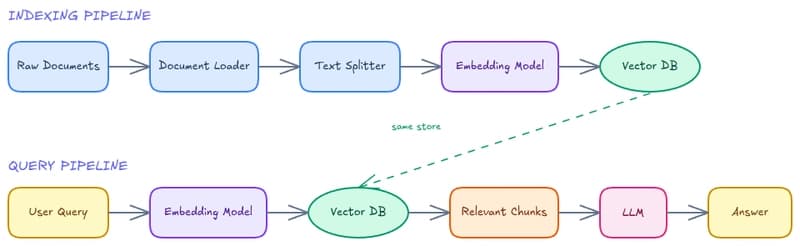
In this tutorial, we walk through a complete, hands-on journey of post-training large language models using the powerful TRL (Transformer Reinforcement Learning) library ecosystem. We start from a lightweight base model and progressively apply four key techniques: Supervised Fine-Tuning (SFT), Reward Modeling (RM), Direct Preference Optimization (DPO), and Group Relative Policy Optimization (GRPO). Also, we […]
The post A Coding Guide on LLM Post Training with TRL from Supervised Fine Tuning to DPO and GRPO Reasoning appeared first on MarkTechPost.