AI(人工知能)時代にネットワークインフラはどうあるべきか。NTTドコモビジネスのエバンジェリストが最新の技術動向を解説する。第3回は、NTTグループが推進する次世代情報通信基盤「IOWN」の中核技術である「オールフォトニクス・ネットワーク(APN)」を取り上げる。APNを活用したGPU(画像処理半導体)分散型データセンターの実証成果も交え、AI時代のインフラ像を展望する。(編集部)
2022年11月にChatGPTが登場して以降、生成AI技術は驚異的な速度で進化を遂げ、企業のDX(デジタルトランスフォーメーション)や社会課題の解決に不可欠となっています。一方で、生成AIの急速な進展は既存の情報通信インフラに大きな負荷をかけています。
5G以降のモバイルネットワークの普及による通信量の増大に加え、生成AIの学習・推論プロセスで求められるトラフィックは従来のネットワーク設計の想定をはるかに超えています。高度化するサイバー攻撃への対策として機密データの保護も同時に求められ、これまでの電子処理を主体としたネットワーク機器の延長線上では遅延、消費電力、帯域の面で物理的な限界に近づきつつあります。
中でも深刻なのが「電力」と「場所」の問題です。生成AIの学習には大規模なGPUクラスターが必要となり、これを単一のデータセンターで処理しようとすれば莫大な受電容量と冷却設備、そして広大なスペースが必要となります。都市部では満床状態に近いデータセンターも多く、電力や立地の新たな確保が困難な状況にあります。
一方で、電力に余裕のある地方へデータセンターを分散させれば、今度は通信の遅延がボトルネックとなり、GPUの性能を使い切れないというジレンマに陥ります。この距離と遅延の壁を克服し、物理的に離れたリソースを論理的に統合するネットワーク基盤が求められています。
分散したGPUサーバーをIOWN APNであたかも1つに
こうした背景の下、NTTグループが推進しているのがIOWN構想です。その中核を成すのが、通信ネットワークの全区間を光波長で伝送するAPNです。
従来のネットワークでは光ファイバーで届いた信号をルーターやスイッチなどのノードでいったん電気信号に変換し、パケット処理を行ってから再度、光に変換して送り出していました。この光電変換のプロセスが遅延や消費電力の増大、通信の揺らぎ(ジッター)を生む主因となっていました。
これに対しIOWN APNでは、ネットワーク全体を光波長で占有し、電気信号への変換プロセスを極限まで排除することを目指しています。これにより、(1)超高速・大容量(2)超低遅延・低ジッター(3)低消費電力――の3つの価値を提供します。
(1)は波長単位の帯域専有で広帯域を確保します。(2)は中継区間における光電変換の最小化により、伝搬遅延に近い低遅延と、揺らぎの少ない通信を実現します。(3)は信号処理(特に電気処理)に伴う電力消費を大幅に削減します。
IOWN APNの真価が問われる最大のユースケースが分散データセンターにおけるGPUクラスターの連係です。生成AIの大規模言語モデル(LLM)の学習では数百~数千基のGPUを並列稼働させる必要があります。この際、ノードのデータを集約・配布するAll-Reduce通信などGPU間で頻繁にパラメーターの同期が行われるため、通信の遅延が学習効率に直結します。わずかな遅延やジッターが発生するだけで高価なGPUがデータ待ち状態(アイドルタイム)となり、投資対効果が著しく低下します。
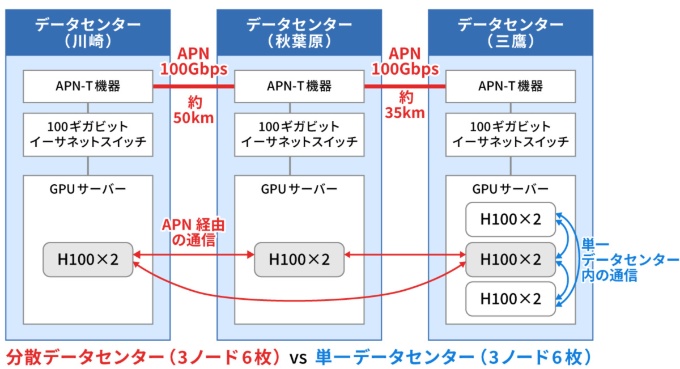
NTTドコモビジネスは三鷹と秋葉原のデータセンターをIOWN APNで接続し、それぞれに配置されたGPUサーバーをあたかも1つの巨大な計算リソースとして機能させる実証実験を2024年10月に行いました。米NVIDIA(エヌビディア)の大規模AIプラットフォーム「NeMo Framework」を用い、APN接続した環境と、一般的なインターネット回線を模した環境とで、LLMの学習速度を比較しました。
その結果、単一のデータセンターで学習させた場合の所要時間を1とした場合、インターネット経由の分散環境では遅延や帯域制限の影響で29倍の時間がかかりました。一方、IOWN APN接続では1.006倍という結果でした。物理的に離れた場所にGPUがあっても、単一のデータセンター内にあるのとほぼ同等の性能を発揮できることを確認できました。
これにより、都心のデータセンターと郊外のデータセンターをAPNで結べば、電力供給に余裕のある郊外のデータセンターにGPUを設置し、都心から遅延なく利用するといった構成が実現できます。東京・大阪といった都市間のバックアップにも適していると言えるでしょう。
2025年3月には秋葉原、三鷹、川崎の3拠点に拡張した実証実験も行いました。より複雑なネットワークトポロジーでも、NVIDIA NeMoを組み合わせた環境下で、NTTの大規模言語モデル「tsuzumi」(7Bモデル)の事前学習の動作検証に成功しています。
次のページ
独自RDMAツールで転送時間を最大6分の1にこの記事は有料会員限定です
