[link] [comments]
LongCat-AudioDiT: High-Fidelity Diffusion Text-to-Speech in the Waveform Latent Space
Reddit r/LocalLLaMA / 3/31/2026
📰 NewsSignals & Early TrendsModels & Research
Key Points
- Meituan LongCatが、Waveformの潜在空間で高忠実度な拡散ベースText-to-Speechを行うモデル「LongCat-AudioDiT」を公開したと紹介されています。
- 公開先としてHugging Face(LongCat-AudioDiT-3.5B)とGitHub(LongCat-AudioDiT)が案内されています。
- Waveform潜在空間で動作する拡散TTSというアプローチにより、音声生成の品質(高忠実度)を狙う点が主眼です。
- リリース情報は告知リンク(X)経由で共有され、コミュニティ内でも注目トピックとして扱われています。
💡 Insights using this article
This article is featured in our daily AI news digest — key takeaways and action items at a glance.
Related Articles

Black Hat Asia
AI Business
Von Hammerstein’s Ghost: What a Prussian General’s Officer Typology Can Teach Us About AI Misalignment
Reddit r/artificial

Privacy-Preserving Active Learning for autonomous urban air mobility routing under real-time policy constraints
Dev.to
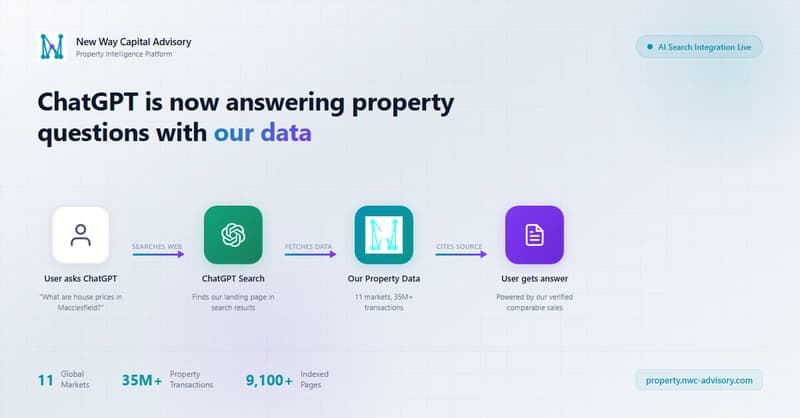
We caught ChatGPT answering property questions with our data -- here's the nginx log proof
Dev.to

15% of Americans say they’d be willing to work for an AI boss
TechCrunch