Enhancing Reinforcement Learning for Radiology Report Generation with Evidence-aware Rewards and Self-correcting Preference Learning
arXiv cs.LG / 4/16/2026
💬 OpinionIdeas & Deep AnalysisModels & Research
Key Points
- The paper proposes Evidence-aware Self-Correcting Reinforcement Learning (ESC-RL) to improve radiology report generation by addressing weak, report-level reward signals for clinical faithfulness.
- ESC-RL introduces GEAR (Group-wise Evidence-aware Alignment Reward), which provides group-wise feedback to reinforce true positives, recover false negatives, and suppress unsupported false positives.
- It also adds SPL (Self-correcting Preference Learning) that builds a disease-aware preference dataset from multiple noisy observations and uses an LLM to synthesize refined reports without human supervision.
- Experiments on two public chest X-ray datasets show consistent performance improvements and state-of-the-art results, suggesting ESC-RL yields more evidence-grounded and preference-aligned outputs during training.
Related Articles
The AI Hype Cycle Is Lying to You About What to Learn
Dev.to
Big Tech firms are accelerating AI investments and integration, while regulators and companies focus on safety and responsible adoption.
Dev.to

Inside NVIDIA’s $2B Marvell Deal: What NVLink Fusion Means for AI Ethernet Fabrics
Dev.to
Automating Your Literature Review: From PDFs to Data with AI
Dev.to
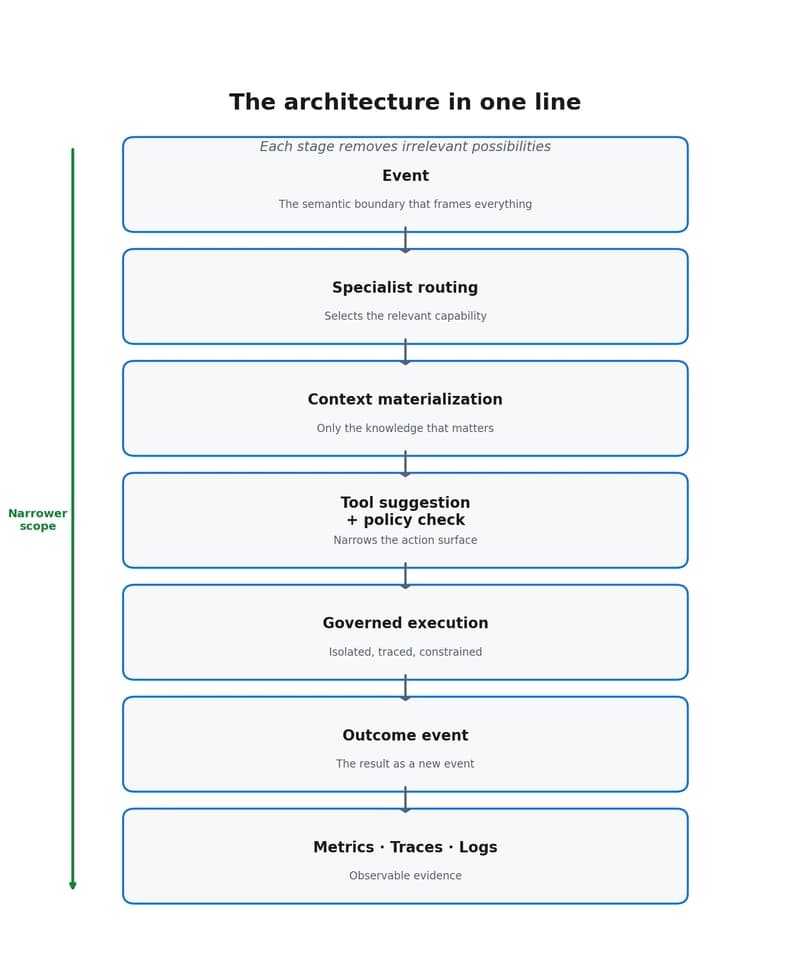
Why event-driven agents reduce scope, cost, and decision dispersion
Dev.to