Drifting Fields are not Conservative
arXiv cs.LG / 4/9/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- The paper studies drifting generative models that move samples toward the data distribution using a vector-valued drift field, and tests whether this corresponds to optimizing a scalar loss.
- It finds that, in general, drift fields are not conservative and therefore cannot be expressed as the gradient of a scalar potential.
- The work identifies position-dependent normalization as the main source of the non-conservatism.
- It shows that the Gaussian kernel is a special case where the normalization does not break conservatism, making the drift field exactly a gradient of a scalar function.
- The authors propose an alternative “sharp kernel” normalization that restores conservatism for any radial kernel, and conclude that although drift-field matching can be more general than loss minimization, practical gains are minimal, so loss-based training is preferable.
Related Articles

Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to

Could it be that this take is not too far fetched?
Reddit r/LocalLLaMA

npm audit Is Broken — Here's the Claude Code Skill I Built to Fix It
Dev.to

Meta Launches Muse Spark: A New AI Model for Everyday Use
Dev.to
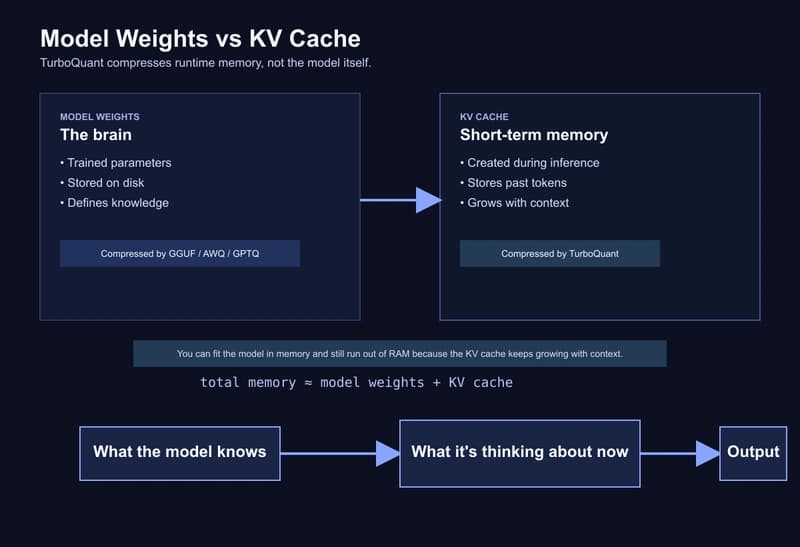
TurboQuant on a MacBook: building a one-command local stack with Ollama, MLX, and an automatic routing proxy
Dev.to