RotorQuant vs TurboQuant — KVキャッシュ量子化の最前線
Qiita / 3/31/2026
💬 OpinionTools & Practical UsageModels & Research
Key Points
- RotorQuantとTurboQuantを比較し、LLM推論で重要なKVキャッシュ量子化(メモリ削減・高速化)における違いと適用観点を整理している。
- llama.cppなどローカルLLM/ローカル推論の文脈で、KVキャッシュ量子化が性能・品質に与える影響を中心に説明している。
- 量子化手法の選定が、実運用でのレイテンシ/スループット/VRAM使用量といったボトルネックに直結する点を強調している。
- 「最前線」として、現状の実装・使い分けの考え方(どのケースでどちらが有利になり得るか)を比較の軸として提示している。
title: "RotorQuant vs TurboQuant — KVキャッシュ量子化の最前線"
topics: ["LLM", "量子化", "ローカルAI", "機械学習", "Python"]
RotorQuant vs TurboQuant — KVキャッ...
Continue reading this article on the original site.
Read original →Related Articles

Black Hat Asia
AI Business

How to Verify Information Online and Avoid Fake Content
Dev.to
I built an AI code reviewer solo while working full-time — honest post-launch breakdown
Dev.to
Mobile App MVP: Build, Launch, and Validate in Under a Week
Dev.to
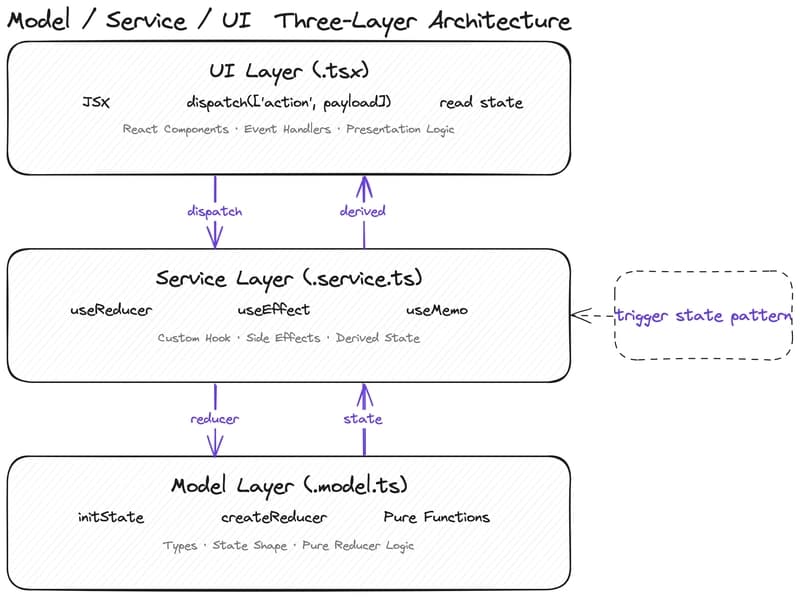
Why Your State Management Is Slowing Down AI-Assisted Development
Dev.to