Bootstrapping Post-training Signals for Open-ended Tasks via Rubric-based Self-play on Pre-training Text
arXiv cs.CL / 4/23/2026
📰 NewsModels & Research
Key Points
- The paper proposes POP, a self-play post-training framework that extends LLM self-play beyond verifiable tasks like math and coding to open-ended tasks.
- POP uses the same LLM to generate task-specific evaluation rubrics and corresponding input-output examples, then applies the rubric to score model outputs for training.
- To make the self-play signal more reliable, the method leverages a content-rich pretraining corpus to reduce reward hacking via a generation-verification gap and to prevent mode collapse.
- Experiments on Qwen-2.5-7B show POP improves performance for both pretrained and instruction-tuned variants across diverse domains, including long-form Healthcare QA and creative writing.
- The approach targets the data bottleneck in post-training by reducing reliance on costly human-written pairs or expensive proprietary labeling/reward models.
Related Articles
Why don't Automatic speech Recognition models use prompting? [D]
Reddit r/MachineLearning

CoTracker3: Simpler and Better Point Tracking by Pseudo-Labelling Real Videos
Dev.to

My AI Agent Over-Corrected Itself — So I Built Metabolic Regulation
Dev.to
Building Agent Arena: Using Valkey as the Nervous System for Multi-Agent AI
Dev.to
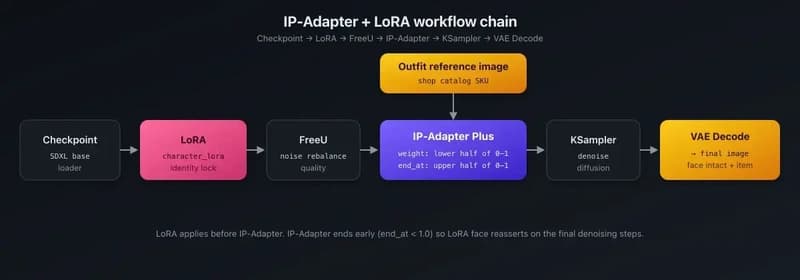
IP-Adapter + LoRA for product catalog rendering — putting shop items on AI characters
Dev.to