
M1 MaxでQwen3.6を使ってみた(動画つき)

話題のQwen3.6が試しに使ってみたら思ったより凄そうなのでnoteします👨💻
Qwen3.6 35Bがたった24GBでもClaude Code代替になる!と話題です。が、実際に使っているの?という記事が多く利便性の真偽がわからなかったので、手元にある mac studio(M1)で試してみました。
(結論)
M1 Max 32GBスペックでも実用レベルで使える。
17GBのモデルでもOK
外部接続のAI禁止なプロジェクトで外注作業なら全然あり
M5ならもっと幸せそう
オープンソース・ローカルなので安心安全
です。
試したモデルは27b(17GB)、35b(24GB) ですが、ネットで調べてもコーディングだとさほど差は出ないらしいです。また27bの性能は2年前のChatGPT以上、というのがもっぱらの評価です。
利用法はLM Studioなら選ぶだけ、コマンドラインollamaの場合は以下のような手順でした。(不要な方は中盤の性能比較動画へお進みください)
インストール
無駄かなとは思いましたが、自分の環境では最初GPU(metal)が動かず、intelモードになっていたのが理由だったので一応,インストールについてこちらにメモっておきます。
💻最初に使ってみたときには激遅でm1では無理か〜、諦めましたが後で確認したらGPUが使われていませんでした。
> ollama ps
NAME ID SIZE PROCESSOR CONTEXT UNTIL qwen3.6:27b a50eda8ed977 22 GB 100% CPU 4096 4 minutes from nowARM版で明示インストール
しらべたらintel版がインストールされる罠でした。削除します。
brew uninstall ollama
rm /usr/local/bin/ollama正しいインストール
$ /opt/homebrew/bin/brew install ollama
$ file $(which ollama)
arm64サーバー実行
killall ollama
ollama serveModelfile
FROM qwen3.6:27b
SYSTEM """
日本語で簡素に回答して。
コードの場合はコードだけ出力しろ。
"""
PARAMETER temperature 0カスタムモデルの準備
ollama create qwen-ja -f ./Modelfile実行
ollama run qwen-ja 結果:
1分弱で rust の grepコードを出してくれました。
試したときにはどちらも同じくらいのスピードでした。
性能比較(コード生成)
27B (22GB)の生成動画
35B (27GB)の生成動画
35Bのほうが親切な出力が出ていますが時間的には同じくらいです。
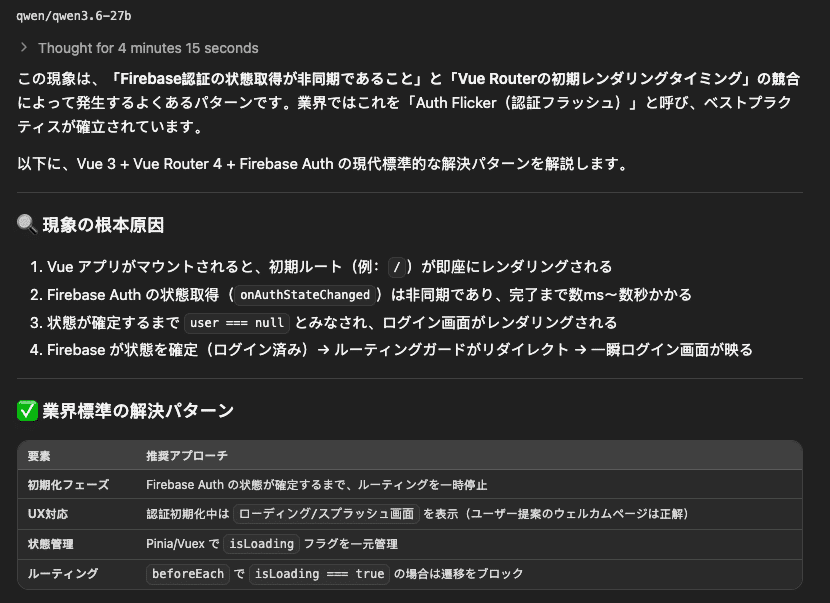
技術的な解決の場合
SaaSアプリなどで起きるAuth Flicker(認証フラッシュ)の問題解決について、Qwen3.6(27b)と Cursor (pro, planモード)に質問した所、同様の回答が得られました。提案のコードもだいたい同じで的を射たものでした。
質問では、「回避方法(繋ぎのviewを追加)を示し、このケースのVueでのベストプラクティスと比較して、実装すべき解決方法を検討しろ」というちょっと複雑なものでしたが、どちらも以下のような方向での解決をする回答でした。
M5 Maxでではどんな?
こちらの動画ではMacBook Pro M5でテストしています。3:20ぐらいのところでSVGの生成をするM5 Maxの実働の雰囲気が確認できます。
この動画でロゴ生成を命じたあとの思考時間と生成で5秒以下です。 同じ条件で試していなので参考程度ですが、同じプロンプトでM1 Maxに命じてみた所、思考だけで15秒以上かかりました。生成時間も数十秒かかりましたので、M5 Maxは驚くべきパフォーマンスです。
Quan3.6はClaude Opus4.5並の仕事をするという触れ込みなので、コーディングなど仕事で使うならそれほど高い投資ではない気がします。
あ、やっぱり高いですね…ノートだとサーマルスロットリングが発生し、長時間利用はよろしくないかもですし、ふつうに有料でClaude使うほうがまだコスパはよいのかも。とはいえ日本の職場だと機密性は絶対ですので、ローカルで動くというのは分割不能な価値があることも事実です。
残念ながら メモリ不足から?Mac Studio M5が延期になり発売日は未定のようで、発売が待たれます。
少額減価償却資産が40万円未満へ拡大!
会社の経費で買う時に気になるのは単に価格の大小だけでなく、償却になるかどうかです。インフレと円安が進み、少し前に小額減価償却が20万円から30万円となったと思ったら、なんと今年は40万円になりました。 Mac Studio M5の予想価格は値上がりしベースモデルで約35万円〜40万円台と予想されていますので、事業者の場合は一括償却で購入出来る可能性があります。
この拡大はアベノミクスで円の価値を半分にして国民の資産を半減させたので当たり前の措置ですが、ボロボロになった円では40万円はドルではたった$2500であり、欧米のアルバイトの月給の1/2~2/3ほどの価値しかありません。 政府がAI利用の効率化を推奨するのであれば助成金をする以前に、ドル建ての商品であるAI用ハードの購入を考慮した60万程度に拡充して欲しいところです。
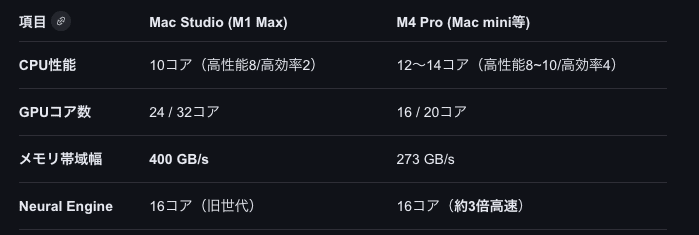
M1 Maxが未だに現役な理由
Mac Studio M1は2022年3月の発売で満4歳。 M4世代が出てからは流石に?と思いましたが、普段は全く不満ありませんで、mac mini M4をゲットしたあとも便利にこちらを使っています。
とくに今回のような用途ではメモリ帯域400GB/sの というのが実行力に貢献しているようです。
動画編集のエクスポートも M4と比べるとそこまで差が出ず、Qwenの実験動画でもわかるようにいまだ頼りになる馬鹿力は健在です。
大は小を兼ねる、ですね
メモリ不足とLLM用途で需要が上がったのでしょう、Mac Studioの整備品や中古は品薄で値段もかなり上がっているようです。
オンライで試したい方や,より高性能なplusやMAXこちらはアリババの有料サービスから提供されています。
nVidiaならこちらを使うとより早く動くようです。
いいなと思ったら応援しよう!
 サポートありがとうございます😊 ベトナムにお越しの際はお声がけくださいね🌻
サポートありがとうございます😊 ベトナムにお越しの際はお声がけくださいね🌻


