Model Privacy: A Unified Framework for Understanding Model Stealing Attacks and Defenses
arXiv stat.ML / 4/7/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- The paper introduces a unified theoretical framework, “Model Privacy,” to systematically analyze model stealing attacks against ML models accessed via limited query-response interfaces.
- It formalizes the threat model and attack/defense objectives, and proposes metrics to quantify how effective different attack and defense strategies are.
- The authors study fundamental tradeoffs between model utility and privacy, providing guidance on how security measures impact performance.
- A key insight is that effective defenses depend on the attack-specific structure of perturbations, suggesting defenses should be tailored to attacker behavior.
- The framework is validated through experiments across multiple learning scenarios from a defender’s perspective, showing that defenses designed under the proposed theory work well in practice.
Related Articles

Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to

Could it be that this take is not too far fetched?
Reddit r/LocalLLaMA

npm audit Is Broken — Here's the Claude Code Skill I Built to Fix It
Dev.to

Meta Launches Muse Spark: A New AI Model for Everyday Use
Dev.to
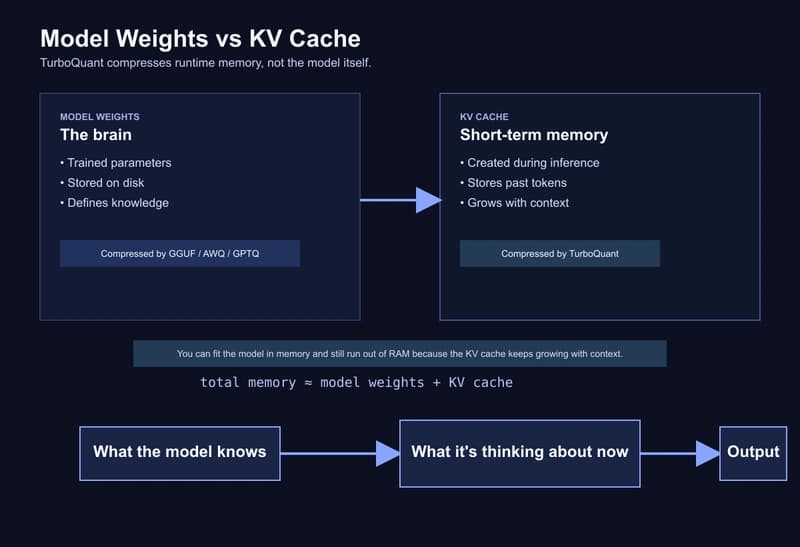
TurboQuant on a MacBook: building a one-command local stack with Ollama, MLX, and an automatic routing proxy
Dev.to