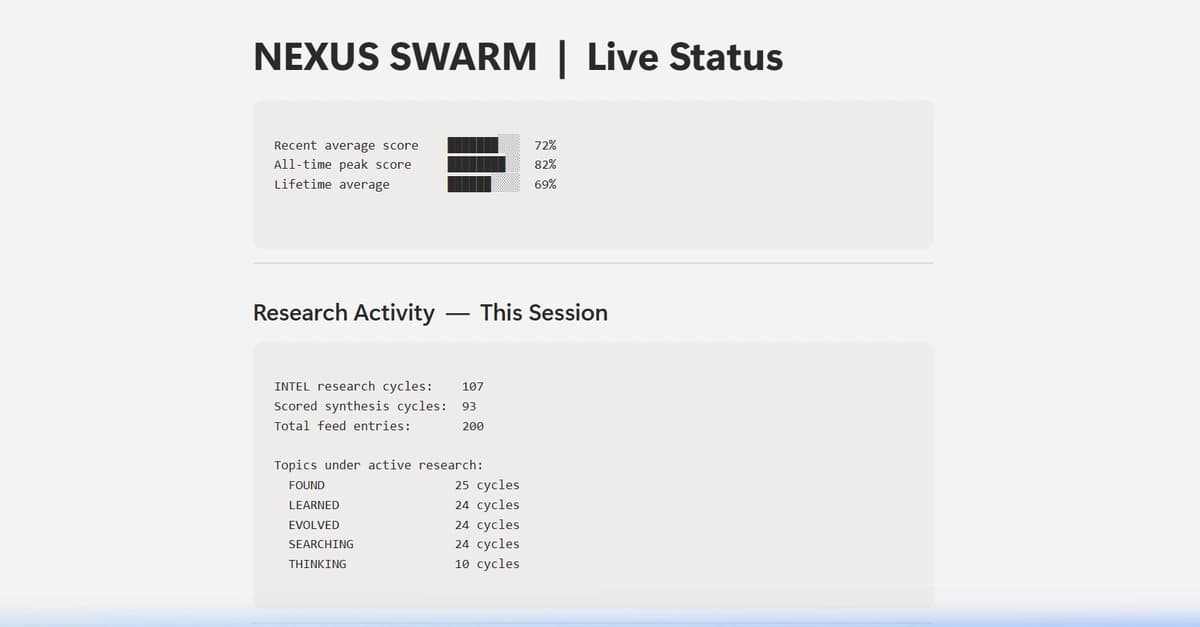
The Brand Gravity Anomaly: Uncovering AI Developer Friction with a 5-Organ Swarm and Notion MCP
Dev.to

Hyper-Personalization in Action: AI-Driven Media Lists
Dev.to

Learning Thermodynamics with Boltzmann Machines
Dev.to

Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to