Good Rankings, Wrong Probabilities: A Calibration Audit of Multimodal Cancer Survival Models
arXiv cs.LG / 4/7/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- The paper argues that high discriminative performance (e.g., concordance index) of multimodal cancer survival models does not guarantee that predicted survival probabilities are statistically calibrated.
- It reports what it claims is the first systematic fold-level 1-calibration audit for multimodal whole-slide imaging (WSI) plus genomics survival architectures across multiple TCGA cancer datasets.
- In experiments using native discrete-time outputs, all tested models fail 1-calibration on most folds, with many fold-level tests rejecting correct calibration after multiple-testing correction.
- The study finds that gating-based fusion tends to yield better calibration than bilinear or concatenation fusion, and that post-hoc Platt scaling can improve calibration at the evaluated horizon without reducing discrimination.
- The authors conclude that calibration audits are necessary for clinical readiness and that using concordance index alone can be misleading.
Related Articles
Research with ChatGPT
Dev.to
Silicon Valley is quietly running on Chinese open source models and almost nobody is talking about it
Reddit r/LocalLLaMA

Why AI Product Quality Is Now an Evaluation Pipeline Problem, Not a Model Problem
Dev.to
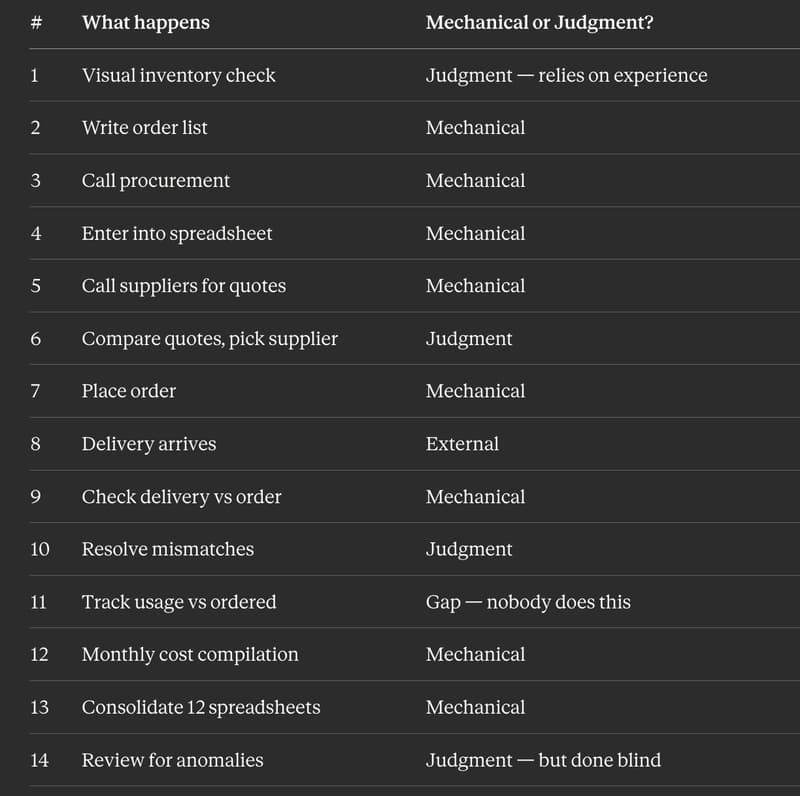
I Replaced 12 Kitchen Managers Guessing "How Much Chicken Do We Need" With 3 ML Models. Here's the Entire Architecture.
Dev.to

AI Model Router API - REST + MCP, Free Tier
Dev.to