PersonalHomeBench: Evaluating Agents in Personalized Smart Homes
arXiv cs.AI / 4/21/2026
📰 NewsDeveloper Stack & InfrastructureIdeas & Deep AnalysisModels & Research
Key Points
- The article introduces PersonalHomeBench, a new benchmark designed to evaluate foundation models acting as agentic assistants in personalized smart-home settings.
- The benchmark is built via an iterative setup that constructs increasingly rich household states and uses them to generate personalized, context-dependent tasks.
- It pairs the benchmark with PersonalHomeTools, a toolbox that supports household information retrieval, appliance control, and situational understanding to enable realistic agent-environment interaction.
- Experiments assess both reactive and proactive agent behaviors under unimodal and multimodal observations, showing performance declines as task complexity rises.
- The study finds major weaknesses in counterfactual reasoning and in partially observable scenarios, where agents need effective tool-based information gathering.
Related Articles

¿Hasta qué punto podría la IA reemplazarnos en nuestros trabajos? A veces creo que la gente exagera un poco.
Reddit r/artificial

Why I Built byCode: A 100% Local, Privacy-First AI IDE
Dev.to

Magnificent irony as Meta staff unhappy about running surveillance software on work PCs
The Register
v0.21.1
Ollama Releases
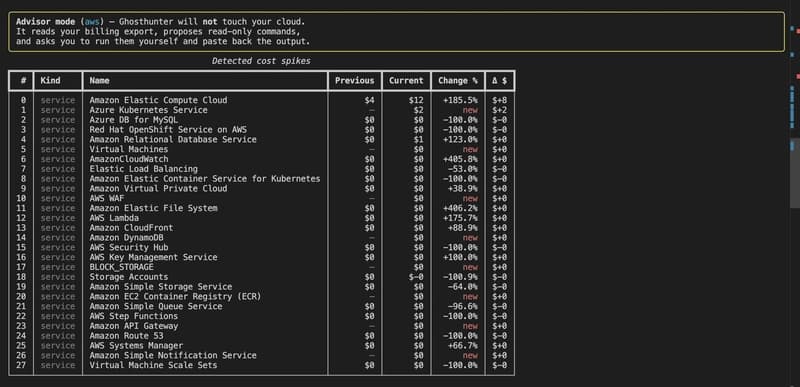
How I Built an AI Agent That Investigates Cloud Bill Spikes (Architecture Inside)
Dev.to