Yesterday, my colleague Aqib Zakaria published an estimate of China’s supply-side compute capacity. By tallying chip shipments, smuggling reports, domestic production, and estimated Western cloud access, he arrived at ~2.7 million H100-equivalent GPUs.
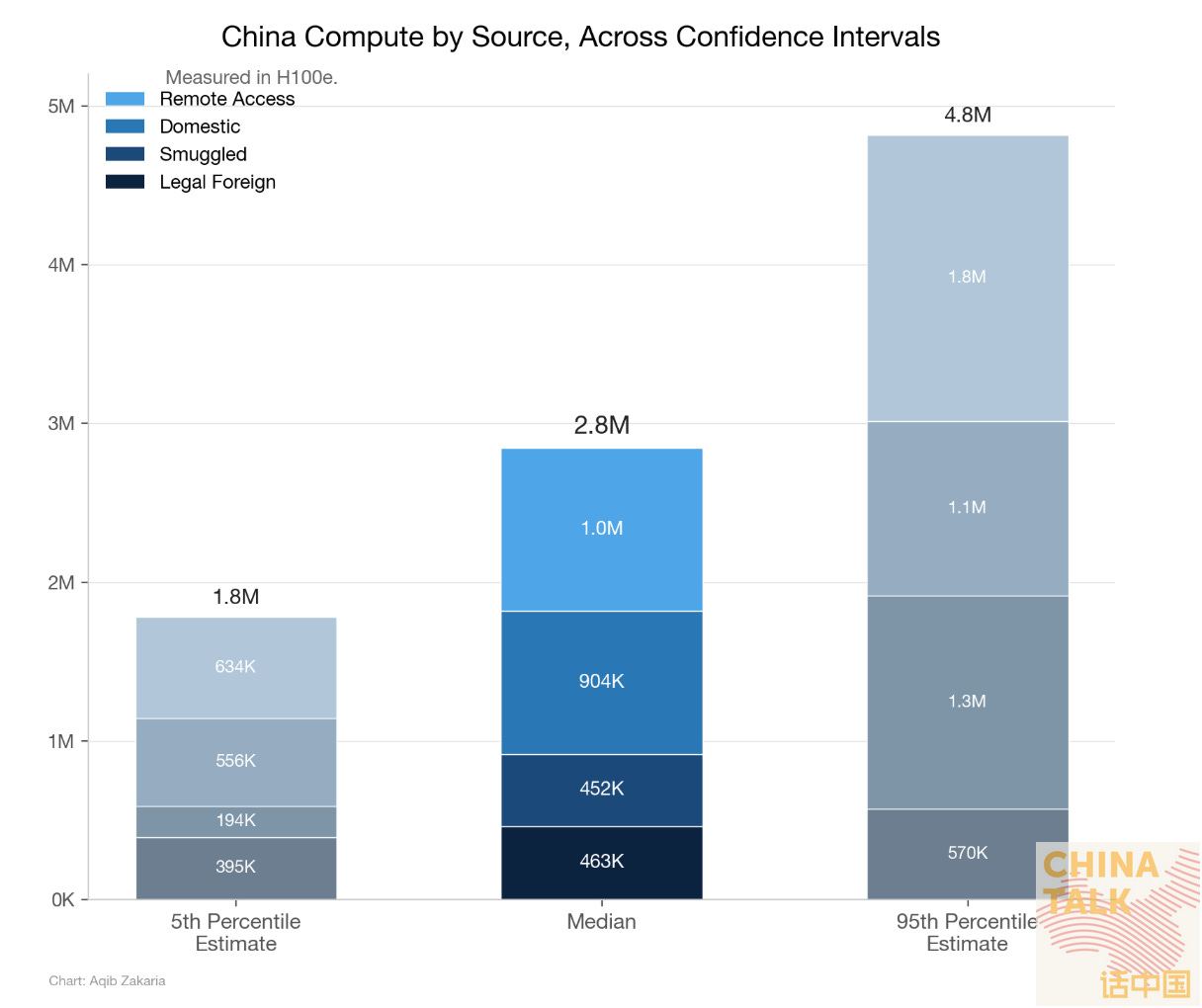
Today, I’ll try to approach the same question from the demand side. Rather than counting chips, I’m counting workloads to estimate how much compute China’s AI ecosystem needs. The demand-side approach is less precise than the supply-side (which means much more vibes-based guessing from me), but it offers a cross-check on whether the supply-side figure holds up.
The number I landed on is ~2.8 million H100e, which is nearly identical to Aqib’s estimate — though it’s entirely possible we’re both wrong in ways that happen to equalize. (We importantly did not share our numbers until after they were calculated!)
Why does this matter? For one, export controls on advanced chips are only as good as our understanding of what those chips actually enable. If policymakers are debating whether to tighten restrictions on H200s or close cloud compute loopholes, they should probably have a concrete sense of what China’s AI ecosystem actually demands. Looking at demand could further allow us to infer how much compute Chinese companies are renting from Western cloud service providers.
The rest of this piece walks through how I got my number. In a nutshell…
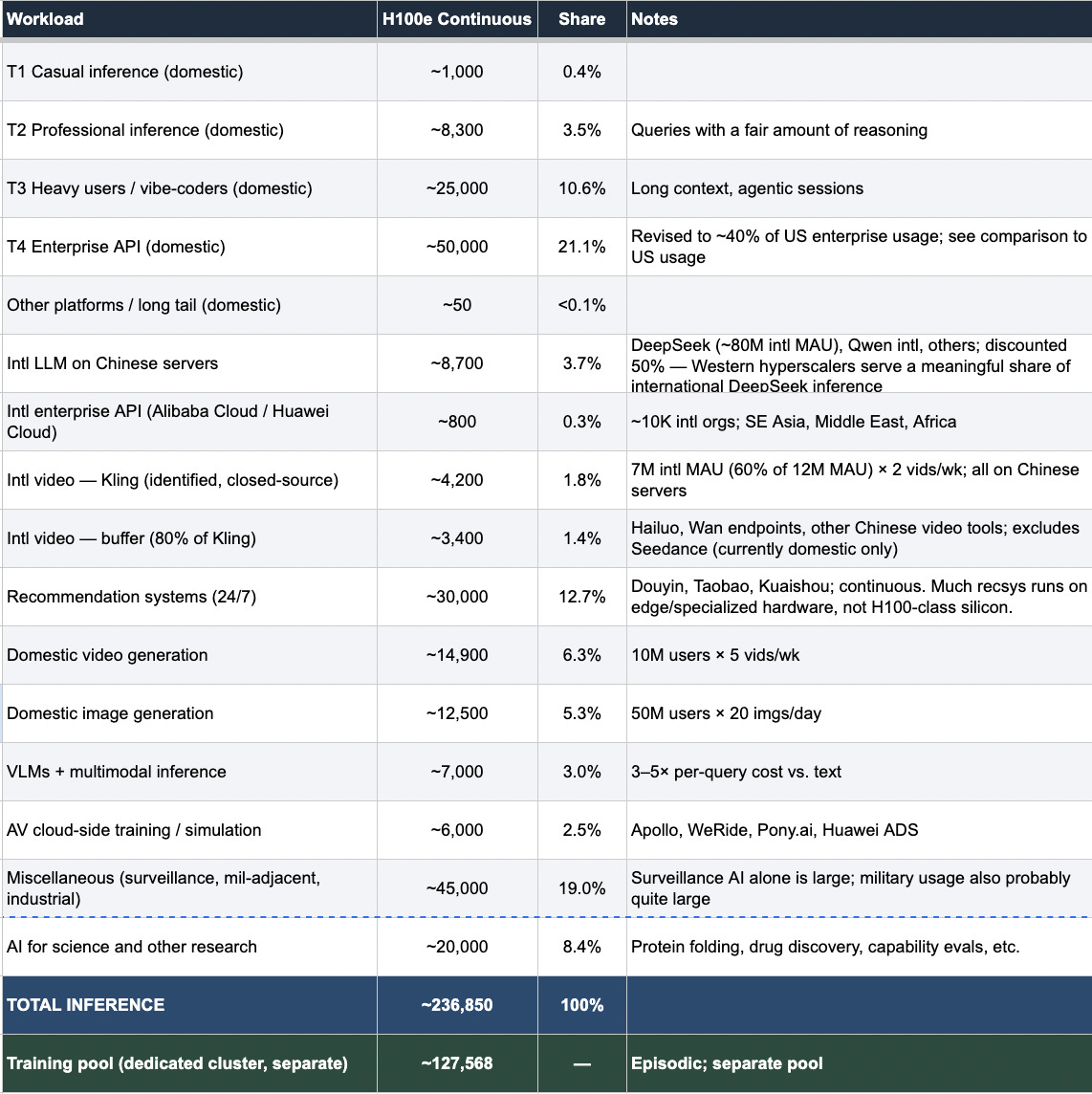
I estimate China’s AI infrastructure requires roughly 237,000 H100e running continuously to serve all inference workloads, such as chatbots, enterprise APIs, recommendation algorithms, video generation, surveillance, and more. Dividing by 55% — my central estimate for how intensively deployed inference chips are actually being used, based on various conversations and the common wisdom of the utilization discourse — gives a minimum inference installed base of ~431,000 H100e. Add a dedicated training cluster of ~128,000 H100e, used episodically for model training and research, and you get a minimum total installed base of around 558,000 H100e. Scale up to account for chips in reserve, in transit, between runs, or not yet fully online, and you reach 2.8 million at 20% whole-fleet utilization (one again based on conversations and the common range proposed by others). The training cluster is handled differently from inference: rather than dividing by the 55% inference utilization rate, it’s derived from total annual training compute divided by available chip-hours per year at a higher utilization rate (80%) due to the increased efficiency of usage during training.
I’ll walk through each step in more detail below. If you want the full methodology, the complete methodology is available here: China’s AI Compute Demand.
Working through this surfaced a few things I’d really like to know more about:
GPU utilization rates. Choosing the correct utilization percentage is the most important factor in the calculation, and quite contested. Based on multiple conversations with others and the common wisdom in the literature, I use 40-70% for how hard deployed inference chips are actually working, and 10-30% for the share of China’s total installed fleet operating at a given moment (central estimate: 20%). But a one-percentage-point shift in that whole-fleet figure moves the final number by roughly 186,000 H100e, so being accurate is incredibly important, and more research would be useful here.
Enterprise AI adoption. I estimate Chinese enterprise API usage at ~40% of US levels, which is the largest single inference category in my estimate. But neither Chinese nor Western AI companies disclose much about enterprise usage, which is frustrating.
Surveillance and recommendation algorithms. How much compute do surveillance and recommendation algorithms require, and is the quality of compute comparable to H100e or more simple workload processing?
Use cases I missed entirely. The limitation of demand-side analysis is that there’s always a category you didn’t think of.
Given the nature of this task, there are bound to be mistakes. But I hope this BOTEC serves as a framework for others to build on, poke holes in, and improve. If any of my numbers seem wildly off, reach out at nick@chinatalk.media or let me know in the comments.
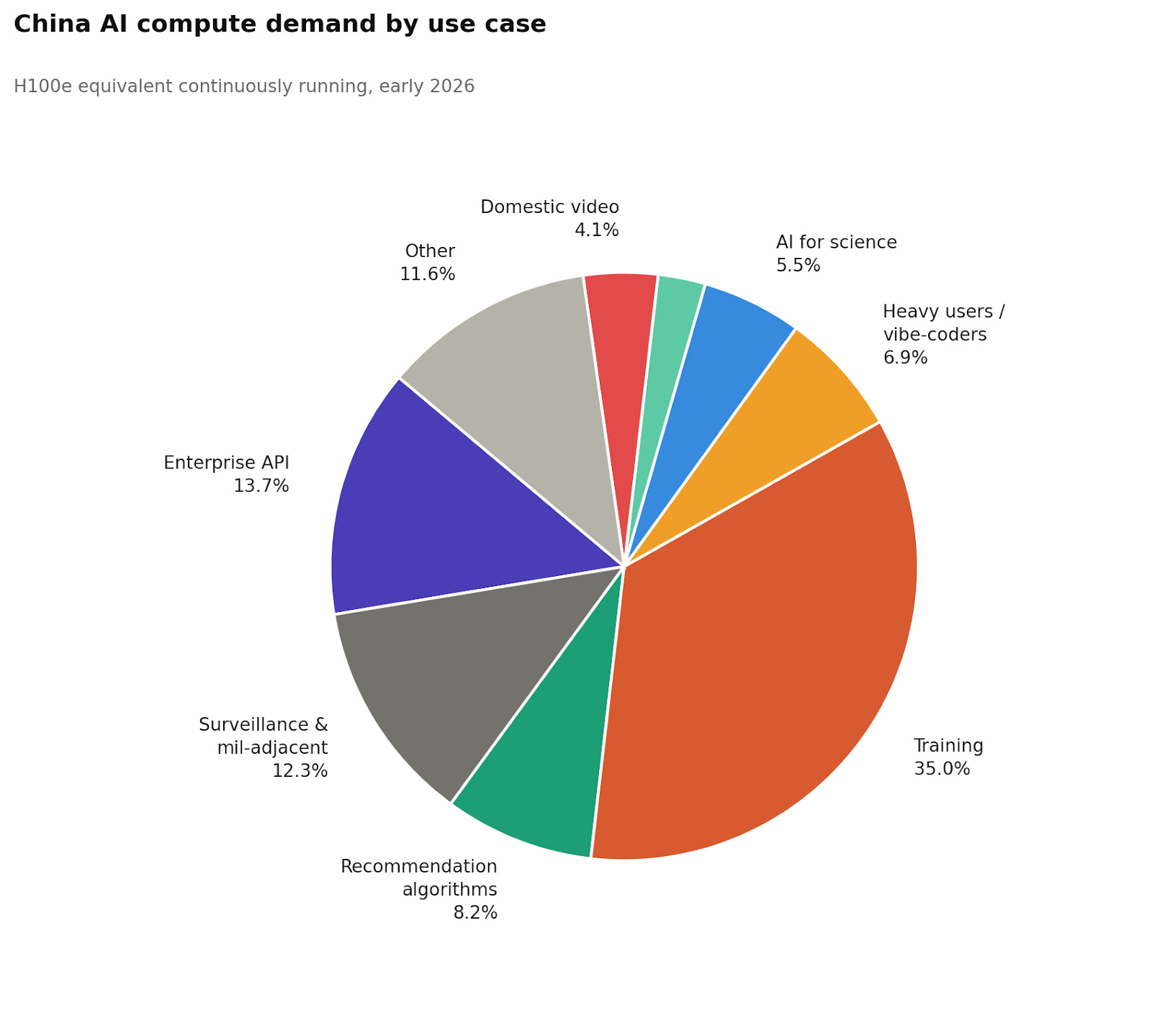
Compute by Use Case
The chart below breaks down China’s total AI compute demand by workload category.
Inference
We’ll get to the biggest category — training — in a moment. But first, here are a few inference findings I found interesting.
Casual users barely register, even at an enormous scale. CNNIC put China’s generative AI user base at a whopping 602 million as of December 2025, though that figure counts people who touched an AI-powered feature even once, so it’s more of a ceiling than a headcount. I believe a more useful working estimate is around 175-240 million regular active users generating meaningful compute load, with perhaps 300 million more in the casual tier: people who send a quick translation, tap a Doubao suggestion, or use an AI-powered filter. At roughly 1,000 tokens per day for a handful of short queries, that entire casual population runs to about 1,000 H100e, less than a percent of total inference demand. A single enterprise customer burning through a trillion tokens a year contributes more compute than tens of millions of casual daily users combined.
Enterprise API is the largest single inference category. I estimate domestic enterprise API at roughly 50,000 H100e, or about 21% of total inference. My biggest anchor here is OpenAI’s 2025 Enterprise AI Report [pdf], which discloses around 200 organizations exceeding 1 trillion tokens per year and roughly 9,000 exceeding 10 billion. Treating those at their floor values and converting at roughly 0.8 million tokens per H100e-hour gives a US enterprise inference floor of about 41,000 H100e from OpenAI alone, and that’s before adding Microsoft (15 million paid seats), Anthropic, Google, and internal deployments (which I essentially estimate according to a vibe of how successful I think their enterprise AI endeavors are in respect to OpenAI). China’s enterprise AI ecosystem is growing — Alibaba Cloud’s Tongyi platform reportedly reached 300,000 enterprise customers in 2024 — but is earlier-stage than the US and has fewer users. Enterprise software in China tends to have shallower AI integration, fewer automated workflows, lower per-organization token volumes, and less of the deep API-level embedding into business processes that drives compute at US firms like the ones in OpenAI’s enterprise cohort. I’ve therefore estimated China at roughly 40% of total US enterprise demand, which gives the 50,000 H100e figure, but I could see the number being anywhere from 20K-70K.
Surveillance, military-adjacent AI, recommendation algorithms, and unknown unknowns are collectively about 32% of total compute, but the hardest to pin down. For instance, recommendation systems (Douyin, Taobao, Kuaishou, Pinduoduo) run continuous real-time ranking inference 24/7, with little overnight demand drop. I’ve put these at 30,000 H100e, though much of this workload runs on edge silicon and specialized accelerators rather than H100-class hardware. The miscellaneous category — government surveillance AI, military-adjacent applications, industrial systems — I’ve put at 45,000 H100e. This is the number I’m least confident in. Real-time video reidentification across 600-700 million cameras is computationally intensive (backend aggregation and reidentification could require datacenter-class hardware even when edge NPUs handle the initial detection), and military AI usage leaves essentially no public trace. Of all the variables I could wildly over/under-predict, it is most likely one of these.
There are a couple of other variables I find interesting that you can see in the full breakdown, such as international users on Chinese servers (particularly DeepSeek’s large international user-base, which runs inference on Chinese hardware) and domestic and international video generation, which has grown into a meaningful compute category as platforms like Kling and Seedance scale up.
Training
Getting training compute onto the same footing as inference requires a different methodology. Inference is naturally expressed as chips running right now. Training is episodic; a cluster runs flat-out for weeks or months, then sits idle or is redirected towards inference between runs.
So instead of asking, “How many chips are active right now,” I asked, “How many GPU-hours does China consume on training per year, and how many dedicated chips does that imply?” My anchor is DeepSeek V3’s disclosed training run of 2.788 million H800-GPU-hours, adjusted upward by 1.5x for likely underreporting (I believe Chinese labs have strong incentives to minimize disclosed compute, since it reinforces the efficiency narrative and understates chip needs under export control scrutiny). From there, I built up tiers: five major labs (ByteDance, Alibaba, Baidu, Huawei, Tencent), each running multiple frontier LLM runs per year with overhead for ablations, RLHF, and failed experiments; ten mid-tier labs; five state and military-adjacent actors; plus video model training, image models, and AV simulation. Total annual training budget: roughly 298 million H100e-hours.
To convert that into a dedicated cluster size, I assumed training clusters are active for about four months per year at 80% utilization while running, yielding around 2,336 available hours per chip per year. Dividing 298 million by 2,336 gives roughly 128,000 H100e as the implied dedicated training pool. I also added ~50 million H100e-hours for research and experimentation beyond production training runs — architecture tests, scaling-law experiments, RL paradigm research — which pushes the total up from what a pure production-run accounting would suggest.

But not all compute is created equal. China’s training clusters require their best chips, like the H800s and smuggled Blackwells. This means China may have ample compute for inference at scale while still facing a meaningful constraint on how fast it can train the next generation of frontier models.
The Final Number
Now that we have inference and training accounted for, we need to bridge from “compute actively running” to “chips China actually has installed” — and that requires two separate utilization adjustments.
The first is installed base utilization: the share of deployed inference chips that are processing requests at any given moment. This isn’t 100% even for a busy cluster — there are overnight troughs when query volume drops, headroom kept for traffic spikes, downtime when logic is waiting for memory, and chips idling between requests. I use 55% as my central estimate, which sits at the midpoint of what I think is the plausible 40-70% range based on an aggregate of the existing literature and conversations with experts. At 55%, the 237,000 H100e running continuously implies an inference installed base of around 431,000 H100e. Add the training cluster of 128,000 H100e — which, as noted above, has utilization already baked into its calculation — and you get a minimum total installed base of roughly 558,000 H100e. This is the floor: the fewest chips China could have while still producing the workloads we observe.

The second is whole-fleet utilization: the share of every chip China has ever purchased that is doing anything at a given moment. This is structurally much lower than inference-serving utilization because it includes chips that are newly procured and still in transit, recently installed clusters still ramping up, training hardware sitting idle between runs, and reserve capacity held for future demand. China has been procuring AI hardware at an extraordinary pace, and a significant fraction of that hardware is, at any given snapshot, somewhere in the pipeline rather than serving workloads. I use 10-30% as the plausible range, with 20% as the central estimate.
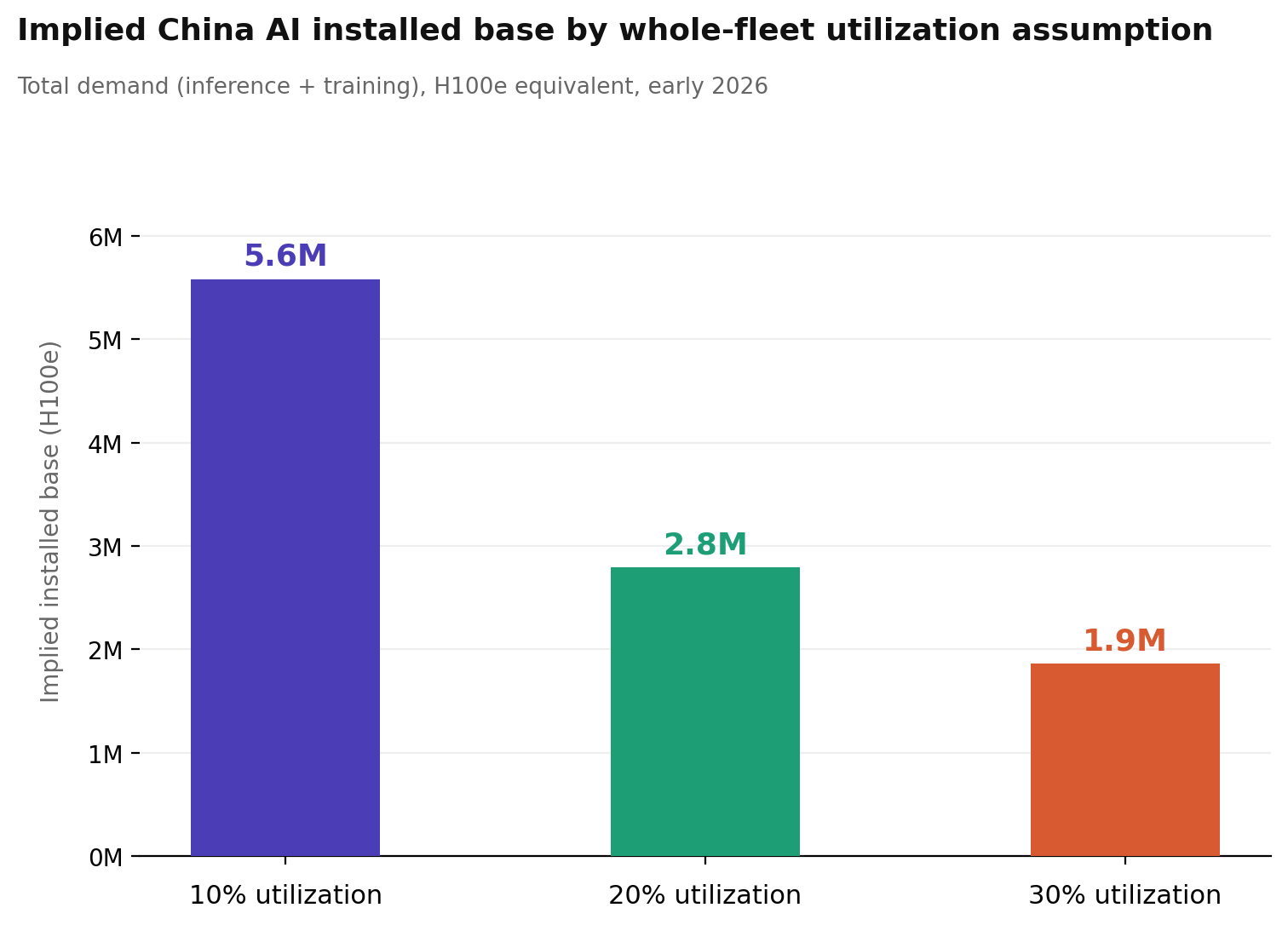
Dividing our median estimate for the minimum installed base of 558,000 H100e by 20% gives approximately 2.8 million H100e as the implied total Chinese AI chip stock. At the pessimistic end of the utilization range (10%), that number rises to 5.6 million; at the optimistic end (30%), it falls to 1.9 million. The sensitivity is dire, and it’s why utilization assumptions deserve more dedicated research.
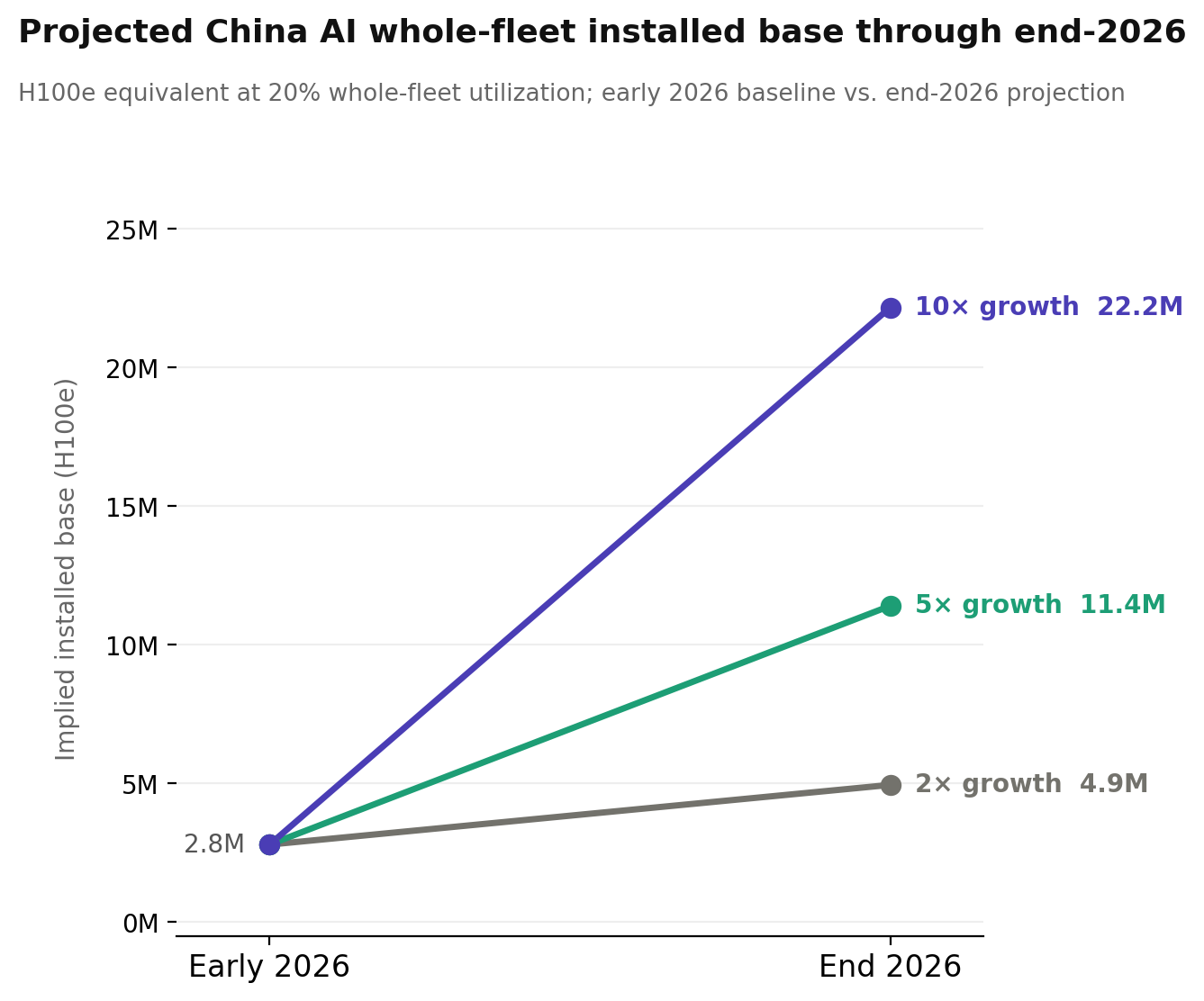
2026 growth scenarios
Global AI token consumption has grown at roughly 5× annually, and there’s no particular reason to think China is an exception. To get a sense of where things could be by the end of 2026, I’ve modeled three scenarios: 2×, 5×, and 10× growth applied to the inference pool, with the training cluster held flat as I am unsure if training will become more or less compute intensive in the future.
At 2× the implied whole-fleet installed base roughly doubles to ~5 million H100e; at 5× it reaches ~11 million; at 10× it climbs to ~22 million. For context, Epoch AI estimates current global high-end AI compute capacity at 20 million H100e, meaning the upper end of these scenarios implies China’s AI fleet alone approaching the scale of today’s entire global stock. That’s probably not happening by the end of 2026, but it illustrates why demand-side analysis matters: the numbers we’re dealing with today are large, but the trajectory is what’s really consequential for thinking about export controls, chip procurement, and the balance of AI capacity between the US and China.
Thinking about the future is ultimately what I hope this BOTEC is useful for. A supply-side count tells you what China has. A demand-side count tells you what China needs today, and what it will need in the coming years.
You can read the full methodology here: China’s AI Compute Demand

ChinaTalk is a reader-supported publication. To receive new posts and support our work, consider becoming a free or paid subscriber.