SplitFT: An Adaptive Federated Split Learning System For LLMs Fine-Tuning
arXiv cs.LG / 4/30/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- SplitFT proposes an adaptive federated split learning framework aimed at enabling privacy-preserving LLM fine-tuning under client computation and data heterogeneity.
- The system addresses key issues for LLMs by allowing each client to choose its own “cut layer” based on available resources and trained model performance.
- SplitFT reduces communication overhead by lowering the LoRA rank specifically in the cut layer during fine-tuning.
- It introduces a length-based Dirichlet method to partition training data across clients, and validates the approach through experiments on multiple common benchmarks.
- Results indicate SplitFT improves fine-tuning time efficiency and overall model performance compared with state-of-the-art methods for fine-tuning in federated settings.
Related Articles

Can AI Predict Pollution Before It Happens? The Smart Solution to an Old Problem
Dev.to
THE FIFTH TRANSMISSION: THE GRADIENT IS THE GOVERNMENT
Reddit r/artificial
Looking for feedback on OpenVidya: an open-source AI classroom layer for NCERT/CBSE [R]
Reddit r/MachineLearning
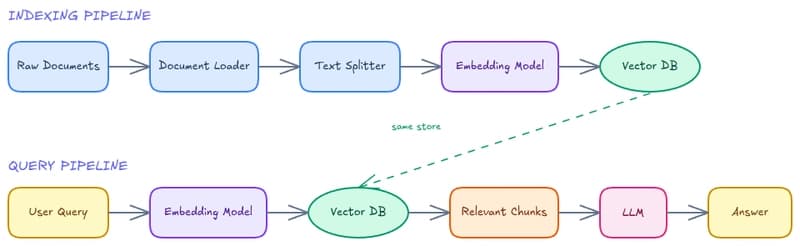
RAG Series (1): Why LLMs Need External Memory
Dev.to

One Open Source Project a Day (No. 54): Warp - The AI-Native Rust Terminal
Dev.to