Unsupervised Anomaly Detection in Process-Complex Industrial Time Series: A Real-World Case Study
arXiv cs.LG / 4/16/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- The paper argues that real industrial time-series are more complex than benchmark datasets because of heterogeneous, multi-stage process dynamics that change across operation modes.
- It introduces an empirical study using a dataset collected from fully operational industrial machinery, designed to reflect process-induced variability.
- Model evaluations compare a classical Isolation Forest baseline against several autoencoder architectures, finding Isolation Forest insufficient for the non-periodic, multi-scale behavior.
- Among autoencoders, temporal convolutional autoencoders show the most robust anomaly detection performance, while recurrent and variational autoencoders are effective but demand more careful hyperparameter tuning.
Related Articles
The AI Hype Cycle Is Lying to You About What to Learn
Dev.to
Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to

Inside NVIDIA’s $2B Marvell Deal: What NVLink Fusion Means for AI Ethernet Fabrics
Dev.to
Automating Your Literature Review: From PDFs to Data with AI
Dev.to
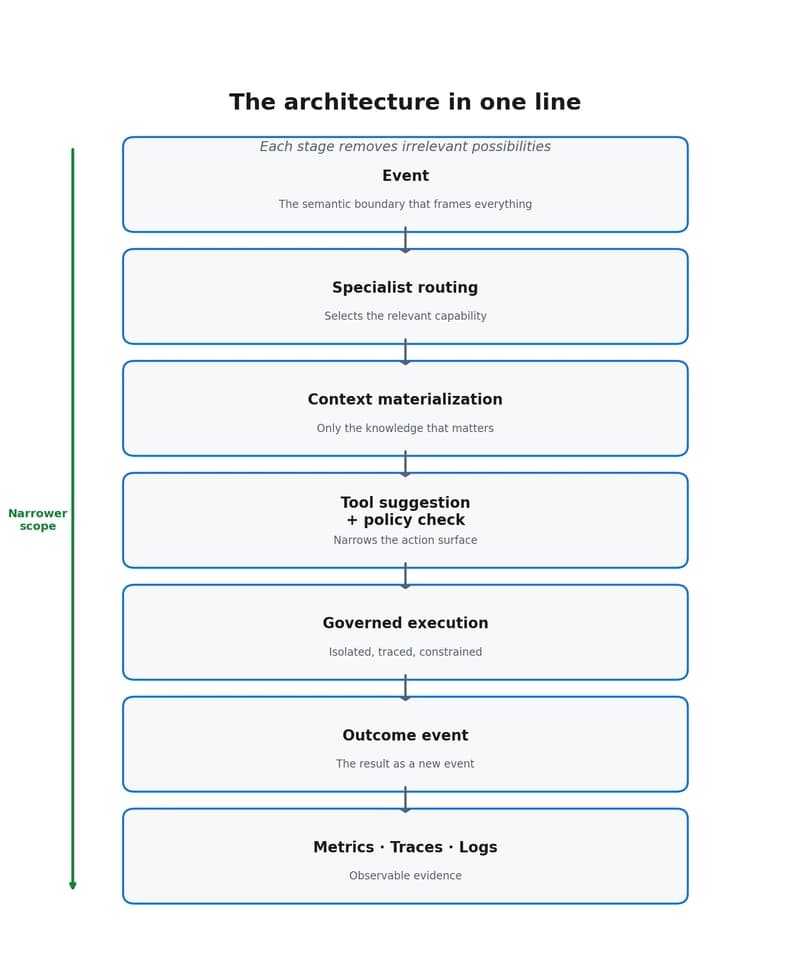
Why event-driven agents reduce scope, cost, and decision dispersion
Dev.to