GraphVLM: Benchmarking Vision Language Models for Multimodal Graph Learning
arXiv cs.CV / 3/17/2026
📰 NewsTools & Practical UsageModels & Research
Key Points
- GraphVLM presents a systematic benchmark to evaluate vision-language models for multimodal graph learning.
- It studies three integration paradigms—VLM-as-Encoder, VLM-as-Aligner, and VLM-as-Predictor—to fuse multimodal features, bridge modalities for structured reasoning, and serve as backbones for graph learning.
- Across six diverse datasets, experiments show that VLMs enhance multimodal graph learning in all three roles, with the VLM-as-Predictor providing the strongest gains.
- The benchmark code is publicly available on GitHub, enabling researchers to reproduce results and compare methods.
Related Articles
Two bots, one confused server: what Nimbus revealed about AI agent identity
Dev.to
How to Create a Month of Content in One Day Using AI (Step-by-Step System)
Dev.to

OpenTelemetry just standardized LLM tracing. Here's what it actually looks like in code.
Dev.to
🌱 How AI is Transforming Planting — and Why It Matters
Dev.to
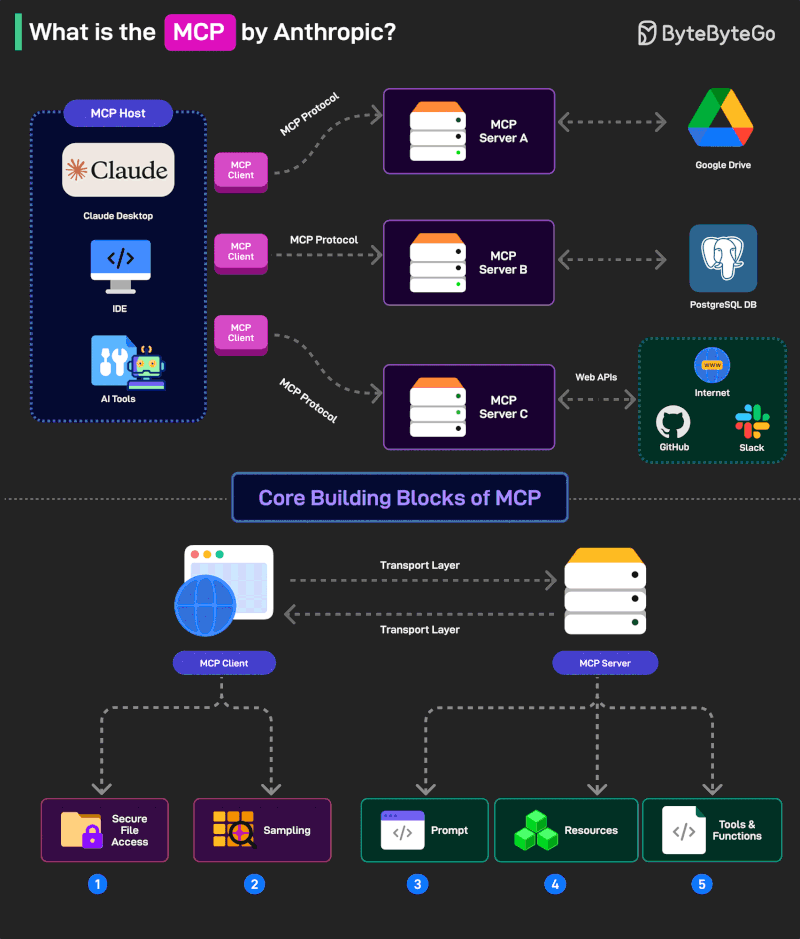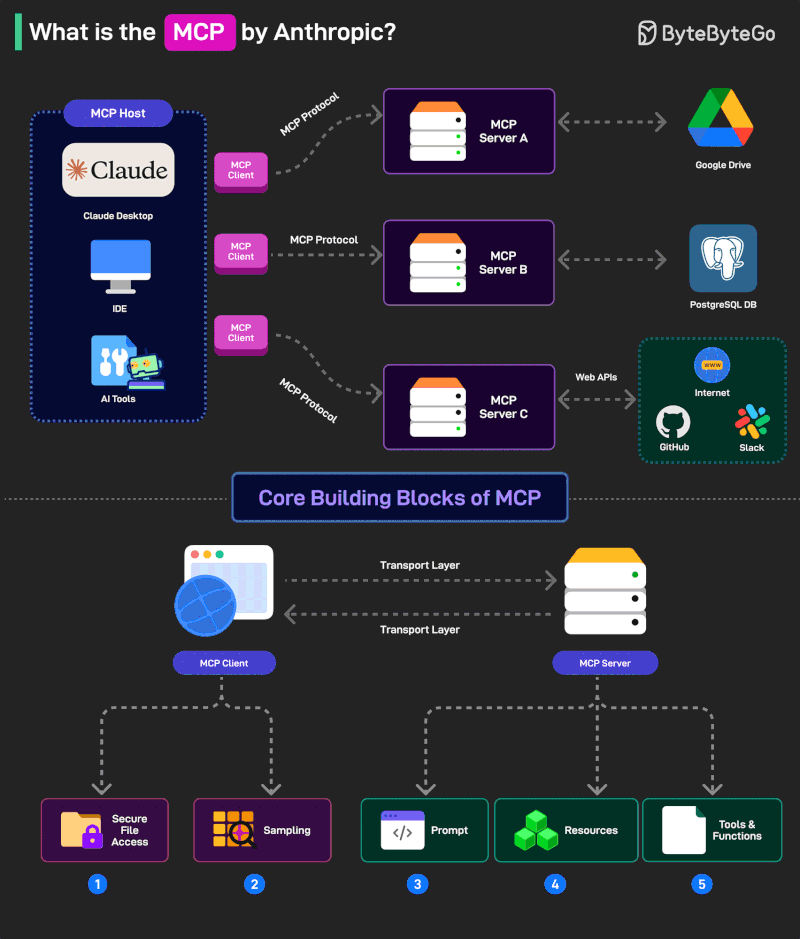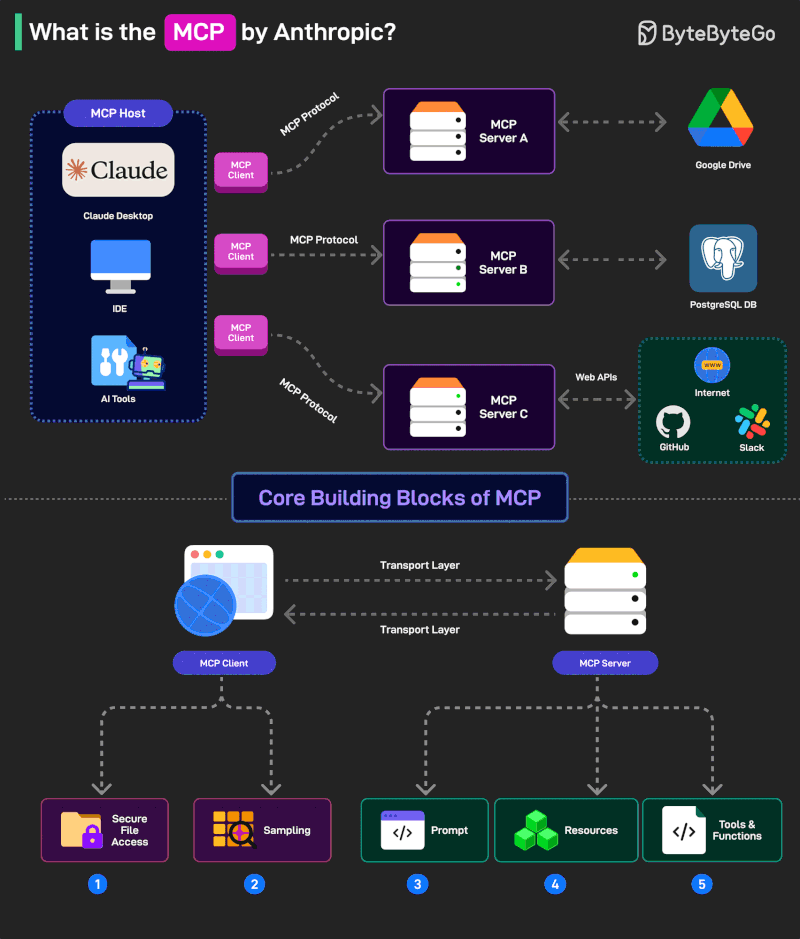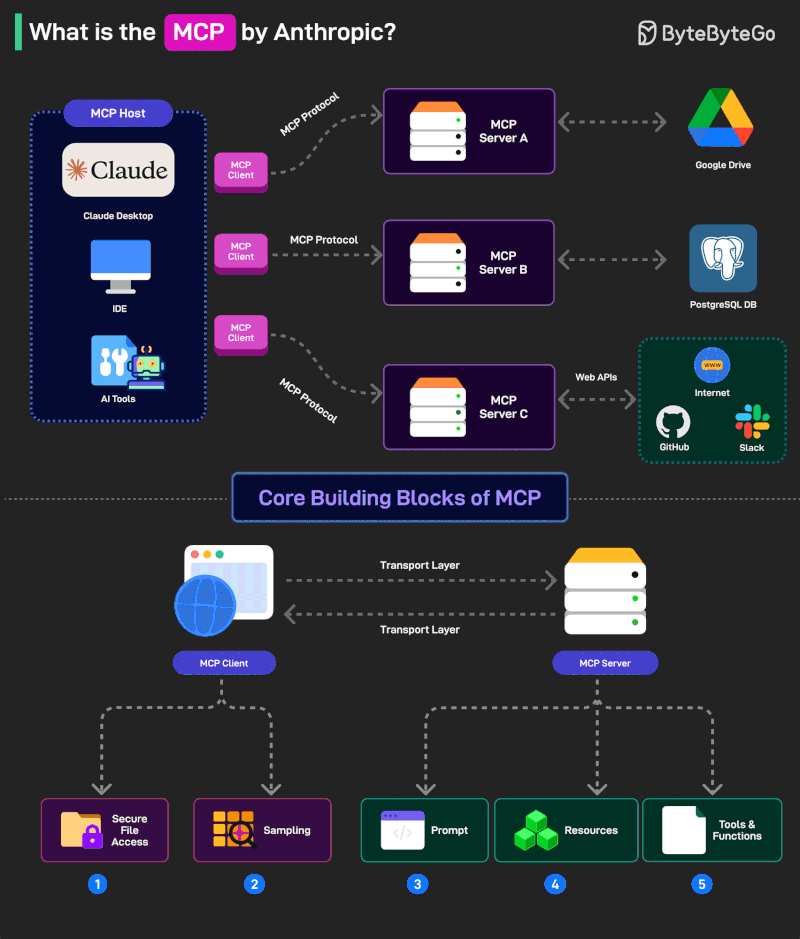
What is MCP?
Dev.to