Exploiting LLM-as-a-Judge Disposition on Free Text Legal QA via Prompt Optimization
arXiv cs.CL / 4/23/2026
📰 NewsModels & Research
Key Points
- The paper studies how prompt design and the choice of “judge” LLM affect LLM-as-a-Judge evaluations for free-text legal QA on the LEXam benchmark.
- Using the ProTeGi method with feedback from two judges (Qwen3-32B and DeepSeek-V3) across four task models, automatic prompt optimization beats human-centered baseline prompts consistently.
- Lenient judge feedback produces larger, more consistent improvements than strict judge feedback, and prompts optimized with lenient feedback transfer better to strict judges.
- The analysis suggests lenient judges give more permissive feedback that yields broadly applicable prompts, while strict judges drive restrictive, judge-specific overfitting.
- The authors conclude that algorithmically optimizing prompts on training data can outperform manual prompt design, and that judge disposition critically influences generalizability, with code and optimized prompts released on GitHub.
Related Articles
Why don't Automatic speech Recognition models use prompting? [D]
Reddit r/MachineLearning

CoTracker3: Simpler and Better Point Tracking by Pseudo-Labelling Real Videos
Dev.to

My AI Agent Over-Corrected Itself — So I Built Metabolic Regulation
Dev.to
Building Agent Arena: Using Valkey as the Nervous System for Multi-Agent AI
Dev.to
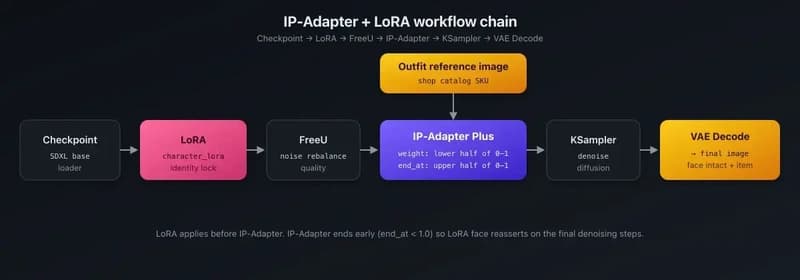
IP-Adapter + LoRA for product catalog rendering — putting shop items on AI characters
Dev.to