米Google(グーグル)のデータ圧縮技術「TurboQuant」が注目を集めている。生成AI(人工知能)に広く使われるメモリー「KVキャッシュ」を効率的に使えるようにするものだ。メモリーの需要が縮小するとの見方が市場に広がったことを背景に、米Micron Technology(マイクロン・テクノロジー)や米Sandisk(サンディスク)など、世界でメモリー関連銘柄の株価が一時急落した。TurboQuantの特徴やインパクトを、論文や識者の見方を基に探る。
TurboQuantに関する論文「TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate」は2026年、AIのトップカンファレンス「ICLR(International Conference on Learning Representations)」に採択され、同年3月24日に技術ブログを公開。一気に話題を集めた。論文そのものはGoogle Researchなどの研究チームが2025年4月に発表したものだ。

「KVキャッシュ」で計算時間を短縮し、「量子化」で効率化
まず、KVキャッシュと量子化について整理しておこう。今日のほとんどの生成AIは、入力トークンの情報を「Attention(アテンション)機構」と呼ばれる仕組みで集約し、次トークンを予測する。KVキャッシュは、Attention機構で計算した「Key(トークンの目印)」と「Value(トークンから得られる情報)」のセットを保持するキャッシュメモリーだ。予測のたびに計算する必要がなくなるため、計算時間を短縮できる。
ただし、大規模言語モデル(LLM)に長い文章を処理させようとすると、KVキャッシュのサイズが大きくなってメモリーを圧迫し、ボトルネックとなる恐れがある。そこでKVキャッシュを効率的に使うための研究が進められてきた。
効率化手法の1つが、実数を別の値に置き換えて簡略化する「量子化」である。実数をビットで厳密に表現しようとすると、ビット数が無限に必要となる。これでは扱うのが難しいため、量子化によって値を丸め、有限数の区間に近似させるというものだ。結果、現実的なメモリーサイズでLLMの処理を可能にする。
アルゴリズムはシンプル
TurboQuantはKVキャッシュを圧縮するため、(1)トークンを表すベクトルにランダムな回転行列をかける、(2)量子化の際の誤差を最小化する、というシンプルな2段階のアルゴリズムを採用している。
(1)の処理は「PolarQuant」アルゴリズムと呼ばれる。ベクトルの各成分は異なる分布を持っている。各座標に載っている情報量には大小があり、成分ごとにスケーリングが必要となり、メモリーのオーバーヘッドが生じていた。
この課題を解決できるのが、原点を中心にある行列を一定の角度で回転するという線形変換を表す「回転行列」だ。ベクトルにランダムな回転行列をかけて回転移動を実行すると、ベクトルの各成分の偏りが小さくなることが知られている。情報量がならされるため、成分ごとのスケーリングが不要になる。
ランダム回転を利用し、誤差を最小に
量子化においては、ビット数を減らしつつ、誤差をなるべく小さくしたいというニーズがあった。ビット数が多いと、より正確に表現できる一方、計算コストは大きくなる。ビット数を減らすと、情報を近似するので誤差がどうしても大きくなるというトレードオフの関係にある。
グーグルは「QJL(Quantized Johnson-Lindenstrauss)」と呼ばれる手法で誤差を最小化した。これが(2)のアルゴリズムだ。「Johnson-Lindenstrauss(JL)の補題」と呼ばれる、高次元のベクトルをランダムな射影によって距離を保ったまま低次元に写せる理論を応用している。
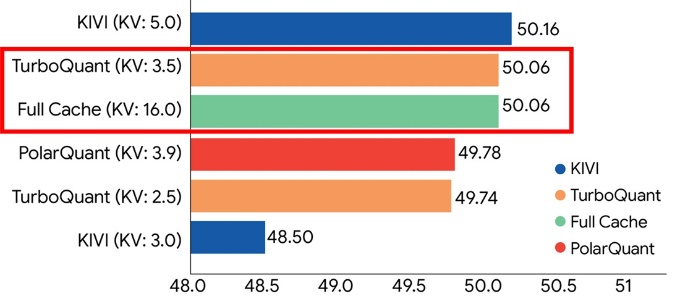
(1)と(2)の処理によってメモリーのオーバーヘッドが減り、精度を落とさず、処理を高速化できるとうたっている。「LongBench」と呼ばれるベンチマークでは、KVキャッシュを量子化していないモデルと同等の性能を維持しつつ、 最大4.5倍以上圧縮したとしている。
次のページ
専門家はどう見る?この記事は有料会員限定です




