How I Found $1,240/Month in Wasted LLM API Costs (And Built a Tool to Find Yours)
Dev.to / 4/5/2026
💬 OpinionDeveloper Stack & InfrastructureTools & Practical Usage
Key Points
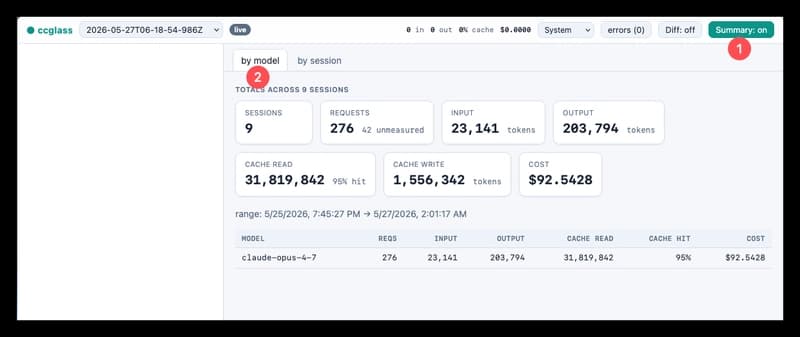
- The author reports identifying roughly $1,240/month in avoidable LLM API waste out of a $2,847 monthly spend, including retries, duplicates, and excessive context length.
- Major waste sources included 34% retry calls caused by JSON-in-markdown formatting, 85% duplicate classifier calls due to missing caching, and using GPT-4o for a simple yes/no classification instead of a cheaper model.
- The chatbot cost was driven by repeatedly sending full conversation history, with the author finding that truncating to the last few messages could save about $155/month.
- To measure and prevent similar problems, the author built an open-source Python CLI (“LLM Cost Profiler”) that wraps existing LLM clients and logs API calls to a local SQLite database.
- The profiling tool is designed to be non-invasive—logging is silent and intended not to affect the application if instrumentation fails, while supporting both OpenAI and Anthropic clients.
Continue reading this article on the original site.
Read original →💡 Insights using this article
This article is featured in our daily AI news digest — key takeaways and action items at a glance.