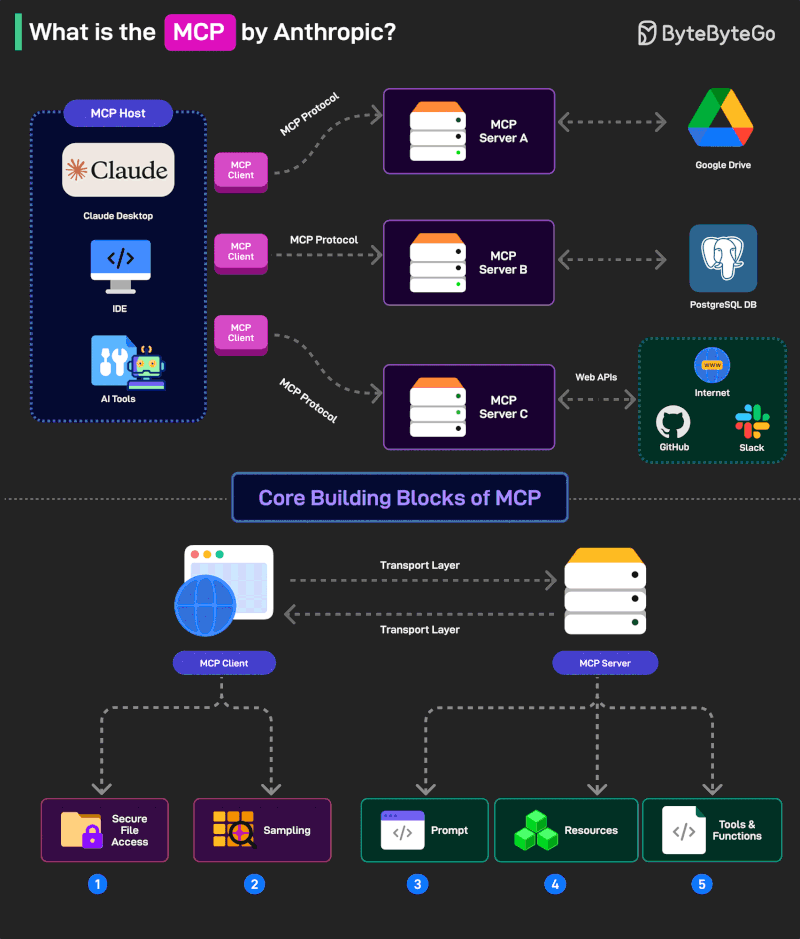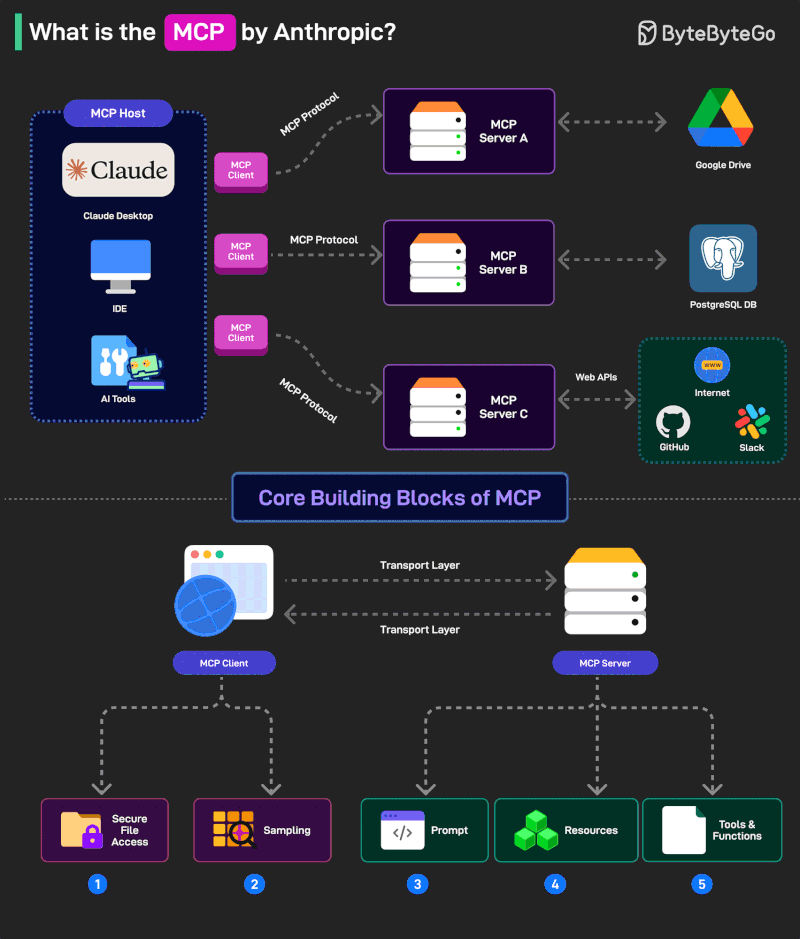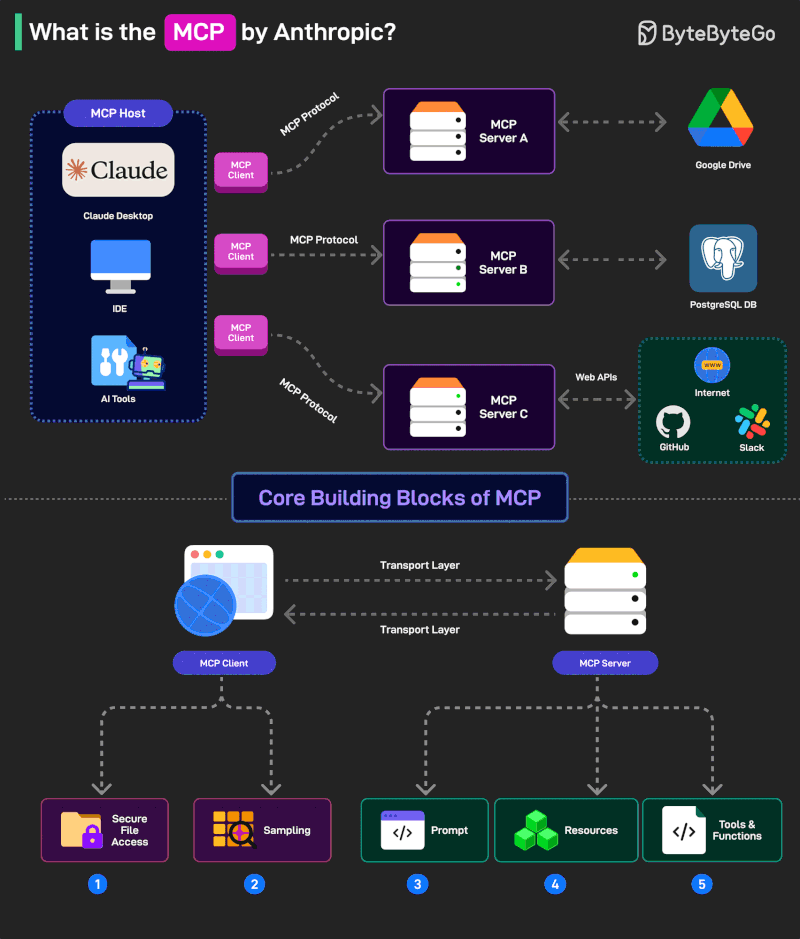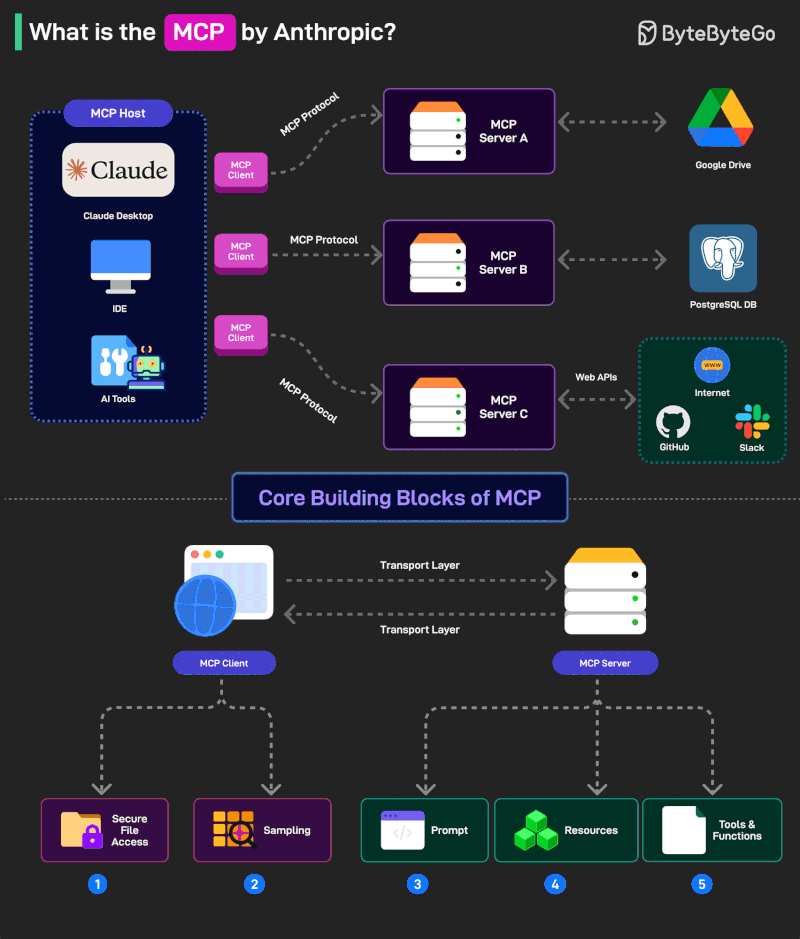
概要: 拡散ベースの大規模言語モデル(dLLMs)は双方向注意に依存しており、これによりロスレス KV キャッシュを妨げ、デノイジングの各ステップで全ての順伝搬計算を必要とします。既存の近似 KV キャッシング手法はキャッシュ状態を選択的に更新することでこのコストを削減しますが、その決定オーバーヘッドは文脈長やモデルの深さに比例して増加します。私たちは EntropyCache を提案します。これは訓練を必要としない KV キャッシング手法で、新しくデコードされたトークン分布の最大エントロピーを、再計算をいつ行うかを決定する定数コスト信号として使用します。設計は二つの経験的観察に基づきます:(1)デコードされたトークンのエントロピーは KV キャッシュのドリフトと相関し、キャッシュの陳腐化の安価な代理指標を提供します,(2)デコードされたトークンの特徴量の変動性はマスク解除後に複数のステップにわたって持続し、直近にデコードされたトークンの k 個を再計算する動機づけになります。スキップまたは再計算の決定は、文脈長とモデル規模に依存せず、1ステップあたり O(V) の計算だけを必要とします。LLaDA-8B-Instruct および Dream-7B-Instruct の実験は、EntropyCache が標準ベンチマークで 15.2\times-26.4\times の速度向上を達成し、思考過程ベンチマークで 22.4\times-24.1\times の速度向上を達成することを示します。競争力のある精度と、決定オーバーヘッドは推論時間のわずか 0.5\% に相当します。コードは https://github.com/mscheong01/EntropyCache に公開されています。
EntropyCache: 拡散型言語モデル向けのデコード済みトークンエントロピーに導かれた KV キャッシュ
arXiv cs.CL / 2026/3/20
📰 ニュースDeveloper Stack & InfrastructureModels & Research
要点
- EntropyCache は、拡散型言語モデル向けのトレーニング不要の KV キャッシュ手法を導入します。新たにデコードされたトークン分布の最大エントロピーを用いて KV キャッシュを再計算すべき時期を決定し、デノイズ処理の各ステップでのフォワードパス数を削減します。
- 本手法は、文脈長やモデル規模に依存せず、各ステップで O(V) の決定を実現し、キャッシュドリフトに効率的に対処します。
- このアプローチを動機づける2つの観察: デコード済みトークンのエントロピーが KV キャッシュのドリフトと相関すること、およびデコード済みトークンの特徴のボラティリティがマスク解除後も持続することが、直近にデコードされたトークンを数個再計算する正当性を与えます。
- 実験結果は、標準ベンチマークで 15.2x–26.4x のスピードアップ、Chain-of-Thought タスクで 22.4x–24.1x のスピードアップを示し、精度は競争力があり、推論時間のわずか 0.5% がオーバーヘッドに費やされます。
- コードは GitHub の https://github.com/mscheong01/EntropyCache に公開されています。