Defend: Automated Rebuttals for Peer Review with Minimal Author Guidance
arXiv cs.AI / 3/31/2026
📰 NewsIdeas & Deep AnalysisTools & Practical UsageModels & Research
Key Points
- The paper introduces DEFEND, an author-in-the-loop LLM tool for generating rebuttals in peer review that emphasizes structured reasoning rather than fully free-form writing.
- The authors find that direct LLM-based rebuttal generation often fails on factual correctness and targeted refutation, requiring better controls to keep outputs grounded.
- DEFEND is compared with three baselines (direct rebuttal generation, segment-wise generation, and a sequential segment-wise approach without author intervention), with DEFEND and author-in-the-loop methods performing substantially better.
- To support fine-grained evaluation, the work extends the ReviewCritique dataset with new annotations for review segmentation, deficiency/error types, rebuttal-action labels, and mappings to gold rebuttal segments.
- Experimental results plus a user study indicate that segment-wise generation with minimal author intervention reduces author cognitive load while improving refutation quality.
Related Articles

Black Hat Asia
AI Business

How to Verify Information Online and Avoid Fake Content
Dev.to
I built an AI code reviewer solo while working full-time — honest post-launch breakdown
Dev.to
Mobile App MVP: Build, Launch, and Validate in Under a Week
Dev.to
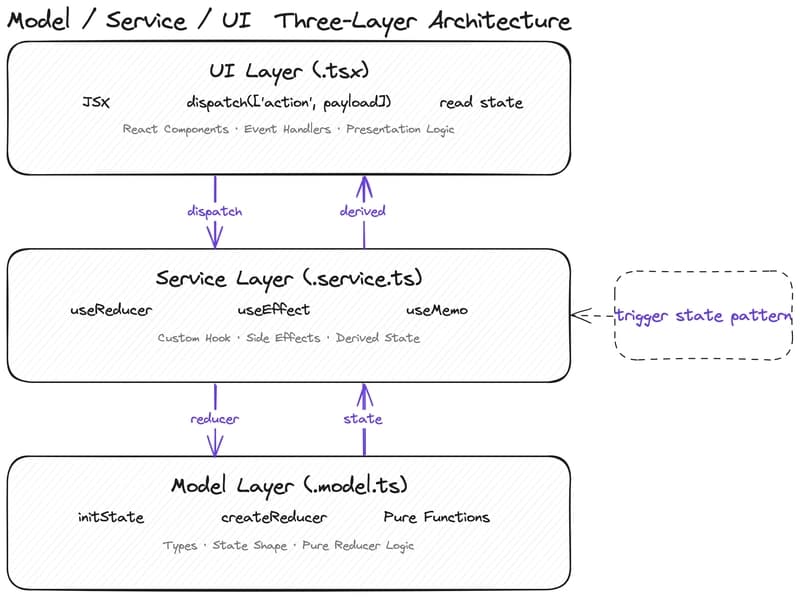
Why Your State Management Is Slowing Down AI-Assisted Development
Dev.to