RAPTOR: A Foundation Policy for Quadrotor Control
arXiv cs.RO / 4/7/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- RAPTORは、単一のエンドツーエンド方策で多様なクアドロターを制御できる「適応型のfoundation policy」を学習する手法だと述べています。
- 既存のRLベースのニューラル制御は特定環境に過適合しSim2Realギャップや機体変更で崩れやすい一方、RAPTORは計測・再学習なしのゼロショット適応を狙っています。
- 10種類の実機(32g〜2.4kg、モータ/フレーム/プロペラ/飛行コントローラ構成が多様)で検証し、3層・合計2084パラメータという小型ポリシーでもゼロショット適応が可能だと報告されています。
- アダプテーションは隠れ層のrecurrenceと、Meta-Imitation Learning(1000機ごとに教師をRLで学習→蒸留)によるin-context learningで実現する設計です。
- 追従(trajectory tracking)や屋内外、風擾乱、機体への「poking」、プロペラ種の違いなど多条件で性能を広くテストしています。
Related Articles

Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to

Could it be that this take is not too far fetched?
Reddit r/LocalLLaMA

npm audit Is Broken — Here's the Claude Code Skill I Built to Fix It
Dev.to

Meta Launches Muse Spark: A New AI Model for Everyday Use
Dev.to
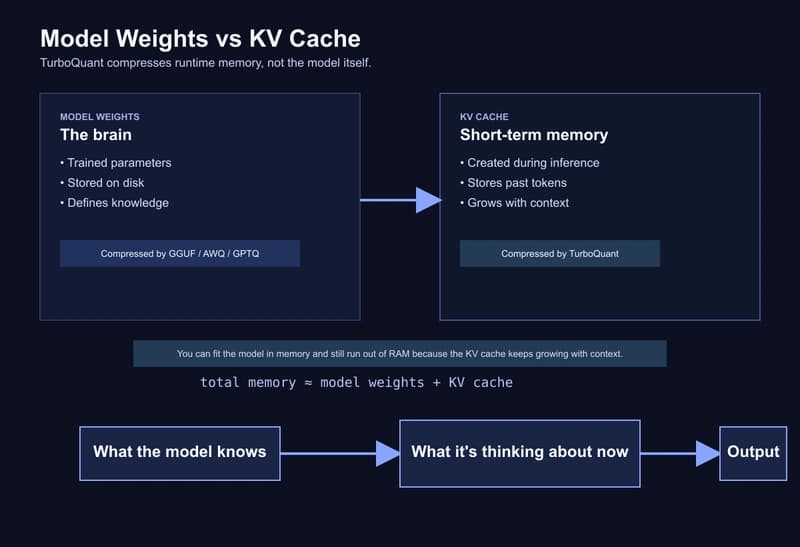
TurboQuant on a MacBook: building a one-command local stack with Ollama, MLX, and an automatic routing proxy
Dev.to