Adaptive Estimation and Inference in Semi-parametric Heterogeneous Clustered Multitask Learning via Neyman Orthogonality
arXiv stat.ML / 5/5/2026
📰 NewsModels & Research
Key Points
- The paper addresses clustered multitask learning where tasks share a latent cluster structure in their target parameters but have highly heterogeneous (even potentially infinite-dimensional) nuisance components.
- It proposes an adaptive fused orthogonal estimator that combines Neyman-orthogonal losses with data-driven pairwise fusion penalties calibrated using task-specific pilot estimates.
- The authors prove theoretical guarantees including exact recovery of the latent cluster assignments with high probability and pooled parametric convergence rates tied to cluster size.
- They also establish asymptotic normality and show the method asymptotically matches the performance of an oracle that knows the true clustering in advance.
- Experiments and a U.S. residential energy consumption application indicate the approach outperforms strong baselines and can reveal interpretable regional clustering in electricity price elasticity.
Related Articles

Singapore's Fraud Frontier: Why AI Scam Detection Demands Regulatory Precision
Dev.to
From OOM to 262K Context: Running Qwen3-Coder 30B Locally on 8GB VRAM
Dev.to

Nano Banana Pro vs DALL-E 3 vs Midjourney: A Practical Comparison From Someone Who Actually Uses All Three
Dev.to
LLMs edited 86 human essays toward a semantic cluster not occupied by any human writer [D]
Reddit r/MachineLearning
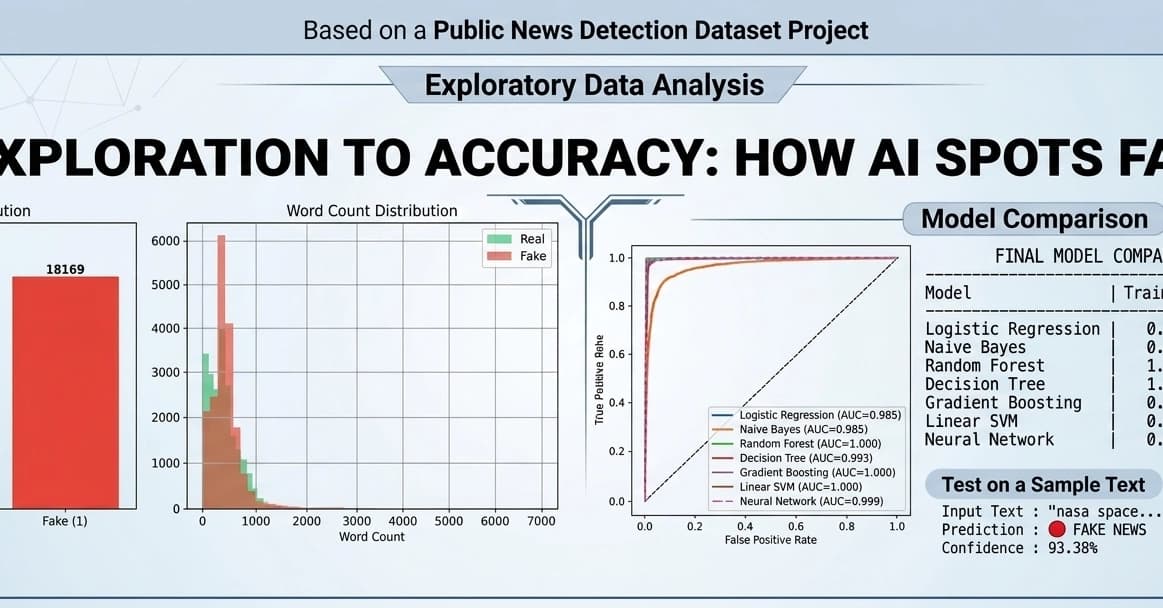
Fake News Detection using Machine Learning & NLP!
Dev.to