KVSculpt: KV Cache Compression as Distillation
arXiv cs.LG / 3/31/2026
📰 NewsSignals & Early TrendsIdeas & Deep AnalysisModels & Research
Key Points
- KVSculpt targets long-context LLM inference by compressing KV caches beyond quantization/low-rank methods, focusing instead on reducing the effective sequence dimension.
- The method replaces eviction/merging of original KV entries with an optimization of a smaller set of unconstrained KV pairs in continuous embedding space to preserve layer-level attention behavior.
- Keys are optimized using L-BFGS while values are computed analytically via least-squares, alternating optimization steps to make the procedure practical.
- Adaptive budget allocation uses a pilot compression run to reallocate the compression budget across layers and KV heads based on their per-component difficulty.
- On Qwen2.5-1.5B-Instruct at 2048-token contexts, KVSculpt cuts KL divergence by 3.5–4.1x versus Select+Fit across compression ratios, with an additional 1.3x improvement from adaptive allocation without extra inference cost.
Related Articles

Black Hat Asia
AI Business

How to Verify Information Online and Avoid Fake Content
Dev.to
I built an AI code reviewer solo while working full-time — honest post-launch breakdown
Dev.to
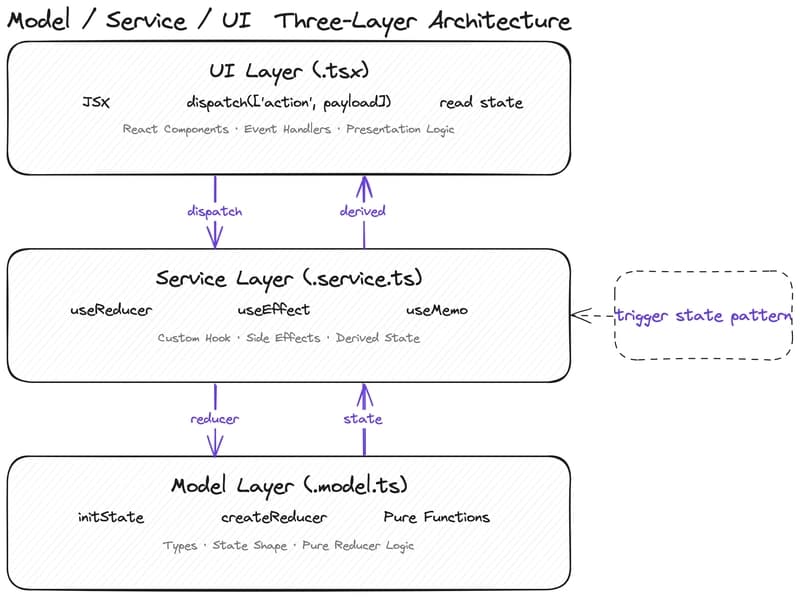
Why Your State Management Is Slowing Down AI-Assisted Development
Dev.to
Google Stitch vs Claude: Which AI Design Tool Wins in 2026?
Dev.to