 | Villain Sinister Laugh Grizzled Detective (Noir) Prompt: A muscular man speaks with a thick accent, panting heavily, completely out of breath, "Hah... hah... we made it, we actually made it." He coughs roughly, "Ugh, that was the hardest fight of my entire life, I swear." He groans and clutches his side, "Argh, my ribs, I think something is broken." But then a grin spreads and he laughs heartily despite the pain, "Hahaha! But we WON! Can you believe it? We actually won!" He takes a deep, shuddering breath, "I told you, heh, I told you we would make it. Ahhh, it is finally over." 45 second with stable output. [link] [comments] |
LTX-2.3 based audio model outputs
Reddit r/LocalLLaMA / 4/18/2026
💬 OpinionSignals & Early TrendsTools & Practical UsageModels & Research
Key Points
- The post shares example audio outputs generated using an LTX-2.3-based audio model.
- It includes several character-style voice prompts (e.g., a villain laugh, noir detective, talk show host) demonstrating different speaking styles and emotional tones.
- The examples focus on how the model renders voice acting qualities such as pacing, laughter, breath, gravelly delivery, and theatrical intensity.
- The overall takeaway is a practical showcase of multimodal/voice generation capabilities rather than a technical explanation or new release details.
Related Articles

Black Hat USA
AI Business

Black Hat Asia
AI Business

The myth of Claude Mythos crumbles as small open models hunt the same cybersecurity bugs Anthropic showcased
THE DECODER

Claude Opus 4.7 vs 4.6: What Actually Changed and What Breaks on Migration
Dev.to
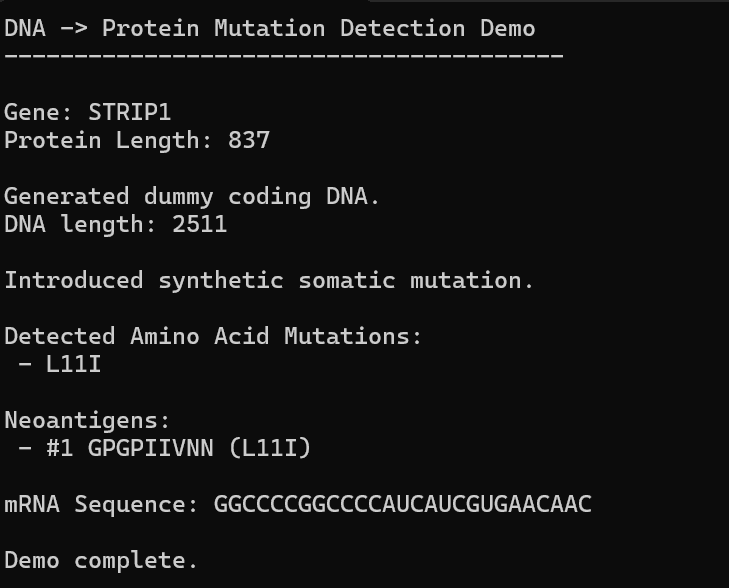
AI, Hope, and Healing: Can We Build Our Own Personalized mRNA Cancer Vaccine Pipeline?
Dev.to