 | submitted by /u/eternviking [link] [comments] |
Supercharging LLM inference on Google TPUs: Achieving 3X speedups with diffusion-style speculative decoding- Google Developers Blog
Reddit r/LocalLLaMA / 5/6/2026
📰 NewsDeveloper Stack & InfrastructureSignals & Early TrendsModels & Research
Key Points
- The post describes how to speed up LLM inference on Google TPUs by using diffusion-style speculative decoding to reduce wasted computation during token generation.
- It reports up to 3× throughput/latency speedups compared with a baseline decoding approach, emphasizing practical performance gains on TPU hardware.
- The method leverages speculative proposals (inspired by diffusion) that are then verified, so the system can accept multiple tokens efficiently while maintaining output correctness.
- The article frames the work as a TPU-optimized inference technique that could improve real-world deployment efficiency for LLM applications.
- Overall, it highlights that inference-time algorithm design (not just model changes) can materially improve serving performance on specialized accelerators.
Related Articles

Transform Your Blurry Photos into HD Masterpieces, Instantly!
Dev.to

6 New Moats for AI Agent Infrastructure — Trust Score, Deployment, SLA, Identity, Compliance-as-Code
Dev.to

There will still be art in software
Dev.to

Google Home’s Gemini AI can handle more complicated requests
The Verge
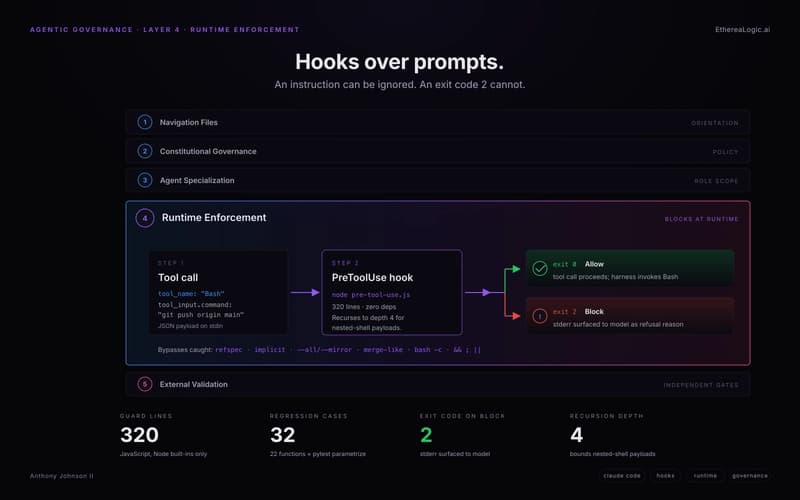
Exit Code 2: How Claude Hooks Turn Agentic Rules Into Runtime Barriers
Dev.to