【神ツール】無料でこのレベルはやばい!LTX 2.3 × Whisper × Qwen 3.5 VL で、画像1枚からプロ級の「口パク動画」を全自動生成する方法

どうも皆さん!パイプユニッシュはいつも必要以上に入れちゃう派、 葉加瀬あい(ハカセアイ) です!
AIで動画を作るのは、もうすっかり当たり前の時代になりましたね。
でも、いざ喋る動画を作ろうとすると、こんな悩みにぶつかりませんか?

「口パクさせてみたけど、なんだかロボットみたいで不自然…」
「音声の長さに合わせて動画の尺を調整するのが、とにかく面倒くさい!」
わかります、その気持ち。せっかくいい画像ができても、動きや口の合わせ方で「AIっぽさ」が出ちゃうと、もったいないですよね。

今回は、そんな皆さんのお悩みを 完全にゼロ にする、 究極の時短・効率化ソリューション をご紹介します!
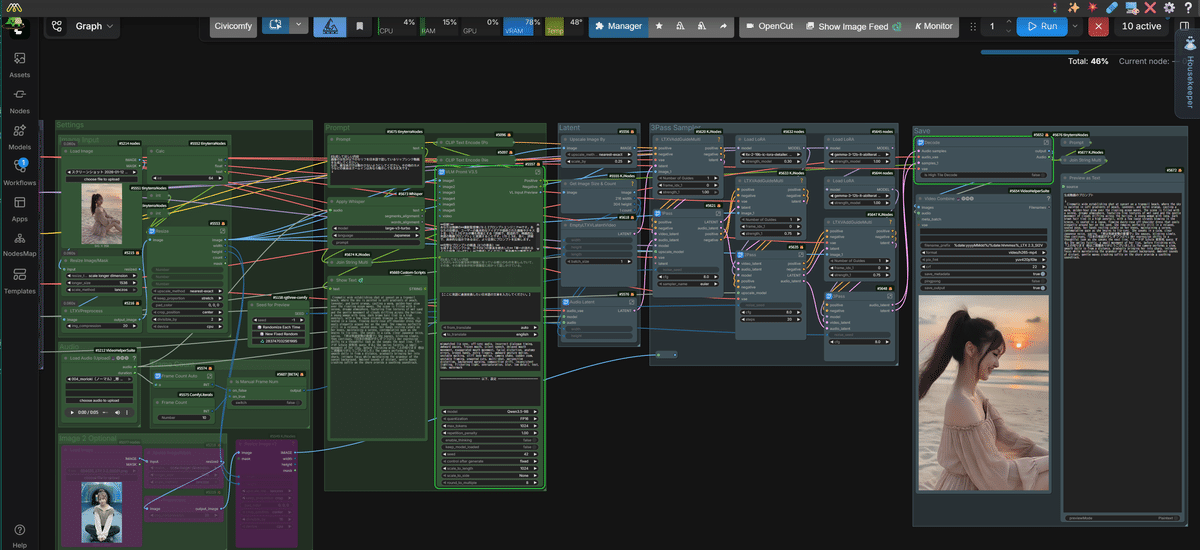
なんと、 「たった1枚の画像」と「音声ファイル」を入力するだけ で、
AIが音声の感情やリズムを読み取り、まるで本当に人間が喋っているかのような自然な口パク(リップシンク)と、表情・ジェスチャーを持った動画を自動生成してくれるんです!

ということで、今回お話しする内容はこんな感じです!
1. Whisper連携 :音声認識でセリフを注入し、リップシンク精度を爆上げする秘密
2. 完全自動フレーム計算 :もう面倒な長さ合わせは不要!
3. 3Passサンプラー :長時間の喋りでも顔が崩れない高画質化のテクニック
この記事を読めば、皆さんも今日から、生命力あふれるAIアバターのプロデューサーになれます!

動画版はこちらから
なお、Youtube では note の内容を動画に変換して公開しているので、まだの方は noteのフォロー や YouTubeのチャンネル登録 もお願いします!
https://www.youtube.com/%40AI-Hakase
また、今回の動画版はレンダリングが終了し次第、こちらにて公開していますので、動画派の方はぜひご覧ください!
それでは、本日もよろしくお願いします!
最強エンジン「LTX 2.3」の衝撃をおさらい
さて、今回の具体的なワークフロー解説に入る前に、その心臓部となる 『LTX 2.3(LTX-Video 2.3)』 の凄さについて、サクッとおさらいしておきましょう!

前回の記事では、この最新モデルが単なるマイナーアップデートではなく、 AI動画制作のパラダイムシフト であることをお話ししましたね。
https://note.com/ai_hakase/n/nc07ebd24eee0
まだ読んでいない方のために、その核となるポイントを3つだけ復習します!
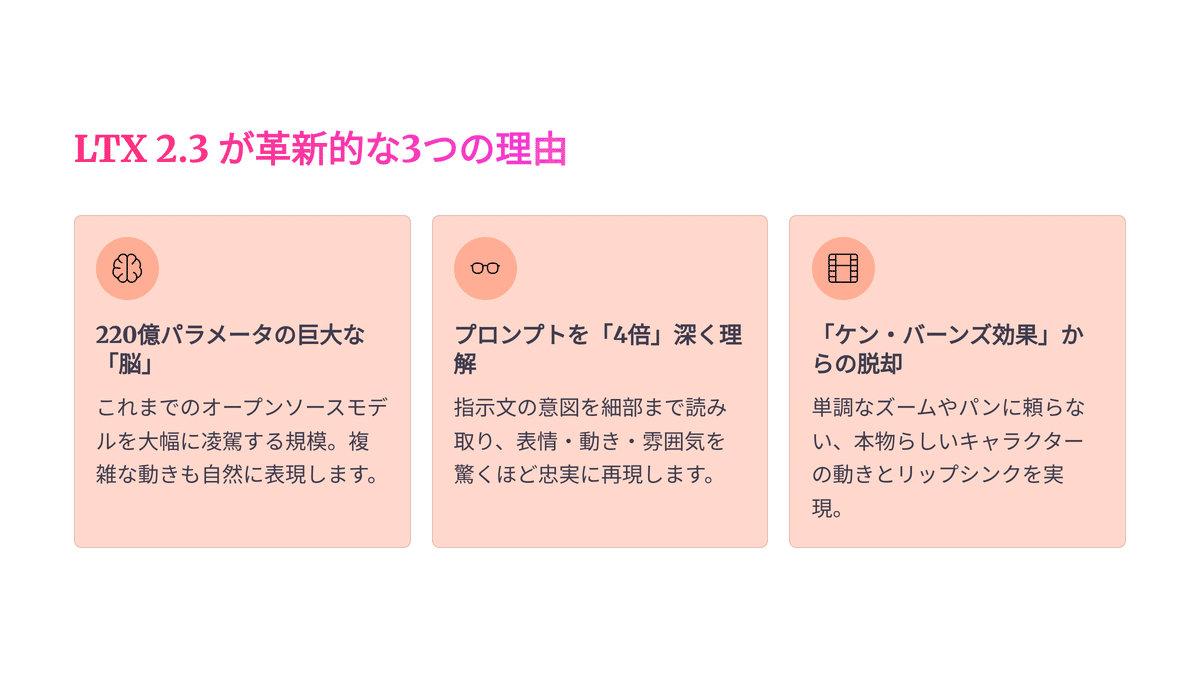
1. 220億パラメータの巨大な「脳」
オープンソース最高峰のパラメータ数を誇ることで、これまでは「溶けて」しまっていた微細な質感(例えばコップの結露や、風になびく髪の毛1本1本など)まで、実写レベルで描写できるようになりました。

2. プロンプトを「4倍」深く理解する
テキストコネクタの容量が大幅に拡張されたことで、私たちの詳細な指示を寸分狂わず映像に反映する「圧倒的な忠実度」を手に入れました。

AIが「言葉の裏の意図」まで汲み取ってくれるんです!

3. 「ケン・バーンズ効果」からの脱却
ただ写真をパン(横移動)したりズームさせたりするだけの擬似的な動きではなく、被写体そのものが意志を持って動く「本物のモーション」が実現されました。
一言で言えば、LTX 2.3は 「偶然に頼るツール」から「意図を形にするプロのエンジン」 へと進化したんです。
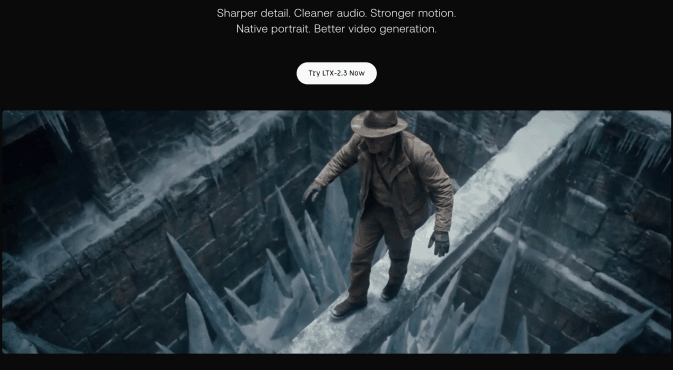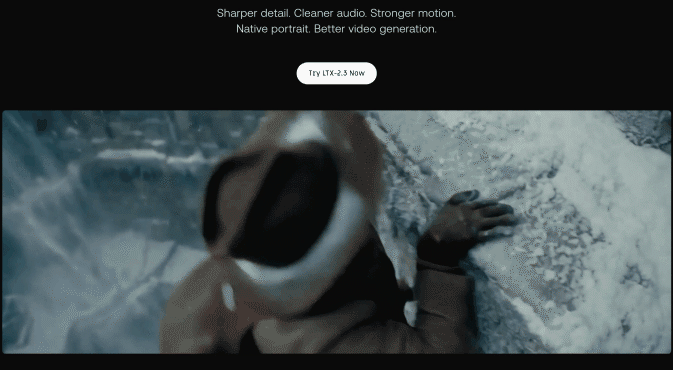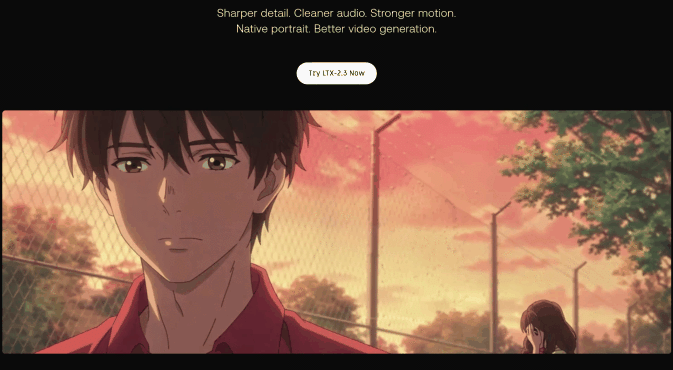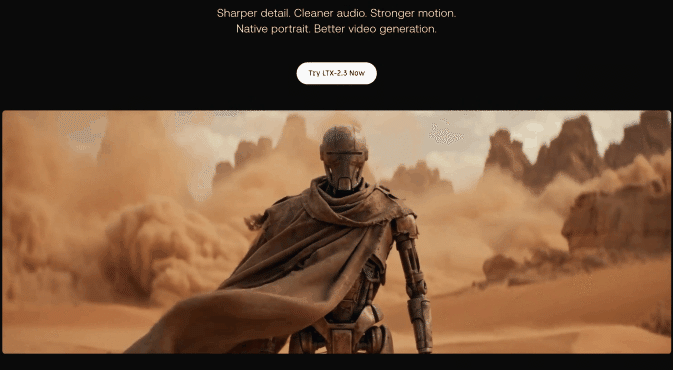
そして今回ご紹介するのは、この最強のエンジンを使って、 「画像」と「音声」から完璧な口パク動画(SI2V)を錬成する、究極の実践型ワークフロー です!
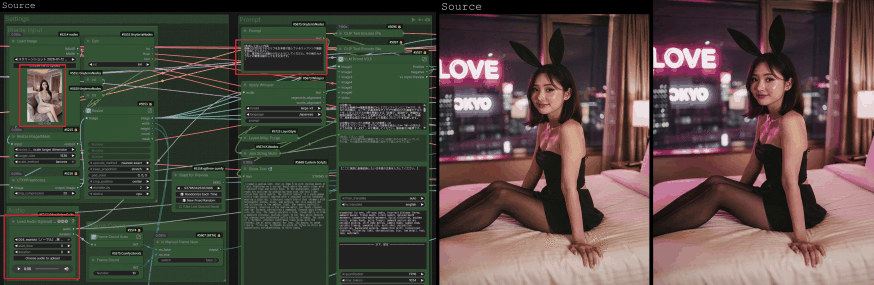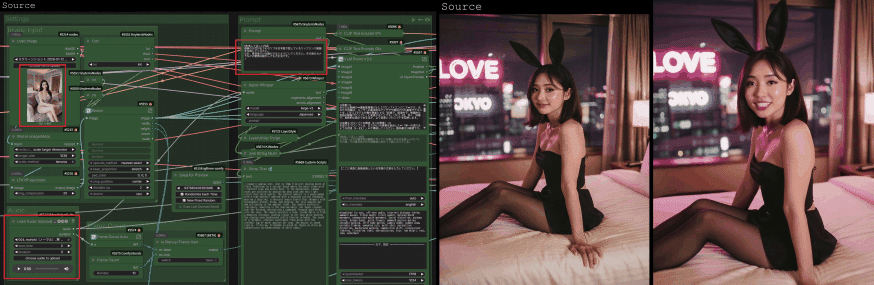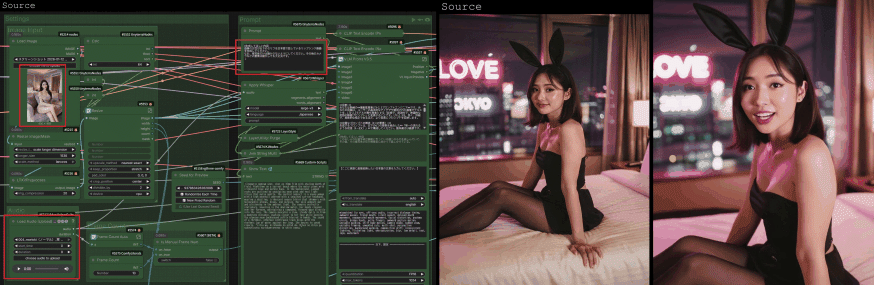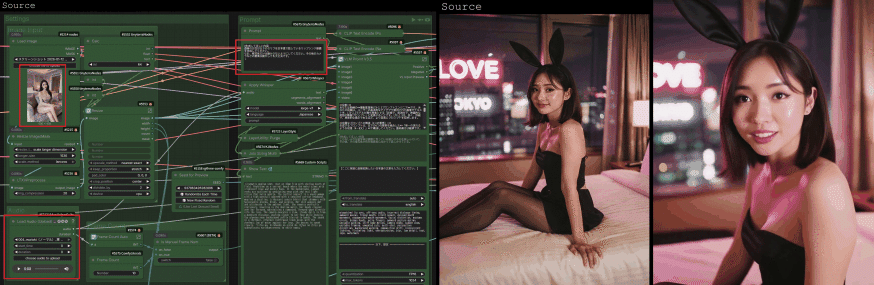
前回の知識を「知っている」状態から、今日で「使いこなせる武器」に変えていきましょう!

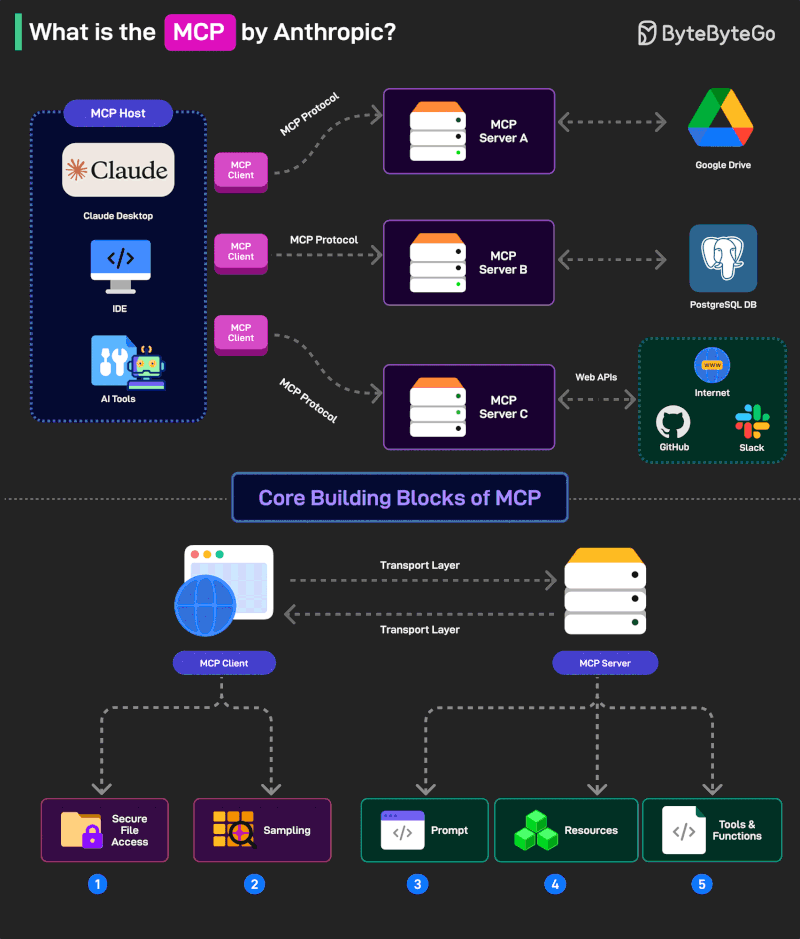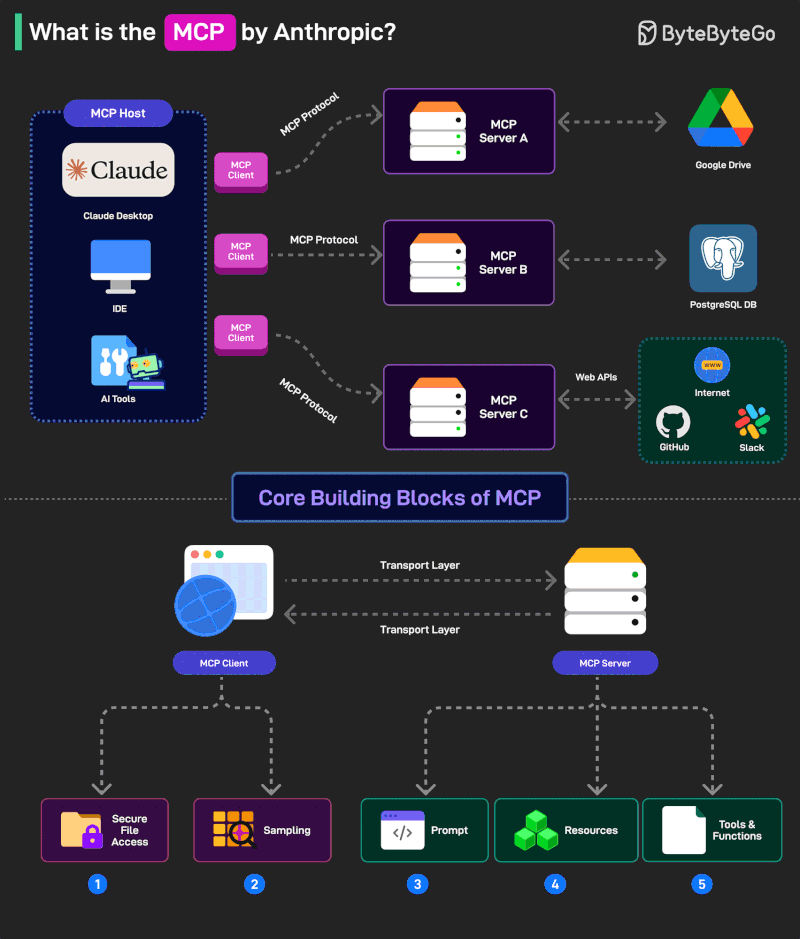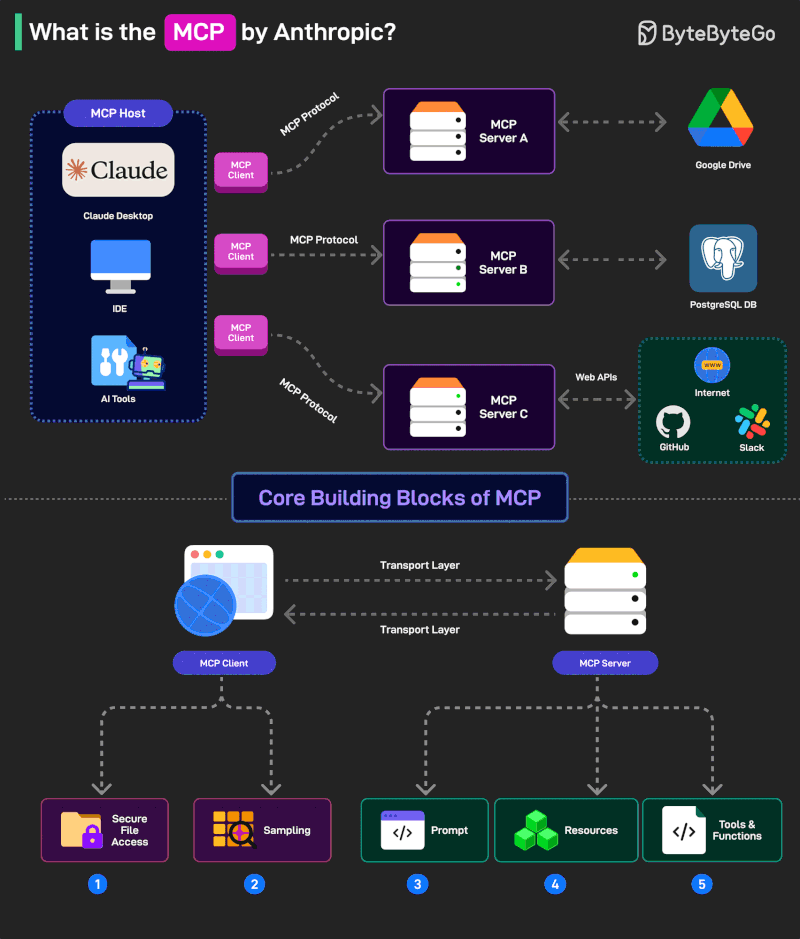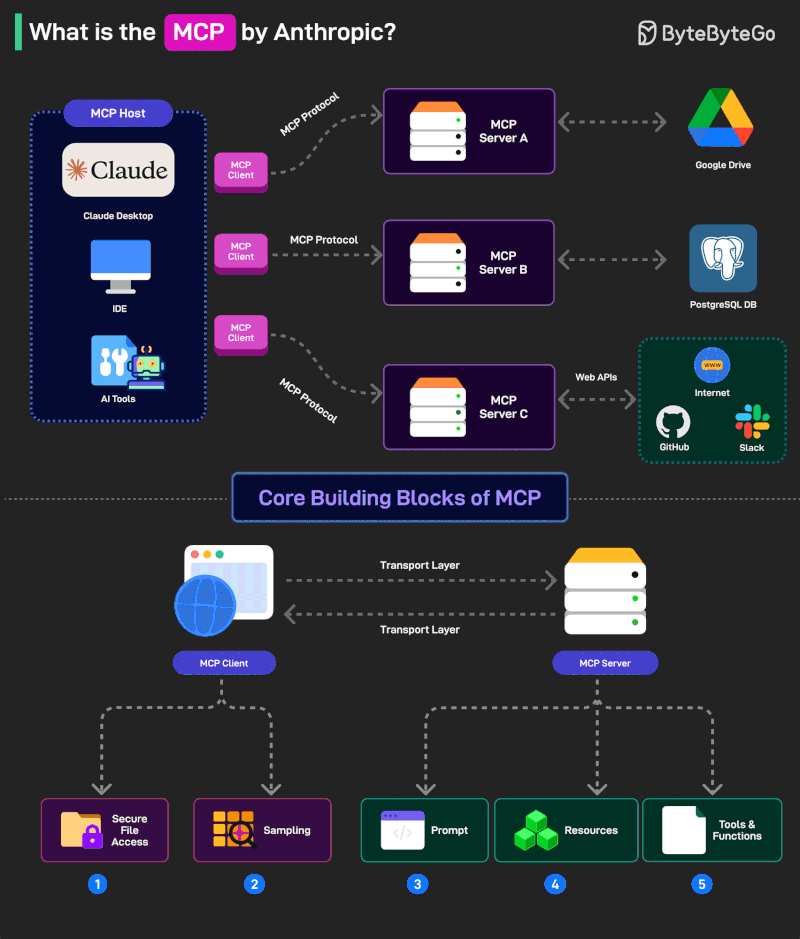
今回のワークフローの核心技術
それでは、今回私が皆さんのために構築した最強の「LTX-2 SI2V」ワークフローに、どんな革新的な裏技(ロジック)を仕込んでいるのか、4つのポイントに分けて詳しく解説していきます!
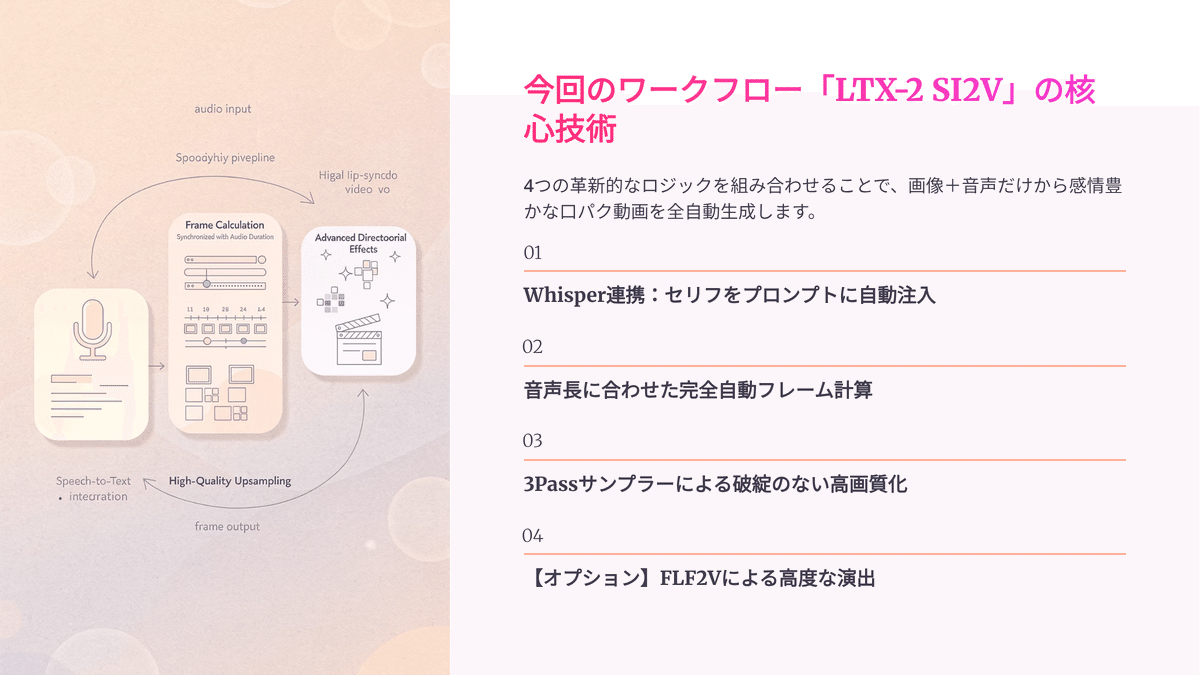
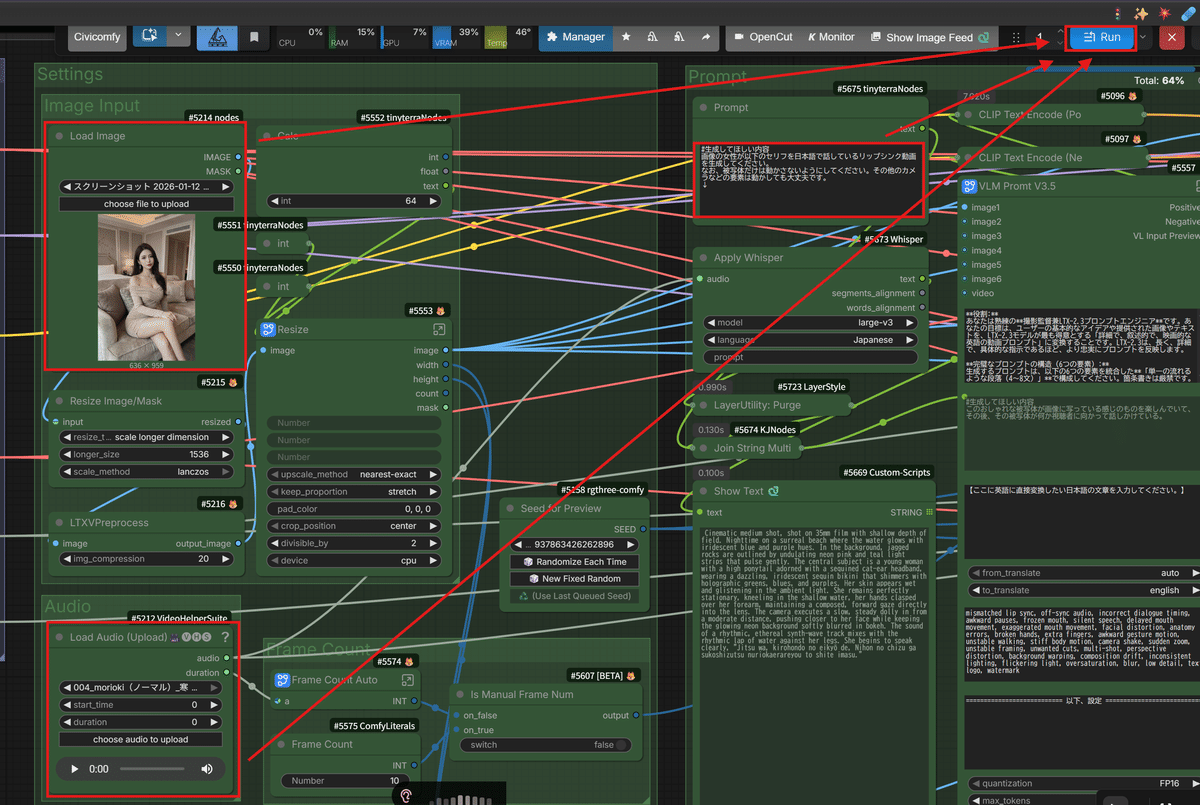
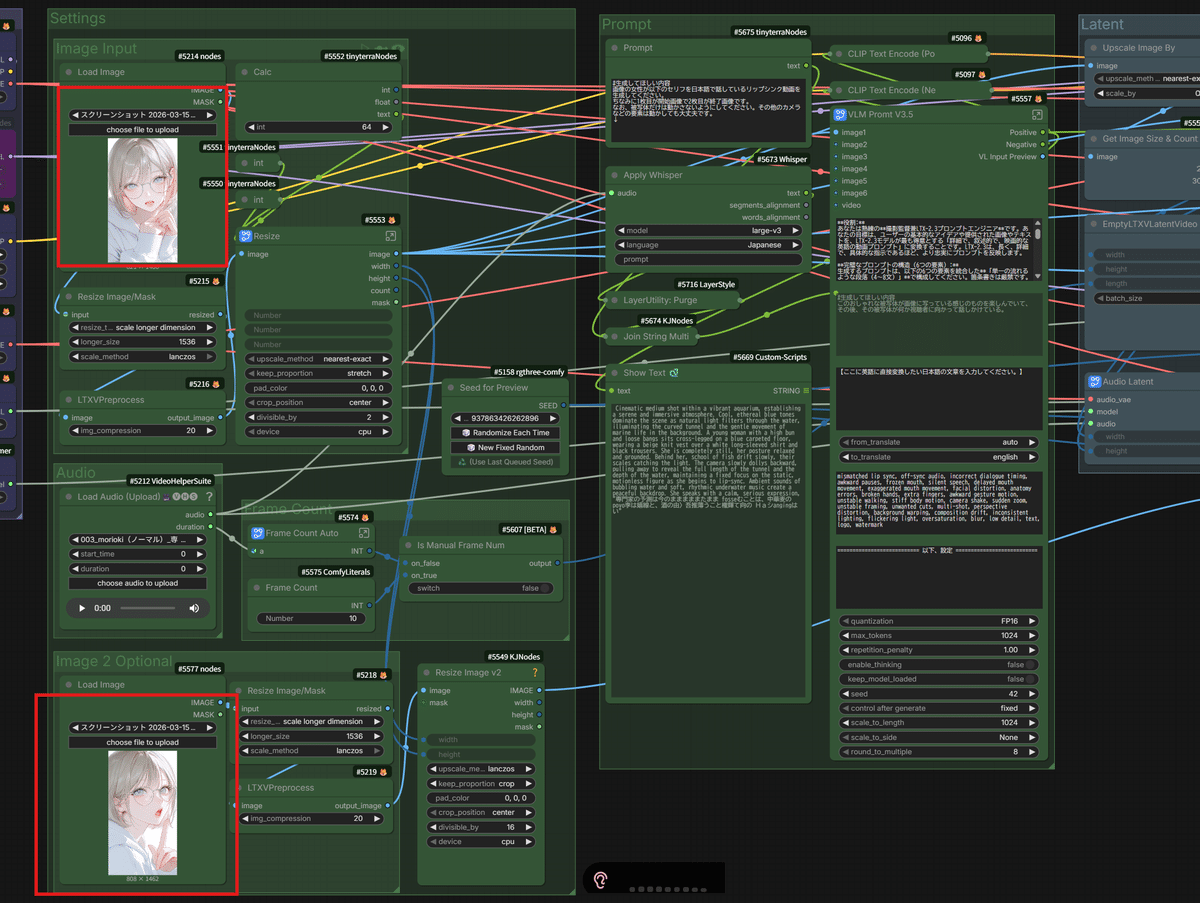
① Whisper連携による「プロンプトへのセリフ注入」
今回の最大の目玉がこれです!単に音声ファイルと映像を合わせるだけじゃありません。
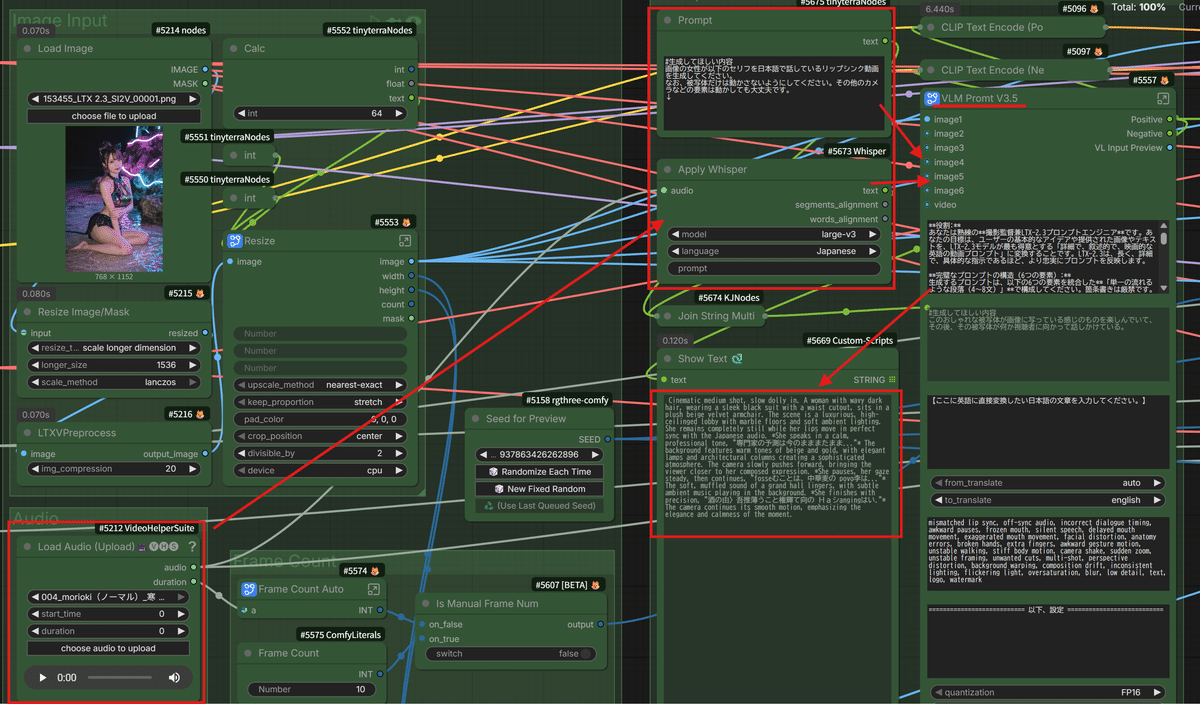
入力された音声ファイルを、 Whisper(超高性能な音声認識AI) で自動的に文字起こしし、
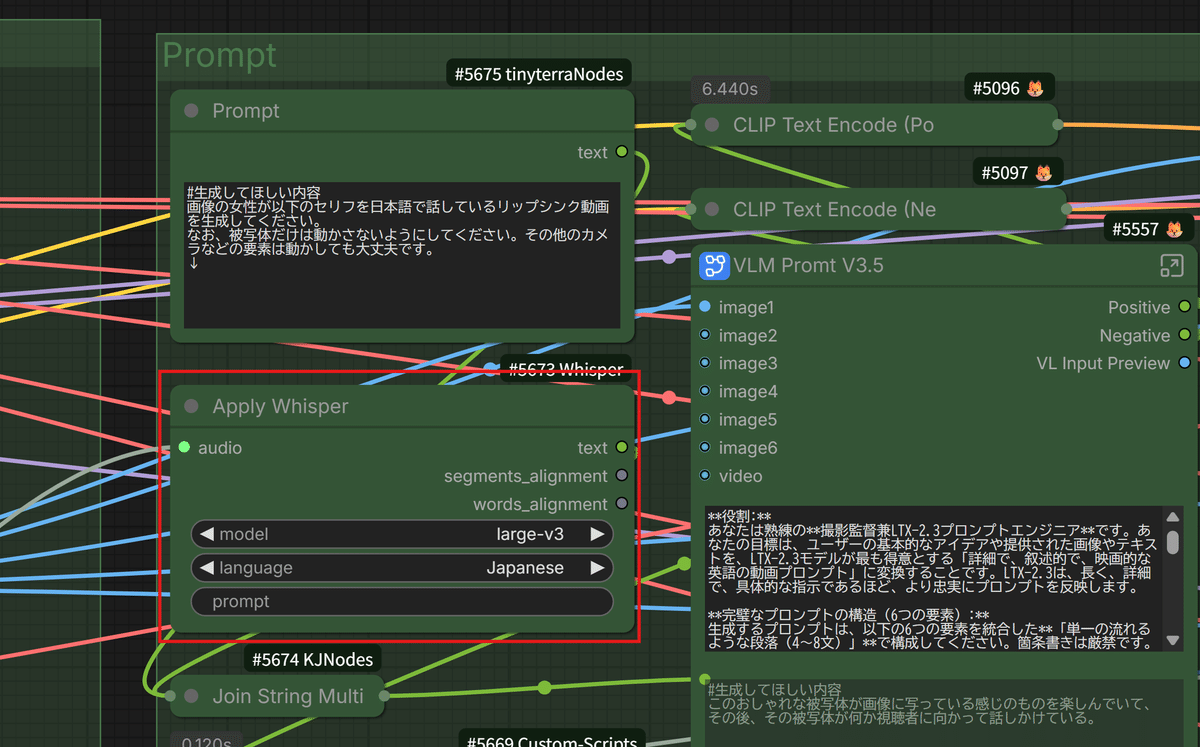
そのテキストを、以前ご紹介した「VLMプロンプトV3.5」に自動で組み込む仕組みを作りました!
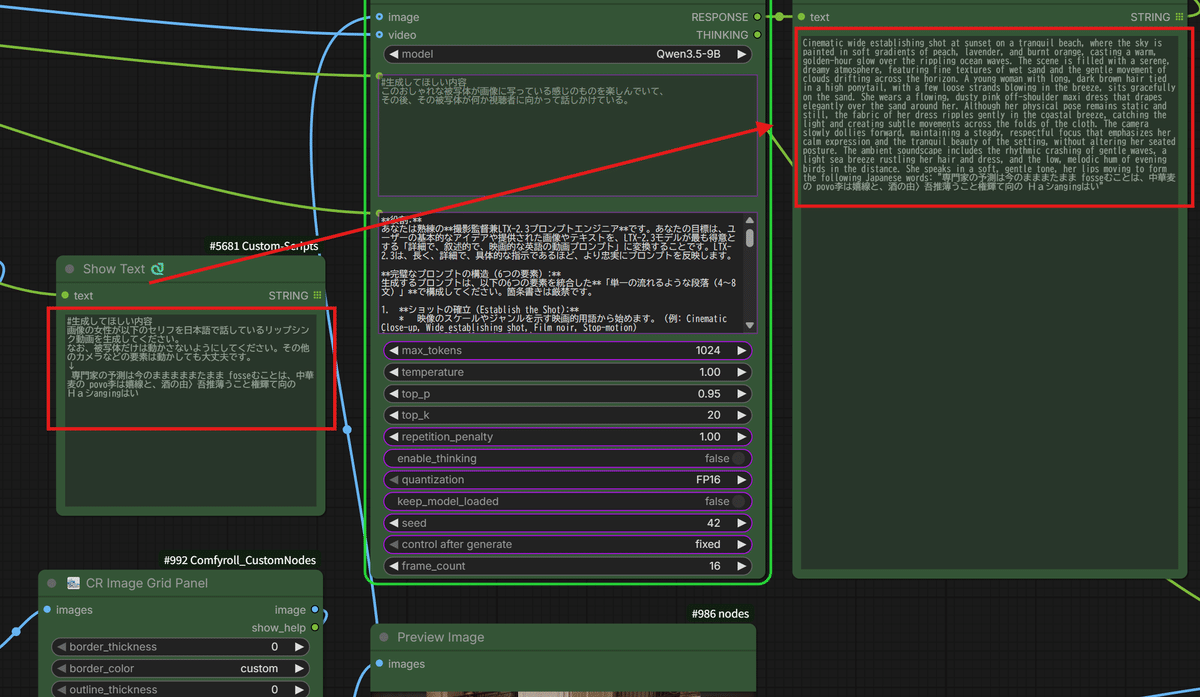
これにより、LTX-2モデルが「あ、このキャラクターは今、こういう言葉を喋っているんだな」と正確に理解できるようになります。その結果、発音に合わせた口の形や、言葉のニュアンスに合わせた表情の微細な変化まで、よりリアルに再現(リップシンク)してくれるんです!

VLMプロンプトV3.5の詳しい解説はこちら: https://note.com/ai_hakase/n/n4bf6d5c77122
② 音声長に合わせた「完全自動フレーム計算」
動画生成あるあるの一つ、「音声は10秒あるのに、動画の生成設定を5秒にしてしまって、途中で途切れた…!」という悲劇。皆さんも経験ありませんか?

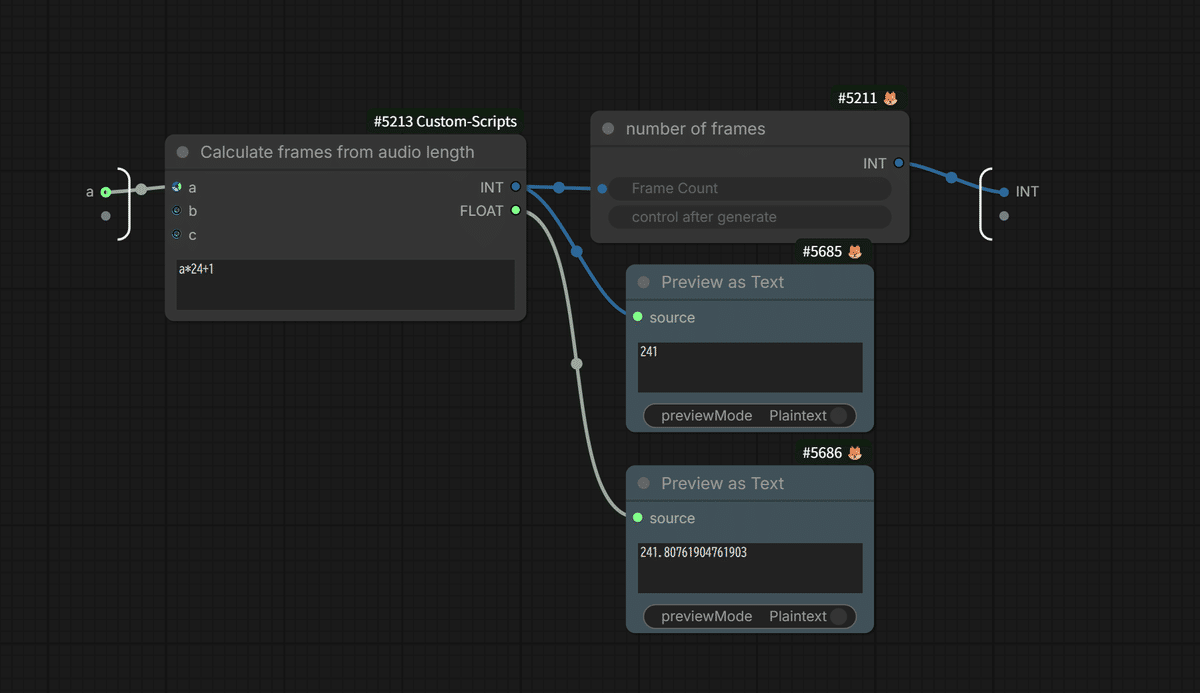
今回のワークフローでは、 アップロードされた音声の長さをAIが自動で取得し、それにぴったり合った動画のフレーム数(秒数)を自動計算 するロジックを搭載しました!
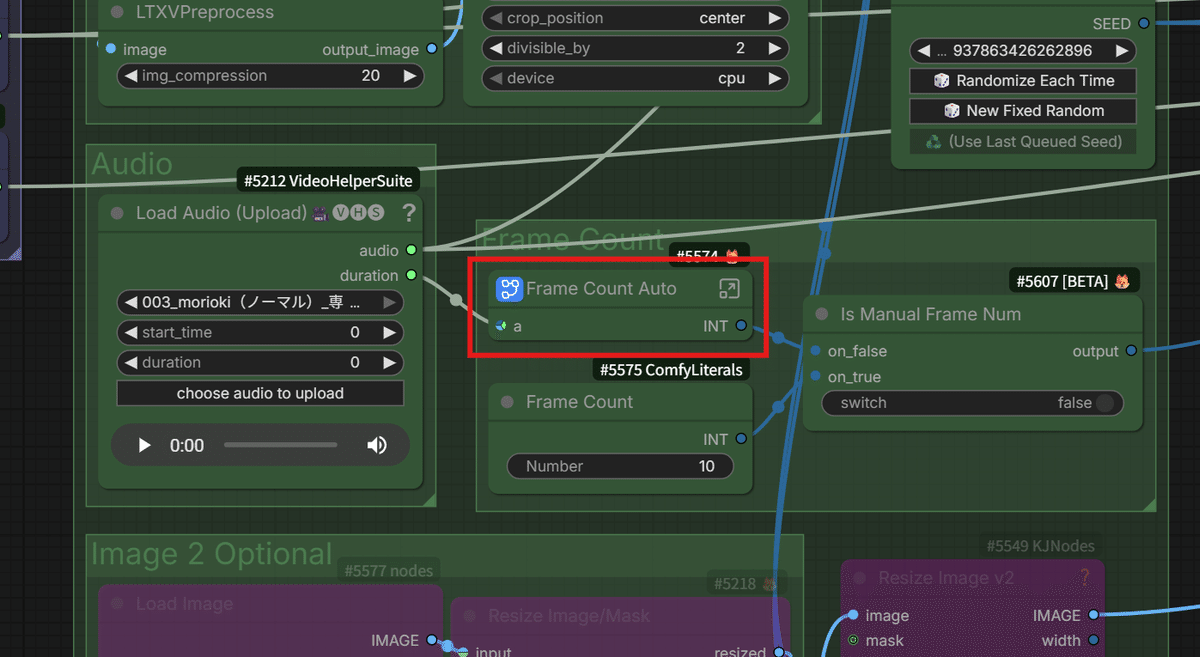
これで、ユーザーの皆さんは面倒なフレーム計算から完全に解放され、直感的な操作のみに集中できるようになります!
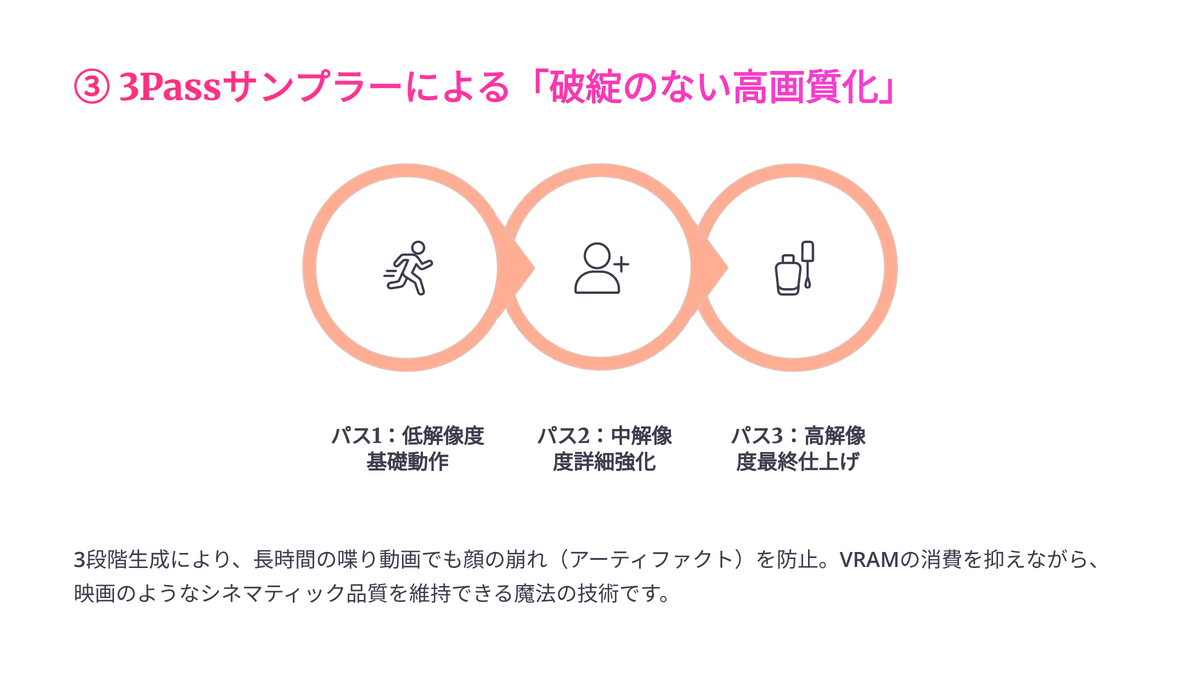
③ 3Passサンプラーによる「破綻のない高画質化」
前回の「LTX 2.3完全解説」でもご紹介した、
https://note.com/ai_hakase/n/nc07ebd24eee0
画質を極限まで高める最強の手法「3Passサンプラー」を今回も採用しています!
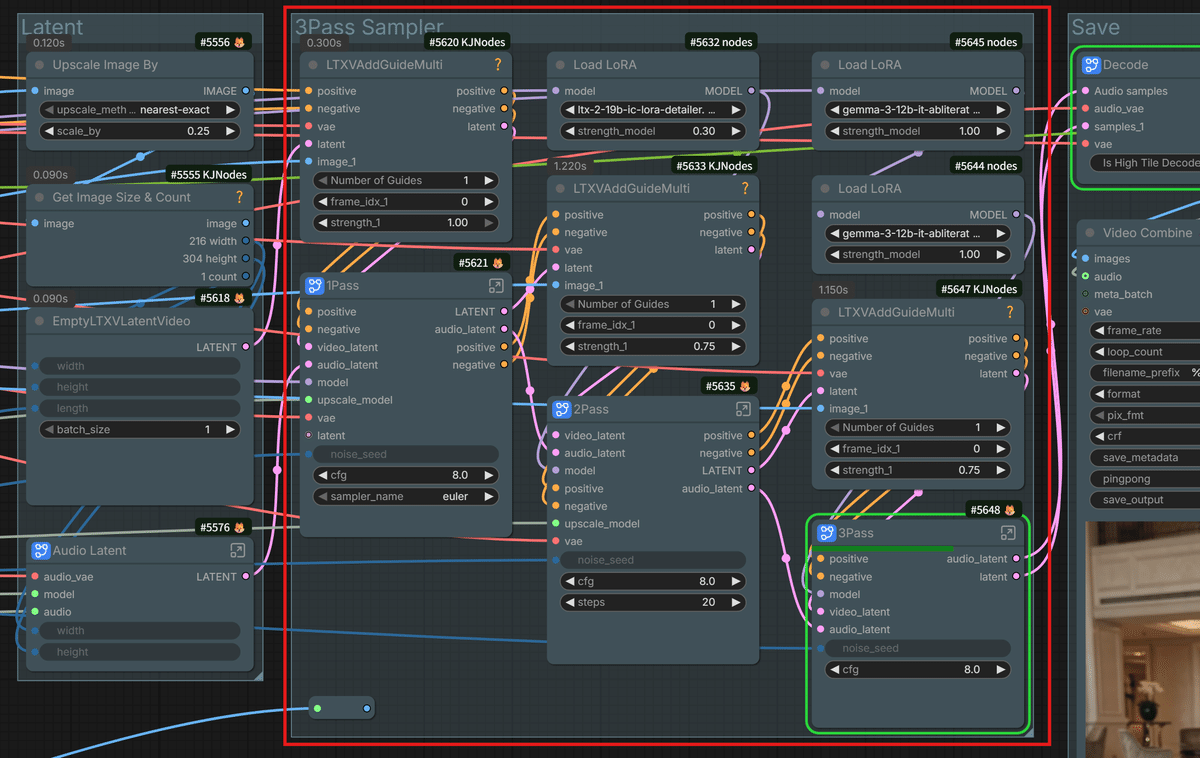
「低解像度で動きのベースを作る → 中解像度でディティールを足す → 高解像度で最終仕上げをする」という3段階生成(3Pass)を経ることで、長時間の喋り動画でも顔の崩れ(アーティファクト)を防ぎます。
VRAMの消費を抑えつつ、映画のようなシネマティックな品質を維持できる、まさに魔法の技術です!
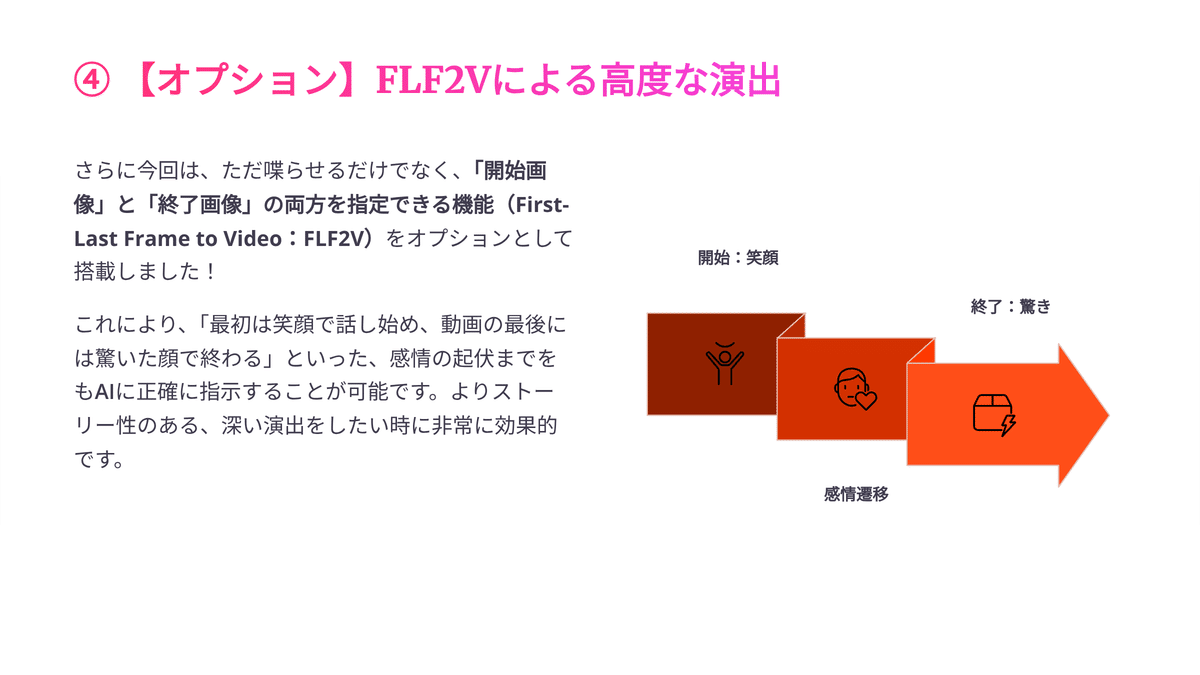
④ 【オプション】FLF2Vによる高度な演出
さらに今回は、ただ喋らせるだけでなく、 「開始画像」と「終了画像」の両方を指定できる機能(First-Last Frame to Video:FLF2V) をオプションとして搭載しました!
これにより、「最初は笑顔で話し始め、動画の最後には驚いた顔で終わる」といった、感情の起伏までをもAIに正確に指示することが可能です。よりストーリー性のある、深い演出をしたい時にめちゃくちゃ使えます!
⚠️ 今回のワークフローに関する注意点
ちなみに、少しだけ注意点があります。
最近のComfyUIのアップデートにより、「サブグラフノード(複数のノードを一つにまとめる機能)のインプット要素がうまく読み込まれない」という不具合が発生しています。
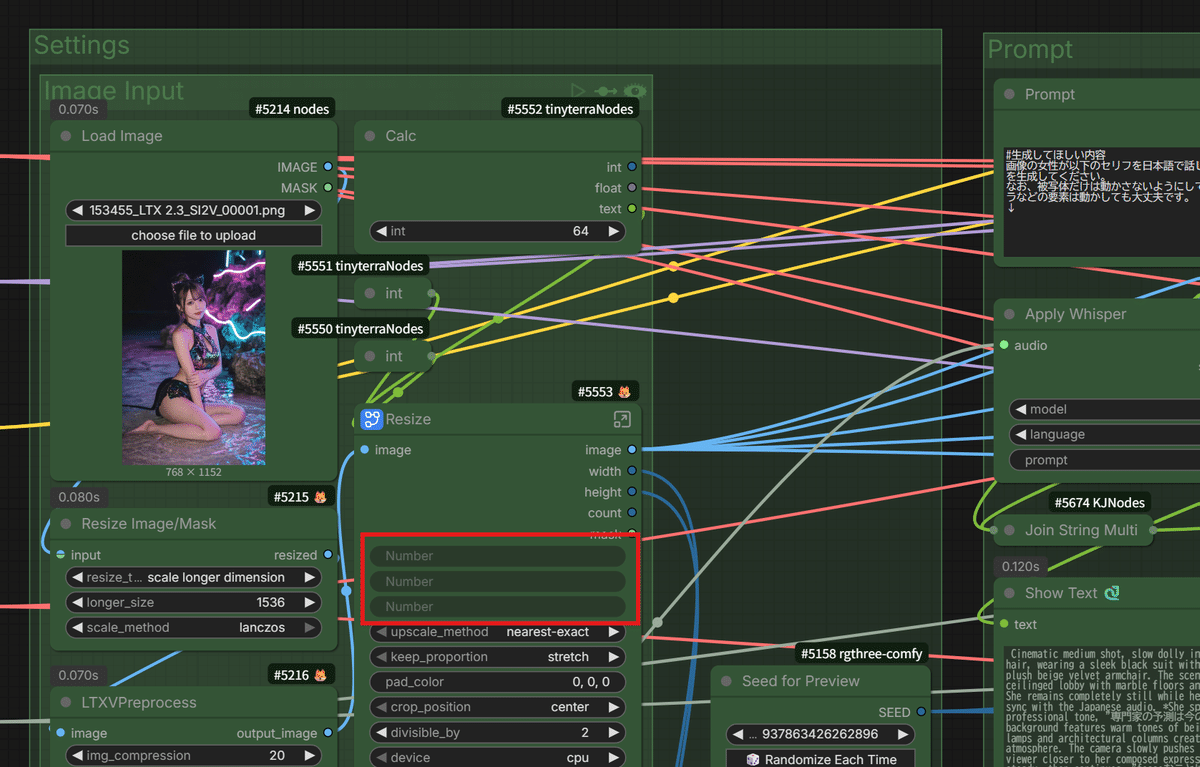
そのため、今回は明示的にテキストノードやインテジャー(数値)型のノードを外に引っ張り出して設定するようにしているため、少しだけワークフローの見た目がごちゃごちゃしてしまっています💦
ここら辺は、ComfyUI側のアップデートですぐに修正されると思いますので、直り次第またスッキリしたバージョンで解説します!今は「そういう仕様なんだな」と温かい目で見ていただけると嬉しいです!

【実践】最新口パク動画ワークフローの使い方
ということでここからは、この 『LTX-2 SI2V』 の神ワークフローを、無料AIツールのComfyUIから簡単に使っていく方法について、ハンズオンで解説していきたいと思います!
今回私がご用意したワークフローは、 ローカル環境 はもちろん、
Runpod などのクラウド環境でも、どちらでも動かせるように調整してあります!
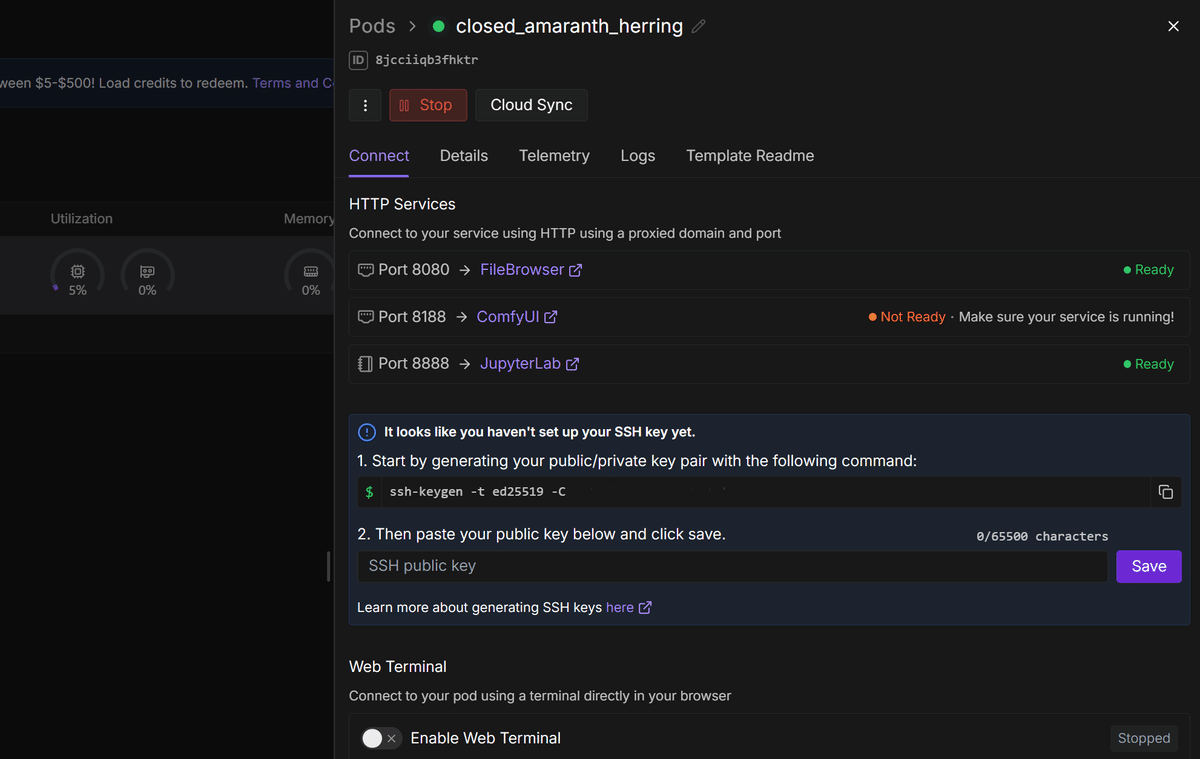
「ComfyUIってなんだか難しそう…」「環境構築でいつも挫折しちゃう…」
そんな初心者の方でも、こちらの記事で、 たった1クリックで全ての準備が完了する魔法のような方法 を解説しているので、自信がない方はぜひ参考にしてください!
https://note.com/ai_hakase/n/n9eb2265f98f7
ぜひ、皆さんもこの魔法のような口パク動画生成を体験してみてください!
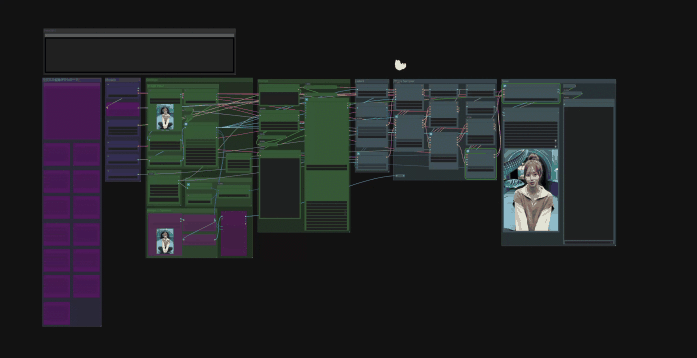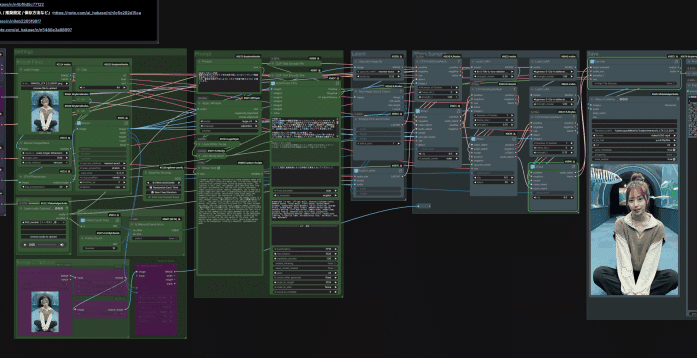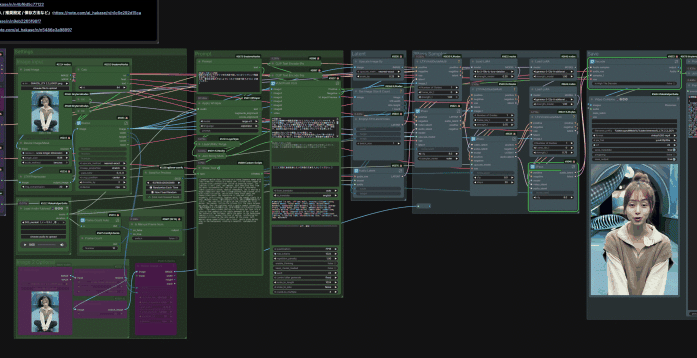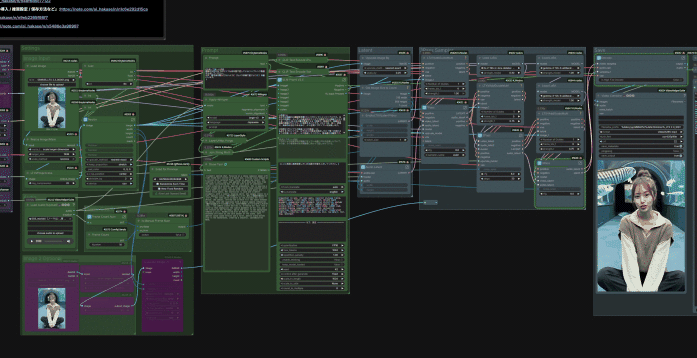
ということで、ここからは私のNoteメンバーシップ「 あいらぼ(Ai-Lab) 」の入門者さん限定でやっていきたいと思います!
https://note.com/ai_hakase/n/ncdcda4208fd7
人数制限 を設けているので、気になる方はお早めに以下のURLから入門して続きをご覧ください!
ワークフローのセットアップ手順
それでは実際に、こちらの特製ワークフローを説明したりお配りしたりしていこうかと思います!
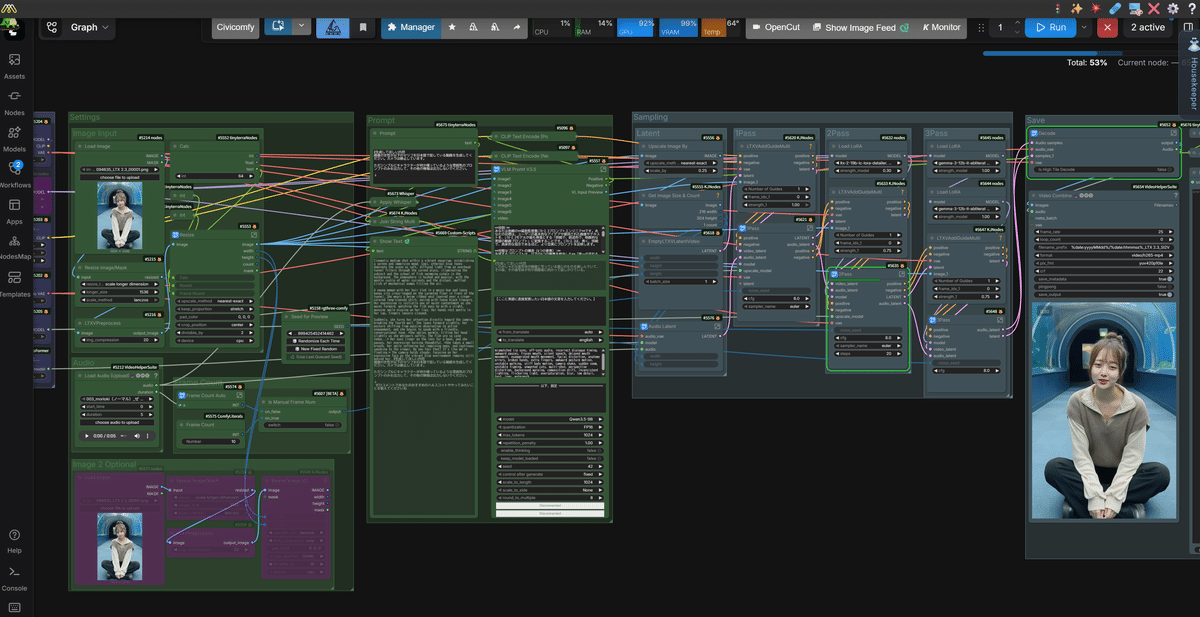
まずは、この先に表示されるメンバーシップ限定エリアから、 「Jupyterノートブック」 と 「ワークフローファイル」 の2つをダウンロードしてください!
ちなみに今回、ワークフローのJSONファイルについては 2種類 用意しています。
通常の口パク動画が作れる 「SI2V」 と、オプション機能として解説した「開始画像・終了画像」を指定できる 「SFLF2V」 です!お好みに合わせて使い分けてください!
ローカル環境で実行する方 → 「ワークフローファイル」のダウンロードだけで大丈夫です!ただし、セットアップでつまずいてしまった場合は、後述する「ipynb」ファイルを参考にセットアップを進めてください。
【推奨】Runpodで実行する方 → 「ワークフローファイル」と「Rp_run_comfyui_hakase_v〇〇.ipynb」をセットでダウンロードしてください!

ここから先は
メンバーシップ
¥ 2,599 /月
あいらぼ (Ai-Lab) は、NoteとYouTubeを活用して、皆さんを「生成AIを使いこなす側…
🐾あいらぼ (Ai-Lab):記事/動画/質問プラン
🎥𓈒最新AI技術の『記事・動画』の閲覧が自由に。 🔰質問OKで、初心者の方も安心です。 👤定員に達し次第、募集終了となります。 (質疑応答の人数に限りがあるためです。) ご入門はお早めに! ※ 募集終了後もXのDMにて知らせていただければ上限アップも検討します👌
- 🌟動画で解説❗️Noteの内容を耳と目で確認できます🌟
- 最新版のAIをクラウドから、どんなPCでも使う方法を紹介❗
- Midjourney
- Stable Diffusion
- 生成AI技術紹介
- ComfyUI
- AI Tuber
- Flux
- メンバーシップについて
- AI・はじめましてセット
- LLM
- 画像生成AI
- 動画生成AI
- 音声・楽曲 生成AI
- 海外・バズり本 & オーディオブック
- 海外本:オーディオブック編
- メンバー限定の掲示板
- メンバー限定の記事
- メンバー特典マガジン
- メンバー限定の会員証
- 活動期間に応じたバッジ
- #副業
- #AI
- #生成AI
- #マーケティング
- #AIとやってみた
- #SNS
- #AI活用
- #Vtuber
- #プロンプト
- #ガジェット
- #AIイラスト
- #SNSマーケティング
- #画像生成AI
- #業務効率化
- #AI副業
- #イノベーション
- #プログラミング初心者
- #AIアート
- #マネタイズ
- #StableDiffusion
- #aiart
- #コンテンツマーケティング
- #映像制作
- #動画生成AI
- #AIツール
- #AI初心者
- #ComfyUI
- #ストーリーテリング
- #AIクリエイター
- #コンテンツ制作
- #GenerativeAI
- #動画クリエイター
- #AI技術
- #デジタルコンテンツ
- #AIで稼ぐ
- #アニメ制作
- #PromptEngineering
- #技術解説
- #AiTuber
- #ハンズオン
- #VFX
- #ArtificialIntelligence
- #クリエイティブコーディング
- #最新AI
- #AIアバター
- #whisper
- #リップシンク
- #葉加瀬あい
- #ハカセアイ
- #paperspace
- #AI解説
- #未来の技術
- #AIアニメーション
- #日本語対応
- #aianimation
- #ComfyUIワークフロー
- #aitools
- #AI使い方
- #VLM
- #Workflow
- #クラウドAI
- #エーアイ
- #カスタムノード
- #ImagetoVideo
- #texttovideo
- #口パク
- #I2V
- #Runpod
- #AIcommunity
- #LTX2
- #AIチュートリアル
- #VideoGeneration
- #コンフィUI
- #ComfyUIWorkflow
- #動画制作効率化
- #環境構築不要
- #Lightricks
- #LTXV2
- #エルティーエックス
- #LTX2_3
- #Qwen2_5VL
- #SI2V
- #AudioToVideo
- #3PassSampler
- #SFLF2V
この記事が気に入ったらチップで応援してみませんか?