Dear friends,
One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalyse narrative of upcoming job market collapse is false). However, I believe there will be far more AI Engineer jobs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.

Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompts, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI

Ambient, from Kian Katanforoosh and Workera, measures your skills in the flow of work. You already measure other things that matter: sleep, steps, stress. Why not your skills? Join the waitlist
News
Gemini 3.5 Flash Pairs Smarts With Speed
Google’s faster model brings substantive gains at a substantially higher price, part of a rising trend in prices per token.
What’s new: Google launched Gemini 3.5 Flash, an update of its mid-tier multimodal model. The new version offers improvements in agentic capabilities, visual understanding, and speed at a price three times that of its predecessor Gemini 3 Flash.
- Input/output: Text, images, audio, video in (up to 1 million tokens), text out (up to 64,000 tokens, 204 tokens per second)
- Architecture: Mixture-of-experts transformer
- Features: Adjustable reasoning levels (minimal, low, medium, high), thought preservation (which holds reasoning tokens in the context to retain reasoning across multi-turn conversations, similar to Kimi K2.6’s preserved thinking feature), tool use (computer use not yet available)
- Performance: Tops Artificial Analysis’s APEX-Agents-AA benchmark and MMMU-Pro multimodal benchmark Flash; trails leading models on overall intelligence, knowledge, and coding
- Availability/price: Free via Gemini app, Google AI Studio, Google Antigravity (within a compute limit that refreshes every 5 hours up to a weekly limit), Google Search AI mode; Gemini Enterprise, Gemini Enterprise Agent Platform, API $1.50/$0.15/$9.00 per million input/cached/output tokens
- Undisclosed: Parameter count, training data and methods, architectural details
How it works: Google disclosed few details about how it built Gemini 3.5 Flash.
- Gemini 3.5 Flash is “based on” Gemini 3 Flash, which itself is based on Gemini 3 Pro, according to its model card.
- It’s a mixture-of-experts transformer that was multimodally pretrained on text, code, images, audio, and video scraped from the web alongside licensed materials, Google user data, and synthetic data.
- It was fine-tuned via reinforcement learning on datasets that covered multi-step reasoning, solving problems, and proving theorems.
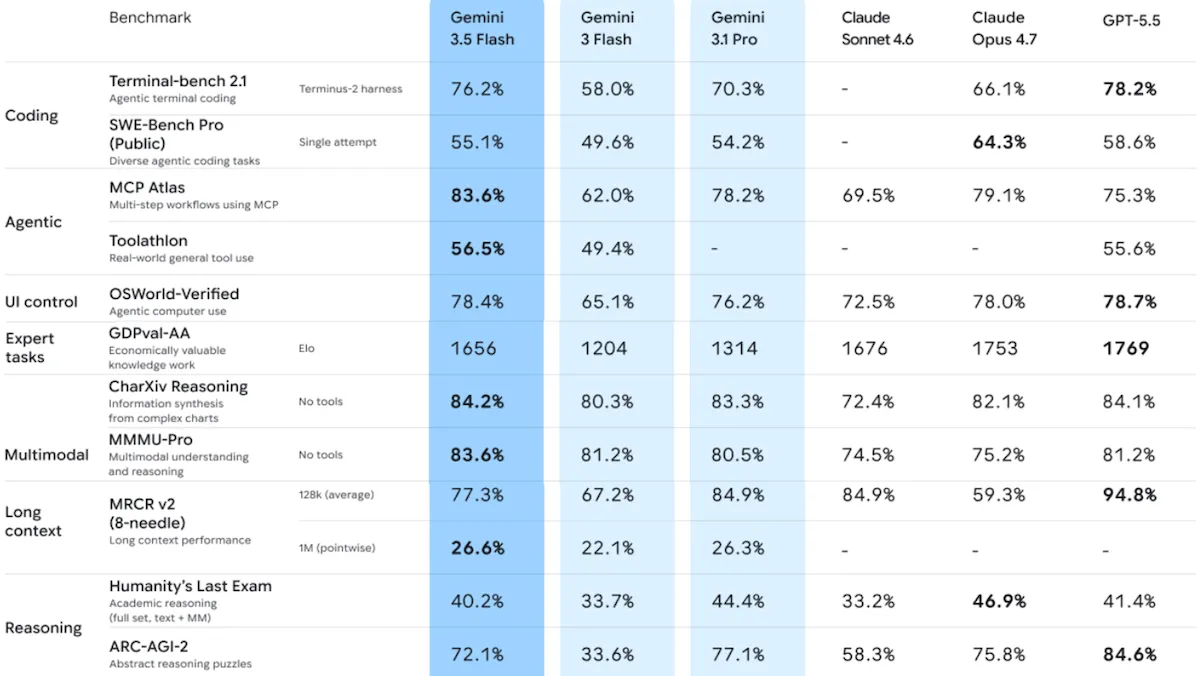
Performance: Gemini 3.5 Flash performs just behind the first rank of multimodal models. It makes substantial gains over its predecessor in agentic capability and speed according to independent tests, including some state-of-the-art measures. On the Artificial Analysis Intelligence Index, it came in either fifth or seventh (depending on the reasoning levels of various models) behind Qwen 3.7 Max set to reasoning (level unspecified), but — except Qwen 3.7 Max, which debuted the same week — every model that scores higher on intelligence runs substantially slower.
- According to Artificial Analysis, on MMMU-Pro, which measures visual reasoning across multiple academic disciplines, Gemini 3.5 Flash set to high reasoning achieved 84 percent accuracy, the highest recorded, with Gemini 3.1 Pro Preview (82 percent) in second place.
- On APEX-Agents-AA, which tests long-running agentic tasks drawn from investment banking, management consulting, and corporate law, Gemini 3.5 Flash (47.1 percent accuracy) took the top spot on the first attempt, nearly 10 percentage points ahead of second-place GPT-5.5 (37.7 percent accuracy). On GDPval-AA (real-world agentic tasks), Gemini 3.5 Flash set to high reasoning (1,656 Elo) exceeded Gemini 3.1 Pro Preview set to an unspecified level of reasoning (1,314 Elo), and behind GPT-5.5 set to xhigh (1,769 Elo).
- On ARC-AGI-2 (a test of abstract visual reasoning), Gemini 3.5 Flash set to high reasoning scored 72.1 percent on the ARC Prize leaderboard, behind Gemini 3.1 Pro Preview (77.1 percent) and GPT-5.5 set to xhigh reasoning (85.0 percent).
- On AA-Omniscience, a knowledge benchmark that awards points for correct answers and penalizes hallucinated guesses, Gemini 3.5 Flash set to reasoning (23) trails Gemini 3.1 Pro Preview set to reasoning (33) and Claude Opus 4.7 set to max reasoning (26).
- As of May 24, 2026, on Arena.ai’s leaderboards, which rank models in blind head-to-head human comparisons, Gemini 3.5 Flash ranked ninth in the Text Arena (1,480 Elo) and tenth in the WebDev coding arena (1,506 Elo). Anthropic’s Claude Opus 4.6 and 4.7 models occupy the top three positions in both arenas. Within the Text Arena’s category breakdowns, Gemini 3.5 Flash ranked first (1,521 Elo) in math but 31st in coding (1,507 Elo).
Behind the news: Google debuted Gemini 3.5 Flash at Google I/O 2026, its annual gathering for developers. Here are other AI-related announcements from that event:
- Google overhauled Antigravity, its AI coding tool, to emphasize managing agents and de-emphasize its resemblance to popular IDEs like Microsoft’s VSCode. Antigravity’s command-line version replaces the open-source Gemini CLI.
- The company introduced Omni, a family of multimodal models, beginning with Omni Flash, a lightweight model that can generate video from text, image, audio, and video, or any combination of these inputs. Omni Flash is available to Google AI Plus, Pro and Ultra subscribers through the Gemini app and Google Flow, but not yet in the API.
- Gemini 3.5 Flash enables Google Search to permit more conversational, chatbot-like search queries, power agents to do online research on users’ behalf, and replace Search’s traditional ten top links with more AI-generated summaries that answer users’ questions with cited sources.
Why it matters: Gemini 3.5 Flash changes what “Flash” means. Introduced as a smaller, faster model tier after Gemini Ultra, Pro, and Nano, for now, Flash is Google’s mid-tier multimodal model, more akin to Anthropic’s Sonnet than Haiku. The model’s speed may be worth the additional tokens it generates for developers who build agents that require multiple turns as well as low-latency applications like chatbots, search, and image and video analysis.
We’re thinking: Google said Gemini 3.5 Flash often runs at less than half the cost of competing models. But Artificial Analysis found that, running the tests in the Intelligence Index, it actually costs more than Gemini 3.1 Pro. The Flash designation no longer implies a clear cost advantage for developers who run agentic workloads. Anthropic, OpenAI, and Google have raised per-token prices on their newer flagship and Flash-tier models. Gemini 3.5 Flash fits the pattern.

Europe Pauses Some AI Regulations
The European Union weakened some provisions of its landmark AI Act and delayed others after businesses and policymakers argued the law made European companies less competitive.
What’s new: The European Parliament and member states agreed to amend the AI Act to delay restrictions that target applications the union considers to pose significant threats to safety, health, or individual rights, among other changes. The amendments await formal adoption by the union’s council and parliament. The EU characterized the amendments as “safer and simpler rules for both citizens and businesses.”
How it works: The amendments generally streamline the EU AI Office’s oversight and enforcement responsibilities. They also extend deadlines for AI developers to comply with certain provisions and simplify others.
- Requirements for AI systems deemed to be “high-risk” — including those used in law enforcement, critical infrastructure, employment, migration, and personal identification — are delayed to December 2027 from a previous deadline of August 2026. They would give developers until August 2027 to implement supervised sandbox environments to isolate new models from the wider world during testing. They would also extend deadlines for AI-driven products including machinery and toys until August 2028 and for watermarking of AI generated output and other transparency requirements to around December 2026.
- The revisions would adjust the ways personal data can be used in training and deployment of AI systems. Under existing EU law, some categories of personal data can be used only when “strictly necessary.” The revisions would allow for personal data to be used to detect and mitigate bias.
- They also carved out or clarified exemptions for some products. For instance, the AI Act would not affect industrial machinery, which is already regulated by product-safety laws. Further, lighter compliance requirements and administrative burdens would apply in some cases to smaller companies (fewer than 50 employees with either annual worldwide revenue up to €10 million or total assets up to €10 million) and “small mid-cap” companies (roughly between 250 and 749 employees with either annual worldwide revenue up to €150 million or total assets up to €129 million).
- The amendments strengthen the AI Act in one notable area: They ban generation of sexually explicit images of children and non-consensual nude images of real people.
Behind the news: In 2024, the EU passed the world's most stringent law to regulate AI. The law entered into force the same year, with certain provisions to be phased in over subsequent years. It was criticized as imposing unreasonable burdens without improving safety virtually from the moment the legislative process began.
- In 2023, executives at 163 companies signed a letter that argued the legislation was “bureaucratic.” In 2025, 110 companies urged policymakers to postpone the implementation timeline writing because the regulations were “unclear, overlapping and increasingly complex.” Companies such as German industrial and software firms Siemens and SAP lobbied for revisions, saying that regulations were holding them back.
- Two early reports influenced the amendments. A report published in April 2024 by Enrico Letta, Italy’s former Prime Minister, argued that the EU was fragmented into 27 national markets that prevented European firms from scaling the way American and Chinese companies can. A September 2024 report about Europe’s competitiveness framed the region’s stagnating GDP growth as an “existential challenge” and focused on closing the innovation gap, decarbonization, and reducing dependencies.
- In early 2025, the European Commission — the executive arm of the EU — announced its intention to reduce regulatory burdens, simplify rules, and boost economic competitiveness.
- In February 2026, the European Commission withdrew its proposed AI Liability Directive, a controversial proposed law, separate from the AI Act, that would have introduced EU-wide standards for lawsuits over AI-induced harms.
The public responds: Immediate reaction to the amendments was mixed. The AI industry generally welcomed the added flexibility while consumer groups expressed concern over the potential weakening of safety standards. Some media reports framed them as watering down the law to appease business interests. The European Consumer Organization said the deal makes the digital environment less safe and creates dangerous loopholes for AI companies.
Why it matters: In both its original and updated forms, the AI Act aims to mitigate AI-induced “systemic risks,” a concept borrowed from finance and infrastructure regulation that refers to failures capable of rippling across industries or large parts of the economy. The idea that AI poses systemic risks remains speculative, whereas overregulation poses the economic risk of stifling innovation and blocking beneficial technology. The revisions aim to balance risks and benefits by easing burdens on developers, giving companies additional runway to understand and comply with requirements, and clearing the way for ongoing innovation in critical industries such as manufacturing and semiconductors.
We’re thinking: Many provisions of the original AI Act were unclear, overly broad, or unnecessarily burdensome. These revisions appear to make the law less burdensome while retaining helpful elements. This is a good step for European competitiveness.
Agents Surf the AI-Written Web
AI-driven activity on the internet rose sharply last year, a study shows.
What happened: AI-driven traffic, or internet interactions that were generated by or on behalf of AI systems, nearly tripled in 2025, according to a report by the cybersecurity firm Human Security. The volume of activity by crawlers that collected data en masse to train AI systems and bots that scraped data points such as prices for immediate use multiplied by single digits. Traffic by AI agents and agentic browsers ballooned (although it remained a tiny percentage of the total). More than 95 percent of AI-driven traffic involved activities the authors designated retailing and ecommerce, streaming and media, or travel and hospitality.
How it works: The 2026 State of AI Traffic and Cyberthreat Benchmark Report is based on an analysis of over 1 quadrillion internet interactions observed in 2025 by Human Security, which serves around 1,200 customers in more than 200 countries and territories.
- AI-driven traffic nearly tripled, while automated traffic, which includes both AI-driven and conventional bot traffic, grew more than 23 percent. Human traffic grew by around 3 percent.
- The rise in AI-driven traffic includes crawlers that collect training data (68 percent of AI-driven traffic for the year, more than 2x the previous year’s volume), scrapers that collect data for immediate use (32 percent for the year, a 7x increase in volume), and agents that execute browser-style tasks (1.7 percent in December, nearly 80x growth year over year).
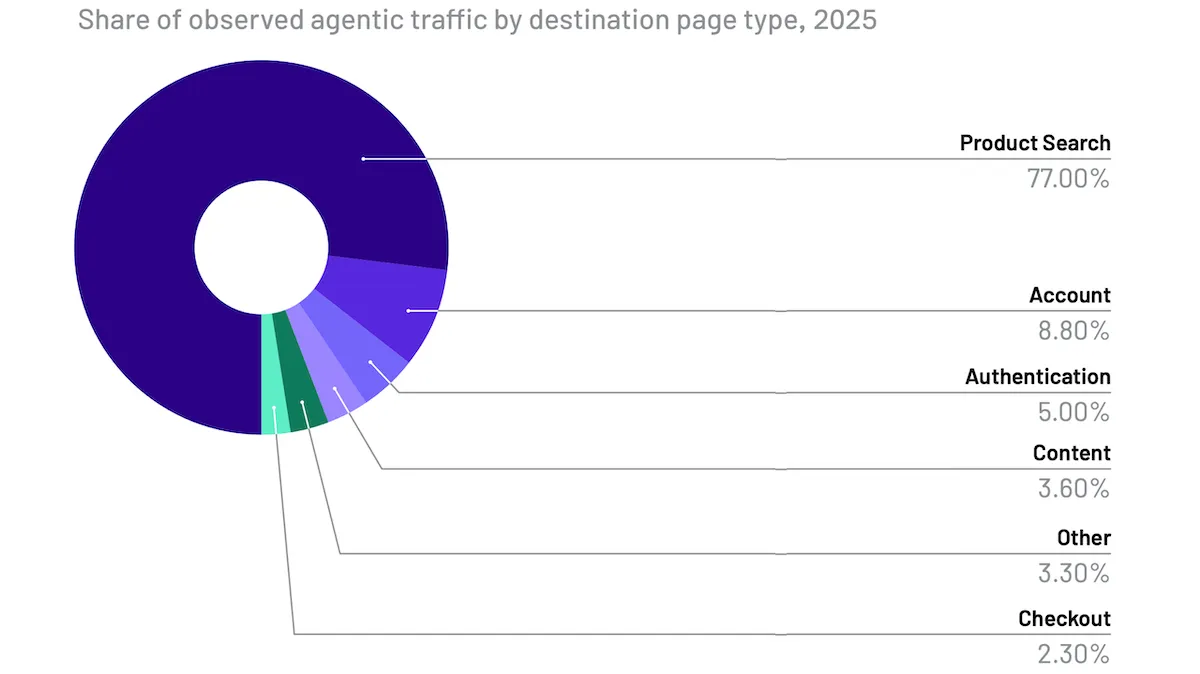
- Of the agentic interactions, 77 percent took place on product and search pages. The rest involved account pages, authentication, and completing transactions, in that order.
- OpenAI was responsible for around 69 percent of automated traffic, including ChatGPT users and crawlers that collect training data (OAI-SearchBot) and timely information (GPTBot). Meta accounted for 16 percent, and Anthropic initiated around 11 percent.
Security implications: The researchers deemed a significant amount of the automated traffic malicious.
- Scraping activity that the authors deemed malicious, aiming to extract data for purposes such as competitive intelligence or systematic underpricing rather than aiding AI-driven interactions, rose nearly 47 percent from the prior year. (The authors labeled traffic malicious if the scraper spoofed its identity, followed a recognized attack pattern, or otherwise behaved in a suspicious manner.) Of the 750,000 threat profiles identified by the researchers, more than 60 percent were involved in malicious scraping.
- Attacks in which a bot attempted to take over a user account fell by more than 30 percent over the year. However, the remaining attempts showed a 4x increase in attacks that occurred after an account was logged in. Although such attacks often took advantage of existing accounts via stolen credentials or hijacked sessions in progress, the number in which an agent created the account rose by 89 percent from the prior year.
- The percentage of transaction traffic that involved a compromised payment card was “low and stable,” but the volume that was blocked by the card issuer rose by 20 percent. This may reflect a rising number of transactions executed on the Internet, an increased ability of agents to cycle through card numbers, or both.
Yes, but: The report analyzes only activity on Human Security’s platform, not the internet as a whole. Moreover, malicious traffic often misrepresents its origin, so the researchers’ evaluation of any given data point may be mistaken.
Why it matters: Autonomous systems are flooding the internet with a rising tide of additional traffic, and its likely this trend will continue in the foreseeable future. Infrastructure must be built or upgraded with this in mind. The rise in automated activity also poses challenges for cybersecurity because legitimate AI agents perform many of the same activities — browsing products, creating accounts, and checking out of transactions — that previously signaled malicious bots.
We’re thinking: Agentic traffic on the internet is just getting started. The 80x rise last year is bound to multiply further in coming years as agents become more capable, robust, and trustworthy.
Planning Generated Images In Stages
Text-to-image generators that use diffusion or flow-matching typically compose a whole image at once (although they refine the whole image in steps). Researchers got better results by breaking image composition into discrete stages, then checking and revising interim results.
What’s new: Lei Zhang and colleagues at Meta, University of California San Diego, Worcester Polytechnic Institute, and Northwestern University proposed a fine-tuning method for image generators that trains a model to compose images by planning, generating an element, checking whether it matches the prompt, correcting if necessary, generating another element, and so on.
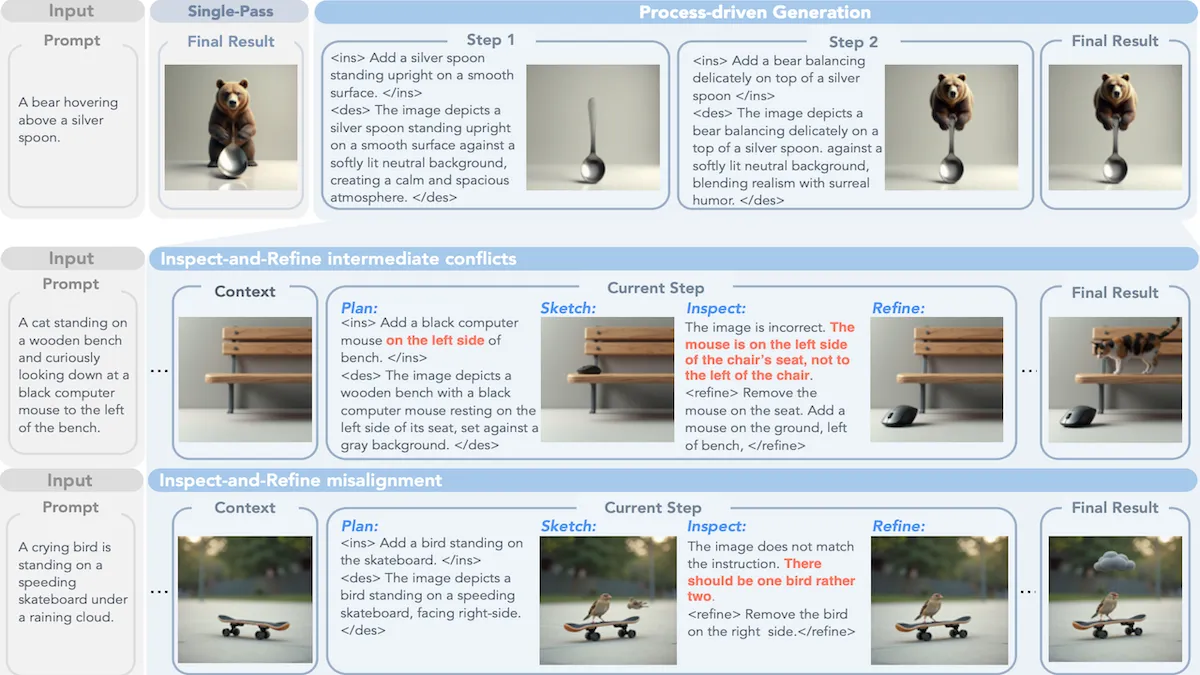
Key insight: Text-to-image models often fail to represent spatial relationships (such as whether one element is above, below, in front of, or behind another) and object attributes (such as numbers of fingers, arms, or legs). The generation process becomes easier to control when the model learns to complete the image by looping through a staged process. Given a prompt like “a bear hovering above a silver spoon”, the stages can be:
- Plan. Write an instruction for the next change to be made (iteration 1: “draw a bear”; iteration 2 “add a spoon under a bear”; and so on) and a description of the image after the change.
- Sketch. Generate an updated version of the image so far (iteration 1: an image of a bear; iteration 2: the bear and a spoon).
- Inspect. Check the instruction and the description against the prompt, and check the image against the instruction.
- Refine. Issue a command to correct it if needed (iteration 2: “the spoon was in front of the bear, draw it under the bear”) and produce a new image.
Training on data that represents this process can teach the model not only to generate an image based on a prompt but also to build up the image composition and correct it.
How it works: The authors started with BAGEL-7B, a pretrained multimodal model that takes images and text (say, two images and an instruction to combine them) and produces images and text (say, the combined image and a description of how the input image was changed). They fine-tuned it to generate images by cycling through stages to plan, sketch, inspect, and refine the composition.
- Fine-tuning to plan and sketch: To create a dataset for fine-tuning the plan and sketch stages, the authors generated 32,000 examples, each containing about three to five intermediate images and a final image. They did this by prompting GPT-4o to transform prompts from two datasets into text-based scene graphs. The graph nodes were objects (for example, “cat” or “bear”) or attributes of objects (“furry”), and edges encoded relationships between them (a cat “is” furry). From each graph, they randomly selected parts that contained objects, attributes, and relationships. They asked GPT-4o to turn the parts into incremental prompts to add those objects, attributes, and relationships to an image. They generated an image for each incremental change using FLUX.1 Kontext and kept only results that GPT-4o deemed consistent with the incremental prompts. The authors fine-tuned the model on the text-image examples. The model learned (i) to generate the next text tokens of the examples and (ii) to generate the next image by adjusting the pixel values of the current image over several flow-matching steps.
- Fine-tuning to inspect: To produce a dataset for fine-tuning the inspect stage, they used the model after fine-tuning to plan and sketch, they generated examples of incremental instructions and images and then asked GPT-4o to judge whether an intermediate text description conflicted with the original prompt. Finally, they prompted GPT-4o to produce critiques and corrective instructions. The authors produced nearly 7,000 examples that stayed consistent with the original prompt and nearly 8,300 inconsistent examples. By learning to reproduce the GPT-4o critiques and instructions, the model learned to either accept the current plan as consistent with the original prompt or describe how to fix inconsistencies.
- Fine-tuning to refine: The authors fine-tuned the model on a dataset of images, text reflections about how an image can be improved, and improved images.
- Finally, they fine-tuned the model on all three datasets together using the same loss terms as before.
Results: The authors’ fine-tuning method improved BAGEL-7B on tasks that require generating images in which object relationships match a text prompt (for example, placing a bear on a spoon instead of behind a spoon). It also improved BAGEL-7B’s ability to generate images based on real-world knowledge, such as scenes of a particular time of day or historical era.
- On GenEval, which measures the percentage of details mentioned in a prompt that appear in the resulting generated image, the authors’ method raised BAGEL-7B from 77 percent to 83 percent after fine-tuning on 62,000 examples; it used 131 flow-matching steps. In contrast, PARM, a method that improves image-generation by critiquing intermediate noisy diffusion states, achieved 77 percent after fine-tuning on 688,000 examples; PARM used 1,000 flow-matching steps.
- On WISE, which uses GPT-4o to rate realism, aesthetic quality and consistency between a generated image and its prompt (0 to 1, higher is better), the method raised BAGEL from 0.7 to 0.76 on average. The fine-tuned model more often placed scenes in the correct era or temporal context. Tested on a chemistry dataset, it more often generated chemically plausible structures, substances, and laboratory scenes.
Why it matters: Image generators frequently produce good-looking images, but their output is often at odds with the prompt. For instance, objects may be out of place and have the wrong attributes. This work offers a way to make such systems more dependable beyond simply scaling training data.
We’re thinking: An image generator that composes images in stages is analogous to an LLM that reasons over its input step by step. Both approaches direct the model to break down requests into pieces, and both improve the output.