Context-Value-Action Architecture for Value-Driven Large Language Model Agents
arXiv cs.AI / 4/8/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- 既存のLLMエージェント評価は「LLM-as-a-judge」の自己参照バイアスにより見かけ上の性能が良く見えがちで、実データのグラウンドトゥルースで検証すると、推論を強めるほど価値の偏り(value polarization)が悪化することを示します。
- その問題に対し、Stimulus-Organism-Response(S-O-R)とSchwartzの基本的価値理論に基づく Context-Value-Action(CVA)アーキテクチャを提案し、行動生成と認知推論を分離します。
- CVAでは、自身による自己検証に頼らず、人間の真正データで学習した「Value Verifier」で動的な価値活性を明示的にモデリングして、価値偏向の抑制を狙います。
- CVAは、実世界の相互作用トレース110万件超を含むCVABenchでベースラインを大きく上回り、偏極の緩和と高い行動忠実性・解釈可能性の両立を報告しています。
Related Articles

Human-Aligned Decision Transformers for satellite anomaly response operations with ethical auditability baked in
Dev.to

That Smoking-Gun Video? It's Not Evidence. It's a Suspect.
Dev.to

AI Citation Registries and Website-Based Publishing Constraints
Dev.to
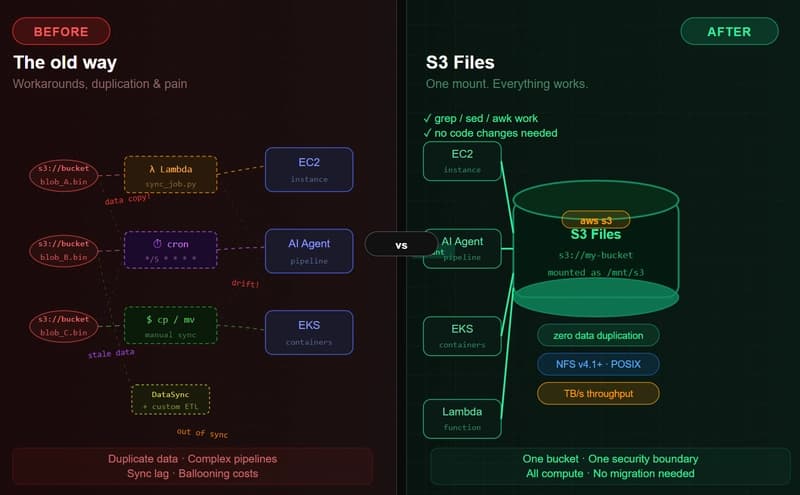
Amazon S3 Files: The End of the Object vs. File War (And Why It Matters in the AI Agent Era)
Dev.to
大模型价格战2025:谁在烧钱谁在赚?深度解析AI成本暴跌背后的生死博弈
Dev.to