Do Large Language Models Plan Answer Positions? Position Bias in Multiple-Choice Question Generation
arXiv cs.CL / 5/5/2026
📰 NewsIdeas & Deep AnalysisModels & Research
Key Points
- The study finds that large language models and vision-language models generating MCQs often display systematic position bias, meaning correct answers are not uniformly distributed across options.
- Experiments across multiple MCQ generation tasks (with 10 LLMs and 5 VLMs) show that these biases are structured and tend to follow similar patterns within the same model families.
- Probing hidden representations suggests the model question stem can implicitly carry signals about the correct answer’s position, indicating that the position may be planned during generation.
- Using activation steering, the authors are able to manipulate internal representations to partially control positional preferences and significantly alter the answer-position distribution.
- The paper proposes a practical way to study implicit positional planning and argues for controllable generation to improve the reliability of MCQ construction and evaluation.
Related Articles
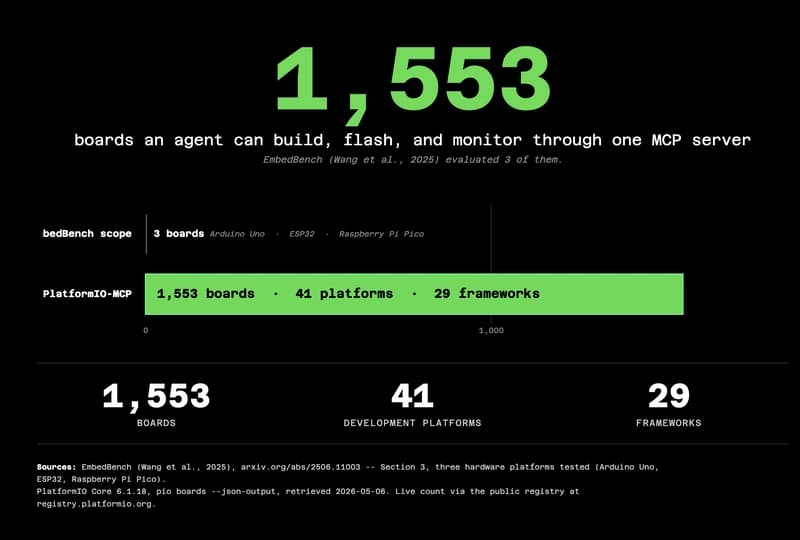
The 55.6% problem: why frontier LLMs fail at embedded code
Dev.to

Four CVEs in a week, all the same shape: when agents execute LLM-generated code
Dev.to
Healthcare AI Is Absorbing Institutional Knowledge It Can't Actually Hold
Reddit r/artificial
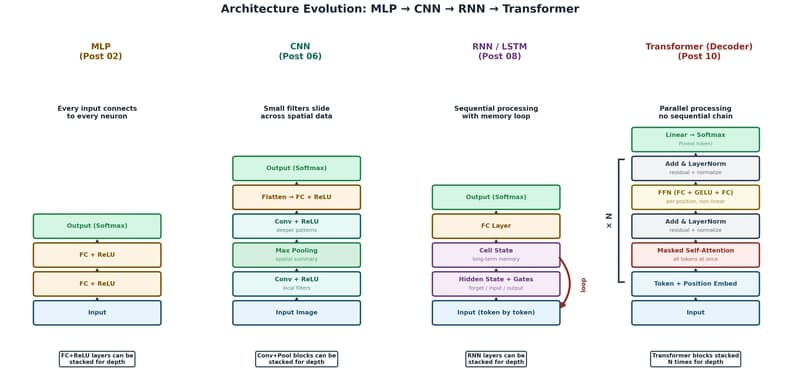
The Transformer: The Architecture Behind Modern AI
Dev.to

Foundational Models Defining a New Era in Vision: A Survey and Outlook
Dev.to