
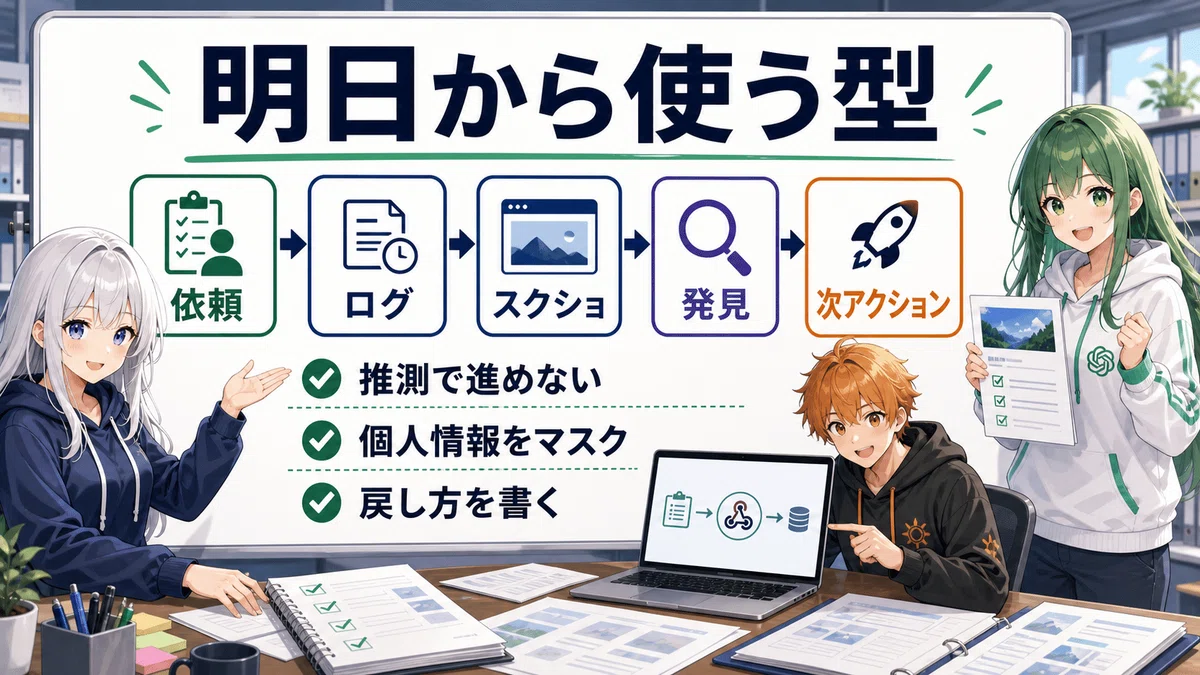
コードなしで、AIに「ログイン作業」を渡せる時代が来た🔥Codex Chrome × Evidence Pack

「ログインが必要なWeb業務は、AIに任せにくい」
問いがズレていた、と最近気づいた。
最近のCodex周りを見ていると、もう少し違う景色が見えてきた。
📝見てもらった方がはやい!このnoteを書いてもらってみた

ブラウザ作業を、検品できる“証拠束”として残す話だ。
スクショ、操作ログ、発見事項。
この3つをセットで返せるなら、ログイン必須のWeb業務は「やりました報告」ではなく、ちゃんとした納品物になる。
そしてこの後、FBをAIに行うことで自分専用のAIに寄せていくことができる!
🤔 「ログイン必須」はAI代行不可ではない
AIに頼みにくい業務として、よく出てくるのがブラウザ作業だ。
ログインが必要
権限がある人にしか見えない
画面の状態が毎回変わる
エラーや警告の意味を読み取る必要がある
たしかに、APIで綺麗に自動化するのは難しい。
でも、ここで止まるのは少しもったいない。
問題は「AIがブラウザを触れるか」だけではない。
もっと大きいのは、AIに何を渡して、何を返してもらうかが決まっていないことだと思う。
たとえば、依頼者が欲しいのは「操作しました」ではない。
本当に欲しいのはこれ。
どの画面を見たのか
どの操作をしたのか
何が分かったのか
次に何をすればいいのか
失敗した時に戻せるのか
つまり、ブラウザ作業は「実行」だけだと弱い。
証拠として残して、初めて仕事になる。
🔧 「コードなし」の正体はChrome Extension
ここで言う「コードなし」は、AIが魔法みたいに全部やるという意味ではない。
ログイン処理や認証コードを、自分で実装しなくていいという意味だ。
具体的には、Codex CLIとChrome Extensionを使う。
Codex CLIは、OpenAIが出しているCLIツール。
ターミナルから自然言語で指示して、ファイル操作、コード実行、調査、修正などを進められる。
ここにChrome Extensionが加わると、話が少し変わる。
ローカルのChromeとCodexをつなぎ、ブラウザでログイン済みの状態が必要な作業にもCodexを使えるようになる。
つまり、毎回API認証を組むわけではない。
OAuthの実装から始めるわけでもない。
自分のChromeで見えている画面を前提に、Codexへ「この画面を確認して、証拠を残して」と渡せるようになる。
もちろん、何でも触らせていいわけではない。
だから重要になるのが、許可するサイトを絞ること。
Chrome Extensionには、Codexがアクセスできるサイトを管理するallowlistの考え方がある。
「どのサイトだけ触っていいか」を先に決める。
そのうえで、作業の結果をスクショ、操作ログ、発見事項として残す。
この組み合わせがかなり大きい。
ログイン済みの画面をAIに見せられることと、見た結果を検品できる形で残すこと。
この2つが揃うと、ブラウザ作業はただの作業代行ではなく、納品物に近づく。
この記事で扱うEvidence Packは、その「返し方」の型だ。
🧰 導入で必要なのはこの設定
では、実際に何を入れて、どこを許可すればいいのか。
最低限見る場所はここだ。
ChromeにCodex Chrome Extensionが入っている
Codexアプリ側でGoogle Chromeの使用が許可されている
note.com と editor.note.com が許可済みドメインに入っている
▶ [スクショ挿入: Codexアプリ設定 > コンピューターの使用 > Google Chrome。Webサイト、履歴、ダウンロード、アップロードが「常に許可」。許可済みドメインに https://note.com と https://editor.note.com]
▶ [スクショ挿入: Chrome拡張機能一覧。Codex 1.1.4 / Control Chrome with Codex / 有効化済み]
自分の環境では、Codexアプリ側の「コンピューターの使用」からGoogle Chromeを開き、次のように設定している。
Webサイト:
常に許可
履歴:
常に許可
ダウンロード:
常に許可
アップロード:
常に許可
許可済みドメイン:
https://note.com
https://editor.note.com
これで「noteの公開ページを見る」「noteの編集画面を見る」「必要なら画像をアップロードする」という作業を、Codex Chrome経由で扱える土台ができる。
もちろん、全部を常に許可にする必要があるわけではない。
仕事用やクライアント案件なら、毎回確認にしておく方が安全な場面もある。
ただ、今回のように自分のnote制作フローを回すなら、対象ドメインを note.com と editor.note.com に絞ったうえで許可しておくのが現実的だと思う。
ここまでできて、初めて次の話になる。
Codex Chromeで画面を見る。
Evidence Packで証拠を残す。
その証拠を見ながら記事を編集する。
この流れにすると、AIにブラウザ作業を頼む時の不安がかなり減る。
🧯 詰まったところもEvidenceになる
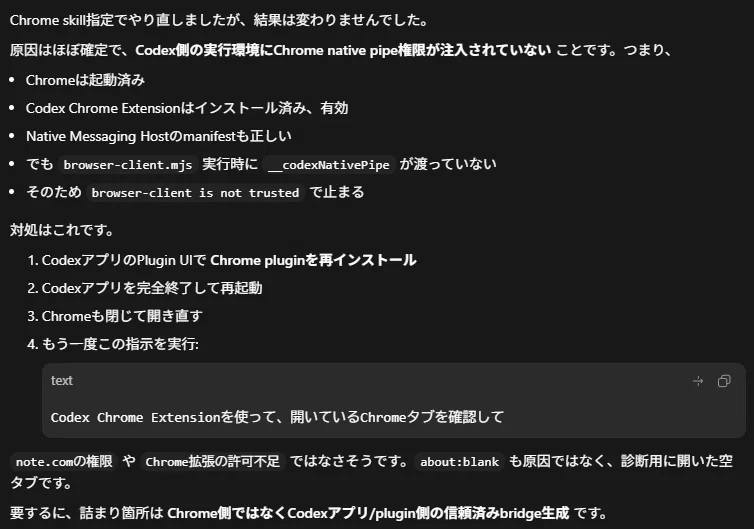
Chrome拡張は入っている。
Native Hostも正常。
Codexアプリ側のGoogle Chrome設定も、note.com と editor.note.com の許可も入っている。
それでも、このセッションではCodex Chrome操作ができなかった。
出たエラーは上記の画像。ここで英語に直して、英語圏で検索して解決方法を探してください。と自分は命令した。
このnoteで一番価値があるかもしれない。AIを使えないという人はAIに言われた通りに直そうとしても直らないと嘆く。自分は同じような人が英語圏ならいる可能性が高く、エラーが起きているAIの状態を信じない経験があった。
今の時代で一番誇れる能力なのかもしれない。
privileged native pipe bridge is not available; browser-client is not trusted
▶ [スクショ挿入: 「privileged native pipe bridge is not available; browser-client is not trusted」と表示された失敗ログ。新しいCodexセッションでやり直す判断まで含めた画面]
最初に読み込んでいた browser-client.mjs の場所が、信頼済みのマーケットプレイス側ではなく、キャッシュ側だった。
失敗したパスはこれ。
<Codex home>\plugins\cache\openai-bundled\chrome\0.1.7\scripts\browser-client.mjs
動いたパスはこっち。
<Codex home>\.tmp\bundled-marketplaces\openai-bundled\plugins\chrome\scripts\browser-client.mjs
この信頼済みパスに切り替えたら、Chromeのタブ一覧を取得できた。
英語で検索したら、AIは自力で解決してくれた。

Chrome拡張でもない。
Native Hostでもない。
Codex側で読み込んだ browser-client の経路が、信頼済み扱いになっていなかった。
ここで面白いのは、失敗そのものがEvidence Packになることだ。
「できませんでした」で終わると弱い。
でも、こう残すと次に進める。
確認できたこと:
- Chromeは起動している
- Codex Chrome Extensionはインストール済み
- Extensionは有効
- Native Host manifestは正常
- note.com / editor.note.com は許可済み
詰まったこと:
- 最初に読み込んだ browser-client がキャッシュ側だった
- そのため native pipe bridge が信頼されず、Codex Chromeでタブ操作できなかった
復旧方法:
1. Chrome拡張、Native Host、許可ドメインの診断を先に通す
2. `browser-client.mjs` は信頼済みマーケットプレイス側から読む
3. `browser.user.openTabs()` でタブ一覧が取れることを確認する
4. note編集画面を開き、編集作業とスクショをEvidence Packとして残す
このログがあると、次の自分も迷わない。
別のAIに引き継ぐ時も、「Chrome設定から見直して」ではなく、「設定は通っている。見るべきは browser-client の読み込み経路」と渡せる。
AI運用で大事なのは、成功手順だけではない。
AIは頭こそ詰まったときにAIは壊れているし疑う重要性は昔から変わっていないと実感する
どこまで確認済みで、どこから詰まったかを残すこと。
これも、Evidence Packのかなり実用的な使い方だと思う。
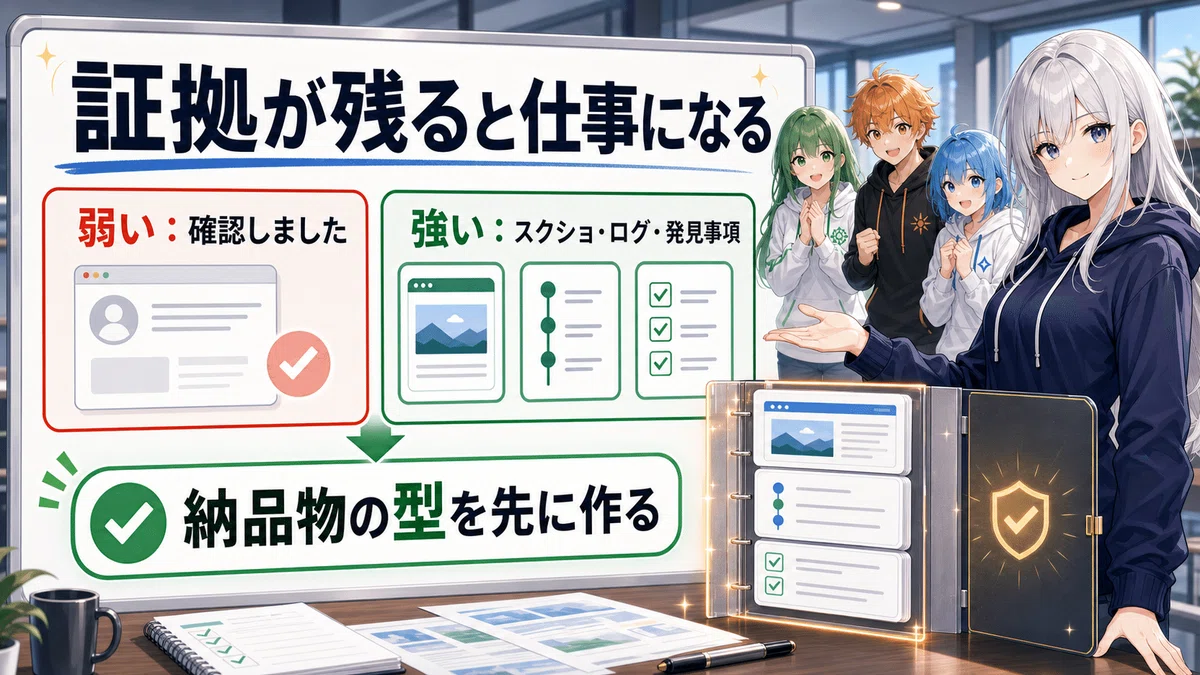
💡 Evidence Packは3点セットで作る
ここで使うのが、Evidence Packという考え方。
日本語で言うなら「証拠束」。
ブラウザ作業の結果を、次の3つにまとめて渡す。
スクショ
操作ログ
発見事項
スクショは「何を見たか」の証拠。
操作ログは「何をしたか」の証拠。
発見事項は「何が分かったか」の証拠。
この3つがあると、報告の質がかなり変わる。
弱い報告:
確認しました。問題なさそうです。
強い報告:
5月11日 21:10に対象ページを確認。設定Aは有効、設定Bは未設定。該当画面のスクショ3枚と、確認手順を添付。次に直すなら設定Bです。
これなら、依頼者が検品できる。
次の作業者も引き継げる。
自分もあとで見返せる。
AI代行の価値は、作業そのものより「あとで判断できる形で残ること」にある。
🏭 v0.129.0で見えた工場化の方向
Codex v0.129.0周辺の更新を見ていて、方向性がかなりはっきりしてきた。
細かい機能の話ではなく、全体の流れとして、
「一人が頑張って使うツール」から「チームや手順として回す仕組み」へ寄っている。
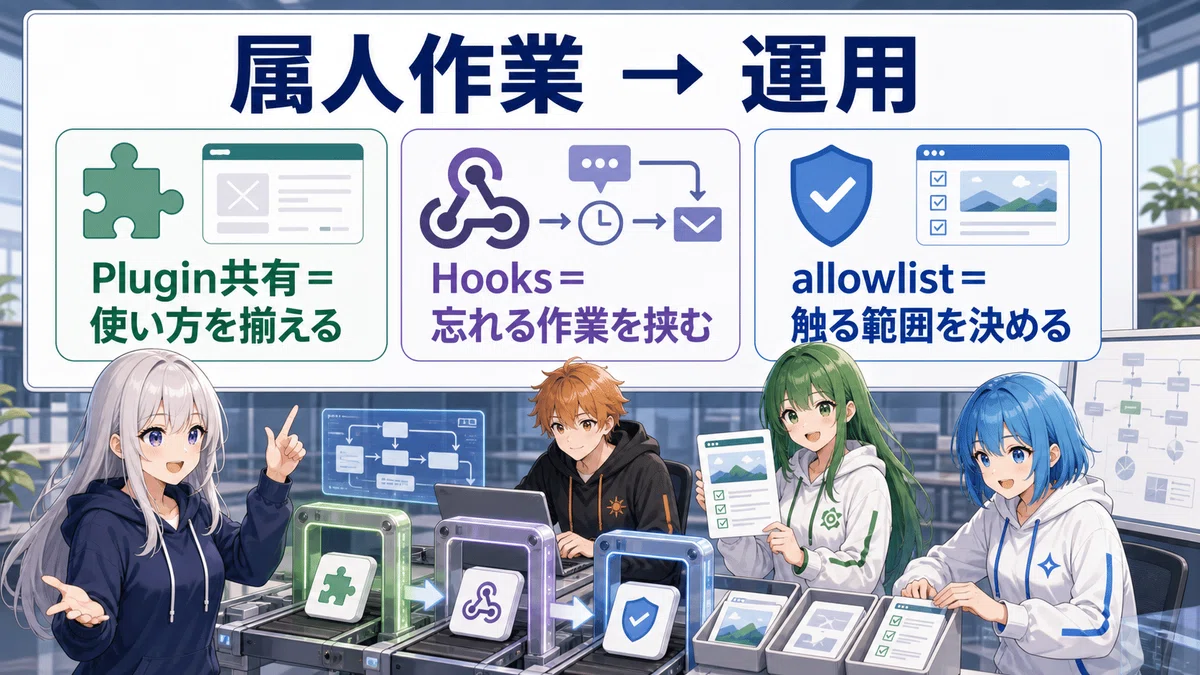
特に気になったのはこの3つ。
Plugin sharing
Hooks
Chrome extension allowlist
Plugin sharingは、使い方や部品を個人の環境に閉じ込めない方向。
Hooksは、作業の前後に決まった処理を挟める方向。
Chrome extension allowlistは、ブラウザ作業で「どのサイトを許可するか」を先に決める方向。
全部に共通しているのは、毎回の判断を減らすことだ。

毎回「この作業の後にログ残したっけ?」と考えない。
毎回「このサイトを開いていいんだっけ?」と迷わない。
毎回「誰の環境にだけ設定があるんだっけ?」で止まらない。
これが工場化だと思う。
大げさな自動化ではなく、属人作業を少しずつ手順に変えていくこと。
Evidence Packは、その流れにかなり相性がいい。
ブラウザ作業をしたら、証拠を残す。
証拠が残ったら、次の判断ができる。
判断が残ったら、次の自動化候補が見える。
ここまで来ると、単発の作業がナレッジになる。
🧩 自分が実際に使っているmd
今回の核にしているmdはこれ。
intel_outbox/codex-mastery/templates/offer-pack/
codex_chrome_evidence_pack.md
中身はかなりシンプル。
依頼時にもらう情報
実施プロトコル
納品物の型
10問チェック
ただ、この「シンプルな型」が大事だった。
AIにブラウザ作業を頼む時、いきなり「このページ見て判断して」だとブレる。
でも、先に型があると違う。
「スクショを残して」
「操作ログを書いて」
「発見事項を3〜10点で出して」
「個人情報はマスクして」
ここまで決めておくと、AIの出力が“報告っぽい文章”ではなく、“納品物っぽい束”になる。
プロンプトを上手くする前に、返ってくる成果物の型を決める。
ここは、最近かなり確信に変わってきた。
🔒 メンバーシップ限定で出すもの

無料部分では、考え方を出した。

ここから先は、実際に使える形を出す。
Evidence Packテンプレ全文
この公開記事のmdをEvidence Packに入れて検品した実例
依頼時にもらう情報の型
Chrome拡張+Codexで動かす時の実施プロトコル
納品物チェックリスト
note運用で使えるブラウザ業務リスト
note-pipelineに組み込むなら、どこをHook化するか
「ブラウザ作業をAIに任せたい」ではなく、
「ブラウザ作業を、検品できる納品物として返す」
そしてこの機能のぶっちゃけた感想…。
実例: この公開記事のmdをEvidence Packに入れてみた
この記事を公開したあと、実際にこのmdをEvidence Packの型に入れて検品してみた。
入力にしたのはこの2つ。
公開記事URL:
https://note.com/ai_arai_ally/n/n2b1f963880af
元md:
output/drafts/20260511-codex-chrome-evidence-pack-factory/note_article_final.md
やったことは、記事を「作品」として読むのではなく、納品物としてチェックすること。
公開URLが記録に残っているか
無料部分とメンバー限定部分の境目が残っているか
画像が本文の意図に沿って入っているか
mdテンプレが、読者が再利用できる粒度になっているか
次に改善すべき点が、作業ログとして残るか
結果、Evidence Packとしてはこう返せる形になった。
evidence_pack_20260512_article_md/
report.md
audit_log.csv
qa_results.json
ここで一番大きかったのは、公開後のズレを拾えたこと。
この公開記事のURLは n2b1f963880af だが、ローカルのpublish記録では一度「失敗ドラフト」として扱っていたIDだった。
普通なら、こういうズレは後から見失いやすい。
でもEvidence Packの型で見ると、
公開されたURLと、ローカル記録の状態が一致していない
という検品項目として拾える。
これは地味だけどかなり重要だと思った。
AIに作業させると、本文そのものよりも「どのURLが本番で、どのmdが元で、どこまで検品済みか」が曖昧になりやすい。
だから、Evidence Packはブラウザ操作だけでなく、記事制作そのものの検品ログにも使える。
今回のミニレポートはこう。
結論:
この記事は、Evidence Packの説明記事であると同時に、
記事制作フロー自体をEvidence Pack化する実例にもなる。
OK:
- 公開URLが確定している
- 元mdが残っている
- 画像8枚の参照が残っている
- メンバー限定の境目がmd上に残っている
- テンプレ全文とチェックリストが再利用できる
注意:
- 公開URLとpublish_recordの扱いがズレていた
- 公開画面だけではメンバー限定部分の全文検品はできない
- タイトルは公開時のものにローカルmdを合わせる必要があった
次アクション:
1. publish_recordを公開URLに合わせて補正する
2. この記事用のEvidence Pack実例ファイルを残す
3. 次回から公開後チェックをEvidence Pack化する
この使い方は、かなり応用がきく。
note記事なら、公開後に毎回これを残せる。
Zennなら、クロスポスト後の画像リンクやcanonical確認に使える。
メンバーシップなら、「有料部分に本当に現物があるか」の検品にも使える。
つまりEvidence Packは、クライアントワーク用の納品物である前に、自分のAI制作フローを壊さないための記録形式として使える。
Evidence Packテンプレ全文
目的:
ログイン必須のWeb業務を、再現可能・検品可能な形で納品し、継続運用や自動化に繋げる。
1. 依頼時にもらう情報
対象URL:
アカウント種別:
見えるはずの画面/権限:
目的:
成功条件:
期限:
最優先で確認したいこと:
触れてよい操作範囲:
- 閲覧のみ
- 設定変更OK
- 投稿OK
- 購入/送信/公開はNG
ここを曖昧にすると、AIは「それっぽく見に行く」だけになる。
特に大事なのは、成功条件と触れてよい操作範囲。
ログイン済み画面を扱う時は、ここを最初に固定する。
2. 実施プロトコル
事前:
- 作業ログを残す前提で開始する
- 時刻、ページURL、操作を短文で記録する
- 重要画面は必ずスクショを残す
- before / after のどちらが必要か決める
実施:
- 操作は小さく確実に進める
- 1アクションごとに状態を確認する
- 迷ったら推測で進めず、証拠を残す
- 権限外の操作はしない
事後:
- 変更した場合は差分を書く
- 再現手順を書く
- ロールバック手順を書く
- 次の自動化候補を最大3つに絞る
3. 納品物の型
Evidence Packは、最低この4つで返す。
1. 重要画面スクショ
- 5〜15枚
- before / after
- エラー、警告、設定画面
2. 操作ログ
- 時系列
- URL付き
- 何を見て、何を押して、何が起きたか
3. 重要テキスト抜粋
- UI文言
- エラー
- 警告
- 数値
4. 発見事項
- 3〜10点
- 重要度つき
- 次アクションつき
4. 納品前10問チェック
1. URL・時刻・対象範囲がログに残っているか
2. 成功条件に対してOK/NGが明確か
3. 重要な主張に対応するスクショがあるか
4. 推測と観測を混同していないか
5. 変更した場合、差分とロールバックがあるか
6. 依頼者が再現できる言葉で手順が書かれているか
7. 依頼範囲外の操作をしていないか
8. 個人情報や機密がマスクされているか
9. 次アクションが1〜3個に絞られているか
10. この納品物だけで次の発注判断ができるか
5. note運用で使えるブラウザ業務
自分のnote運用なら、まずこのあたりに使える。
note:
- 下書き保存後の画像数チェック
- 太字、blockquote、区切り線の反映確認
- 有料ラインの位置確認
- 関連記事URLの埋め込み確認
Zenn:
- クロスポスト後の表示確認
- 画像リンク切れ確認
- canonical / 参照リンク確認
Gumroad / メンバーシップ:
- 商品説明の表示確認
- 価格、初月無料、導線の確認
- 購入前ページの見え方チェック
Search Console:
- 公開後のインデックス確認
- クエリやクリックの定点観測
全部を最初から自動化しなくていい。
まずは、Evidence Packとして残す。
残ったもののうち、毎回同じ作業だけをHookやスクリプトに寄せる。
この順番がかなり現実的だと思う。
6. note-pipelineに組み込むなら
最初にHook化したいのはこの3つ。
publish前:
- publish_lintを通す
- 画像参照の存在を確認する
- 有料ラインが残っているか確認する
publish後:
- note下書きURLを記録する
- HANDOFFに1行残す
- Zennクロスポスト対象なら変換候補に入れる
画像生成後:
- output/gpt_images配下に保存する
- 固定画像置き場へミラーする
- 使った画像と没画像を分ける
Hookは「すごい自動化」ではない。
忘れると痛い作業を、毎回同じ場所に挟む仕組みだ。
Evidence Packも同じ。
あとで見返したい証拠を、毎回同じ型で残す。
この2つは相性がいい。
ぶっちゃけた感想
このスクショをとって、AIにやらせるのは凄い丁寧な作業で時間効率が悪く感じる。なれてきたら、CodexのコードやClaude codeでコーディングを勉強してどんどん早く回せるほうがいいと思う。
昼休みや寝てるときに安心してAIに任せたい初心者向けにこの機能は進められると思います…。
🌟 まとめ
ログイン必須のWeb業務は、AIに任せられない領域に見えやすい。
でも、本当に難しいのは「ブラウザを触ること」ではなく、
触った結果を、依頼者が検品できる形にすることだと思う。
スクショ。
操作ログ。
発見事項。
この3つが残るだけで、AIのブラウザ作業は一気に仕事っぽくなる。
そして、Codex周りの更新は明らかに「一回の作業」より「継続して回る運用」へ向かっている。
だから今やるなら、プロンプトを増やすより先に、
納品物の型を作る。
ここから始めるのが、一番強い。
参考リンク:
Chrome plugin mention is selectable but chrome@openai-bundled is not exposed in active tools
Codex Desktop Chrome plugin hangs during extension backend bootstrap/openTabs on Windows
#AI #Codex #Chrome拡張 #AI代行 #note #自動化 #メンバーシップ #EvidencePack


