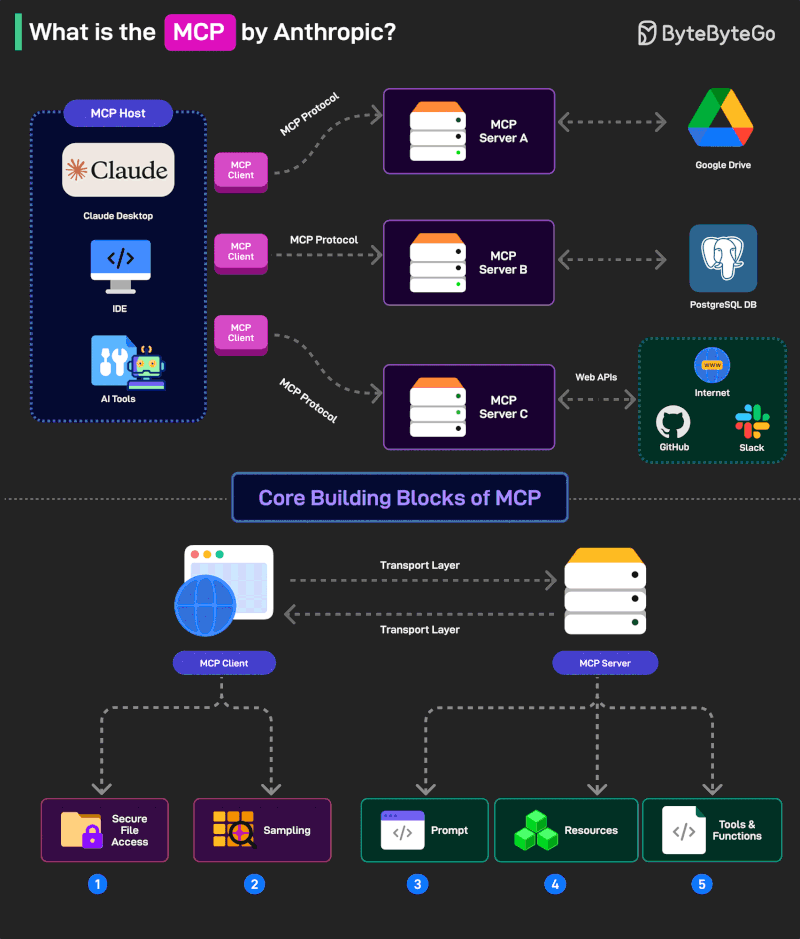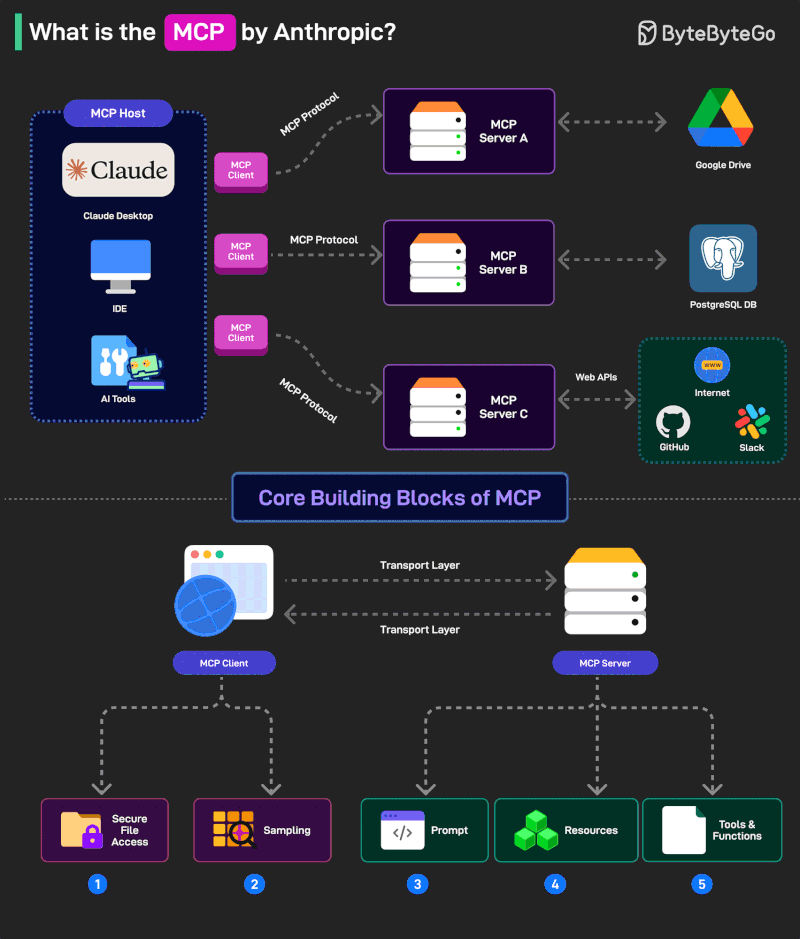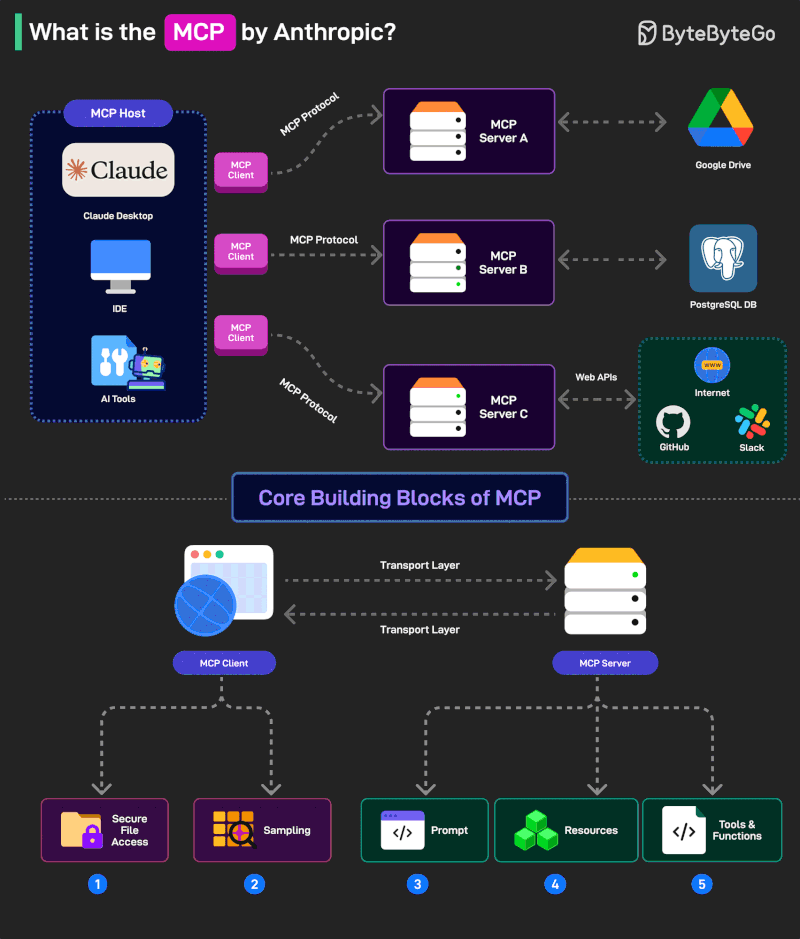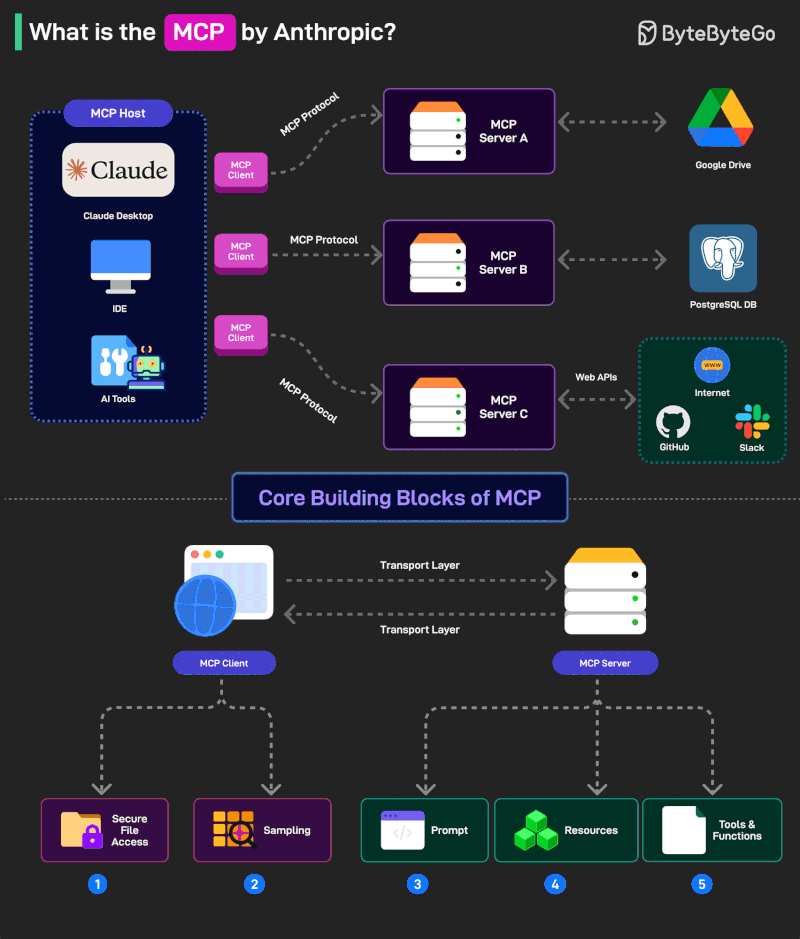
AdaFuse: トークンレベルの事前ゲーティングと融合カーネル最適化による動的アダプタ推論の高速化
arXiv cs.AI / 2026/3/13
📰 ニュースDeveloper Stack & InfrastructureModels & Research
要点
- AdaFuseは、動的アダプタのレイテンシのボトルネックがコア計算自体ではなく、断片化されたCUDAカーネル起動によるオーバーヘッドにあることを示す。
- トークンレベルの事前ゲーティング戦略を導入し、すべてのアダプタ層に対して単一のグローバルなルーティング決定を行い、トークンごとの実行パスを実質的に固定する。
- これにより、選択されたすべてのLoRAアダプタをバックボーンモデルへ1回の効率的なパスで統合する融合CUDAカーネルを実現できる。
- 人気のあるオープンソースのLLM上の実験結果は、最新のダイナミックアダプタと同等の精度を維持しつつ、デコードレイテンシを2.4倍超削減することを示した。
- 本研究は、推論効率を向上させつつモデル能力を損なわないハードウェア–ソフトウェア共設計アプローチを示している。
Mixture-of-Experts(MoE)のような動的で疎な構造と、LoRA などのパラメータ効率的アダプタを組み合わせることは、Large Language Models(LLMs)を強化する強力な手法である。しかしながら、このアーキテクチャの強化には大きな代償が伴う。計算負荷の増加はごくわずかであるにもかかわらず、推論レイテンシはしばしば急増し、デコード速度は2.5倍以上遅くなる。細粒度の性能分析を通じて、主要なボトルネックは計算自体ではなく、従来の動的ルーティングに必要な断片化された逐次 CUDA カーネル起動による深刻なオーバーヘッドであることを特定した。これに対処するため、AdaFuseを導入する。アルゴリズムと基盤となるハードウェアシステムとの緊密な共設計に基づくフレームワークとして、動的アダプタの実行を効率化する。従来の層ごとまたはブロックごとのルーティングから離れ、AdaFuseはトークンレベルの事前ゲーティング戦略を採用し、トークンを処理する前にすべてのアダプタ層に対して単一のグローバルなルーティング決定を行う。この「一度決定、全てに適用」というアプローチは、各トークンの実行パスを実質的に静的化し、全体的な最適化の機会を生み出す。これを活かして、選択されたすべての LoRA アダプタのパラメータをバックボーンモデルへ1回の効率的なパスで統合する融合スイッチング演算を実行するカスタム CUDA カーネルを開発した。人気のあるオープンソースのLLMにおける実験結果は、AdaFuseが最先端のダイナミックアダプタと同等の精度を達成しつつ、デコードレイテンシを2.4倍以上低減することを示し、モデルの能力と推論効率のギャップを埋めている。