GUIDE: Interpretable GUI Agent Evaluation via Hierarchical Diagnosis
arXiv cs.AI / 4/7/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- The paper argues that evaluating GUI agents is difficult because their long, visually grounded, open-ended trajectories require judgments that are both accurate and interpretable, not just holistic binary scores.
- It introduces GUIDE, a hierarchical evaluation framework that breaks a full trajectory into semantically coherent subtasks, diagnoses each subtask in context, and then aggregates sub-diagnostics into an overall task verdict.
- GUIDE’s subtask-level diagnosis produces structured error analyses and corrective recommendations, aiming to pinpoint where and why an agent fails.
- The authors validate GUIDE on three benchmarks (industrial e-commerce, AGENTREWARDBENCH, and AndroidBench) and report up to a 5.35 percentage-point accuracy improvement over the strongest baseline.
- By evaluating bounded subtask segments rather than entire long trajectories, GUIDE is designed to reduce context overload that harms performance in existing evaluators as tasks get more complex.
Related Articles

Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to

Could it be that this take is not too far fetched?
Reddit r/LocalLLaMA

npm audit Is Broken — Here's the Claude Code Skill I Built to Fix It
Dev.to

Meta Launches Muse Spark: A New AI Model for Everyday Use
Dev.to
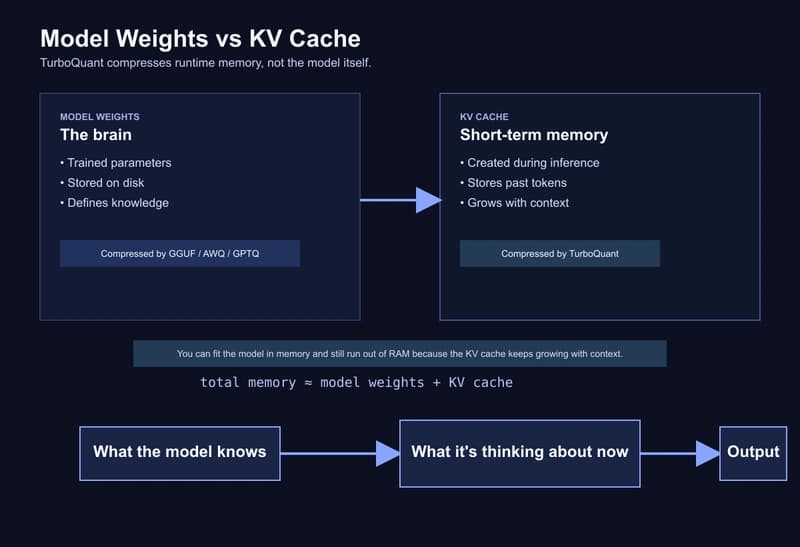
TurboQuant on a MacBook: building a one-command local stack with Ollama, MLX, and an automatic routing proxy
Dev.to