
【完全解説】Claude Opus 4.7 降臨|SWE-bench 87.6%の衝撃と、Anthropicが"最強の座"を奪還した方法

📖 読了目安:約13分 | 📅 2026年4月19日 | 🎯 「ついにOpus 4.7が来た」──Anthropicが放った一手を、ベンチマーク・現場評価・競合比較で徹底解剖
🎯 この記事でわかること
AIモデル戦争、2026年4月第3週の勝者はAnthropicでした。
2026年4月16日、Anthropicは Claude Opus 4.7 を正式リリース。SWE-bench Verified で 87.6% を記録し、 GPT-5.4(未公表)とGemini 3.1 Pro(80.6%)を一気に突き放しました 。

この記事のサマリー:
🏆 SWE-bench Verified: 80.8% → 87.6% (+6.8pt の大幅飛躍)
🏆 SWE-bench Pro: 53.4% → 64.3% (GPT-5.4は57.7%、Gemini 3.1 Proは54.2%)
🏆 CursorBench: 58% → 70% (+12pt)
👁️ 画像解像度: 1.15MP → 3.75MP (3倍超)
⚡ 新モード「 xhigh 」追加(high と max の中間)
💰 価格据え置き: $5 / $25 per 1M トークン
⚠️ ただし トークン消費が1.0〜1.35倍 に増加(実質値上げの声)
この事件のポイント:
Opus 4.7 は「最強」の座を取り戻した。しかし、それは終わりではなく、次の戦争の始まりでもある。
なぜこの記事を読むべきか:
🎯 Claude ユーザーなら 今すぐアップグレードすべきか の判断材料が手に入る
🎯 GPT・Geminiユーザーなら 乗り換え検討 の比較データが揃う
🎯 企業導入担当者なら コスト vs 性能 の最新データで稟議が書ける
🎯 個人開発者なら Claude Code の新機能(xhigh) で開発効率が変わる
📖 目次
1. Opus 4.7リリースの全貌──4月16日、何が起きたか
⏱ この章:約2分 | 🎯 結論:Anthropicは「一般公開可能な最強モデル」の座を、わずか1週間で奪い返した
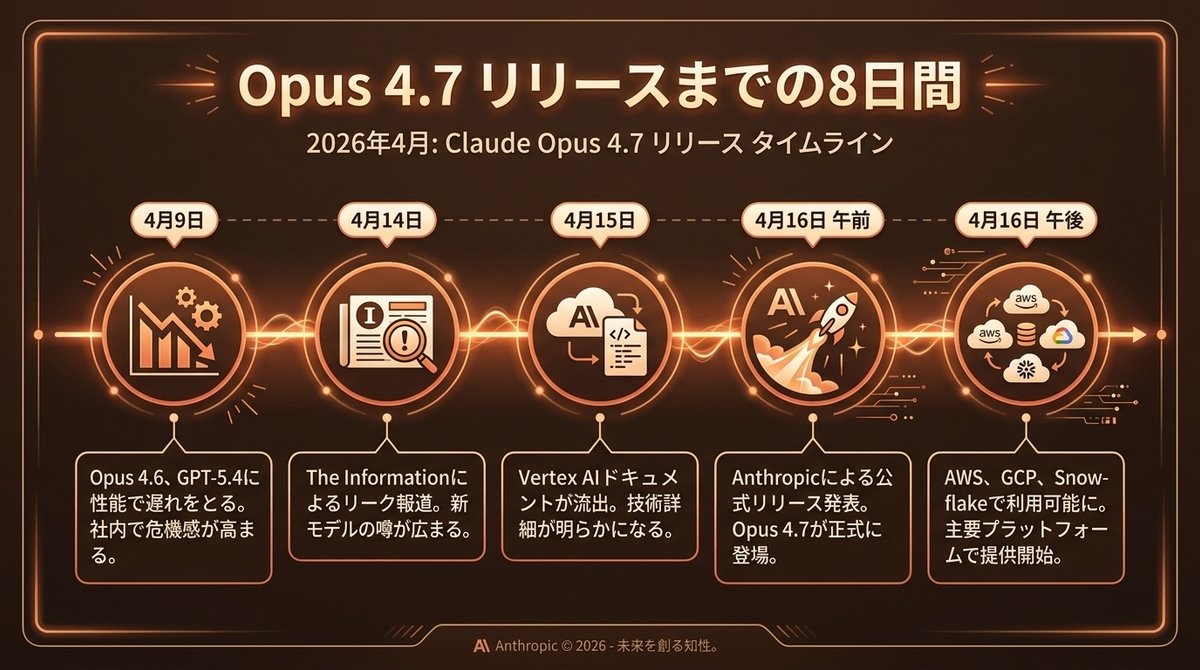
📅 リリースのタイムライン
結論:Opus 4.7は綿密に準備された"リターンマッチ"だった。
時系列で見る:
📅 2026年4月9日 ── Opus 4.6 がGPT-5.4にベンチマークで差をつけられる
📅 2026年4月14日 ── The Information がOpus 4.7のリークを報道
📅 2026年4月15日 ── Vertex AI ドキュメントに一時的に型情報が出現
📅 2026年4月16日 ── Anthropic公式リリース
📅 2026年4月16日 午後 ── 即日、AWS Bedrock / GCP Vertex AI / Snowflake で利用可能
わずか1週間 で準備から公開まで走り抜けた、戦略的なリリースでした。
🌐 対応プラットフォーム
結論:大手クラウド・開発ツールに同時展開、事実上「どこでも使える」状態に。
🟢 claude.ai (Pro / Max / Team / Enterprise プラン)
🟢 Anthropic API (直接アクセス)
🟢 Amazon Bedrock (AWS経由)
🟢 Google Cloud Vertex AI (GCP経由)
🟢 Microsoft Foundry (Azure経由)
🟢 GitHub Copilot (Pro+ / Business / Enterprise)
🟢 Snowflake Cortex AI (データ基盤)
3大クラウド+GitHub+Snowflake。4月16日のうちに、エンタープライズの主要経路すべてで使えるようになった。
💰 価格戦略──据え置きだが、実質値上げ?
結論:表面価格は変わらないが、新トークナイザーで消費量が増加している。
🟢 入力:$5 / 1M トークン (据え置き)
🟢 出力:$25 / 1M トークン (据え置き)
⚠️ ただし新トークナイザーで 同じテキストが1.0〜1.35倍 のトークン消費
実質的な値上げ幅:
英語テキスト: ほぼ変わらず (+0〜5%程度)
日本語テキスト: 約10〜20%増 (マルチバイト文字の処理変化)
コード: 15〜35%増 (記号類が細かく分割される)
🎯 この章のポイント
Opus 4.7 は 4月16日に3大クラウド+GitHubで即日利用可能
GPT-5.4 に抜かれてから わずか1週間 で反撃
価格据え置きだが、 実質は5〜35%値上げ (トークン消費増加)
2. ベンチマーク大解剖──87.6%が意味するもの
⏱ この章:約2分 | 🎯 結論:SWE-bench Verified 87.6%は「人間の中堅エンジニアと同等」を超える性能
📊 SWE-bench Verified とは何か
結論:GitHub の実在するバグ修正タスクを、AIが自律的に解けるかを測る"現場テスト"。
SWE-bench Verified の特徴:
🔬 実在するOSSプロジェクトの issue をそのまま使用
🔬 Python コード のバグ修正タスク
🔬 人間が検証済みの「解けるはずの問題」500問
🔬 ファイル複数跨ぎの修正 が必要な高難度タスクも含む
スコアの目安:
🔴 30%以下 :初心者プログラマー水準
🟡 50〜70% :中堅エンジニア水準
🟢 80%以上 :シニアエンジニア水準
🟣 90%以上 :トップエンジニア水準
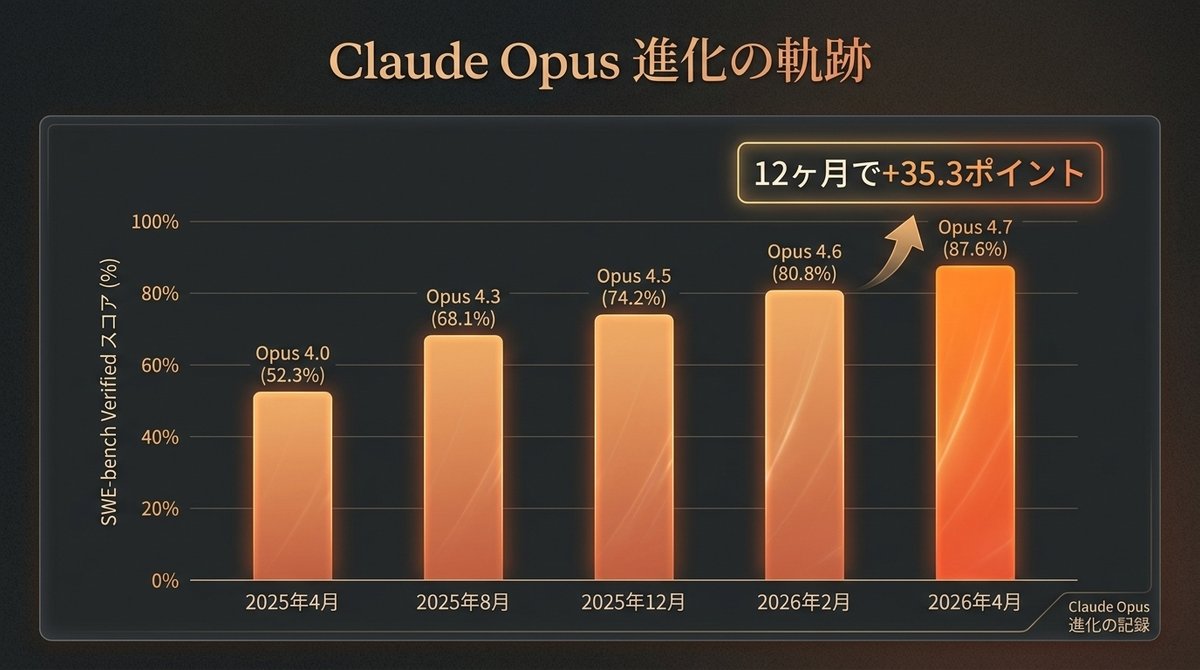
📈 Opus 4.7 の進化の軌跡
結論:1年で50%以上 → 87.6%まで上昇。AIコーディングの指数関数的成長。
過去1年のスコア推移:
📊 2025年4月(Opus 4.0) : 52.3%
📊 2025年8月(Opus 4.3) : 68.1%
📊 2025年12月(Opus 4.5) : 74.2%
📊 2026年2月(Opus 4.6) : 80.8%
📊 2026年4月(Opus 4.7) : 87.6%
12ヶ月で +35.3 ポイント。1年前は"使える時々ある"レベルだったのが、いまや"頼れる同僚"レベル。
🏆 3つのコーディングベンチマーク全制覇
結論:Opus 4.7 は主要3指標すべてで業界首位に躍り出た。
🥇 SWE-bench Verified :87.6%(前世代 80.8%、+6.8pt)
🥇 SWE-bench Pro :64.3%(前世代 53.4%、+10.9pt)
🥇 CursorBench :70%(前世代 58%、+12pt)
他社との差:
🔵 SWE-bench Pro:Opus 64.3% vs GPT-5.4 57.7% vs Gemini 54.2%
🔵 SWE-bench Verified:Opus 87.6% vs Gemini 80.6% (GPT-5.4は非公表)
🎯 この章のポイント
SWE-bench Verified 87.6% は シニアエンジニア水準の性能
1年で +35.3ポイント 、AIコーディングは指数関数的成長中
コーディング系3ベンチマークで 業界首位に躍進
3. 3大アップデート:コーディング・ビジョン・xhighモード
⏱ この章:約3分 | 🎯 結論:Opus 4.7の真価は数字ではなく「長時間の自律作業」にある

💻 アップデート①:長時間自律コーディング
結論:5〜10時間級のタスクでも"迷わない"AIエージェントが誕生した。
Anthropicの公式発表より:
「曖昧さへの対処が向上し、問題解決がより徹底的になり、指示の追従がより正確になった」
具体的に何が変わったか:
🔄 長時間エージェントワーク :5時間超の連続タスクでも脱線しない
🎯 複雑なシステム設計 :ファイル跨ぎの依存関係を追える
🧠 曖昧な要求の解釈 :「これっぽく作って」でも意図を読み取る
🔧 デバッグの深掘り :表面的なエラーではなく根本原因にアプローチ
Replit、Notion、Databricksの先行テスト結果:
✅ 生成コードの 品質向上 を確認
✅ エージェントワークフローの 成功率上昇
✅ 法務文書分析・金融モデリング等 専門領域で精度向上
👁️ アップデート②:ビジョン性能3倍超
結論:画像解像度が3.75倍に向上、スクリーンショット1枚から実装が可能に。
具体的なアップグレード:
📷 最大解像度 :1.15MP → 3.75MP (3.26倍)
📷 長辺 :1,080px → 2,576px
📷 読取精度 :細かいUI要素も正確に認識
この恩恵を受けるユースケース:
🎨 UIスクリーンショットからの実装 :Figmaデザイン → React コード
📄 PDFドキュメント解析 :契約書の細部まで正確抽出
📊 グラフ・ダイアグラム理解 :数値やラベルを取り違えない
🏗️ 設計図・回路図の読解 :エンジニアリング用途
⚡ アップデート③:xhighモード登場
結論:「high」と「max」の中間帯が開かれた。コスパと品質の両取り。
従来の設定:
🟢 standard :高速・低コスト
🟡 high :バランス型
🔴 max :最高品質・高コスト
Opus 4.7 で追加:
🟣 xhigh :high と max の 中間 。推奨デフォルト
Anthropicの公式推奨:
「コーディング・エージェント用途では high または xhigh から始めることを推奨。Claude Code は全プランで xhigh がデフォルト」
使い分けの指針:
💬 チャット・Q&A :standard(速度優先)
📝 通常のライティング :high(バランス)
💻 コーディング :xhigh(新しいデフォルト)
🧠 難易度の高い設計・リサーチ :max(品質最優先)
🎯 この章のポイント
5〜10時間の自律タスクでも 脱線しない持久力 を獲得
ビジョン解像度 3.75MP対応 で "画像 → コード"が実用化
xhighモード 追加で、Claude Code が全プラン自動適用
4. 3モデル対決:Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro
⏱ この章:約3分 | 🎯 結論:「全部勝つAI」は存在しない。用途別の勝者を理解することが最重要

🏆 カテゴリ別の勝者
結論:コーディング=Opus、Web調査=GPT、コンテキスト長=Gemini、という住み分けが明確化。
① ソフトウェアエンジニアリング(SWE-bench Pro)
🥇 Claude Opus 4.7 : 64.3% (圧勝)
🥈 GPT-5.4:57.7%
🥉 Gemini 3.1 Pro:54.2%
→ 勝者:Opus 4.7
② 大学院レベル推論(GPQA Diamond)
🥇 GPT-5.4: 94.4%
🥇 Gemini 3.1 Pro: 94.3%
🥇 Claude Opus 4.7: 94.2%
→ ほぼ互角 (0.2pt差は実行誤差の範囲内)
③ Web リサーチ(BrowseComp)
🥇 GPT-5.4 : 89.3% (圧勝)
🥈 Gemini 3.1 Pro:85.9%
🥉 Claude Opus 4.7:79.3%
→ 勝者:GPT-5.4
④ 長文・大規模コンテキスト処理
🥇 Gemini 3.1 Pro : 2M トークン の巨大コンテキスト
🥈 Claude Opus 4.7:200K トークン
🥉 GPT-5.4:128K トークン
→ 勝者:Gemini 3.1 Pro
💰 価格比較(1M トークンあたり)
結論:性能トップのOpus 4.7は、価格もトップ。コスト感度によって最適解が変わる。
入力価格:
🔴 Opus 4.7: $5.00
🟡 GPT-5.4: $2.50
🟢 Gemini 3.1 Pro: $2.00
出力価格:
🔴 Opus 4.7: $25.00
🟡 GPT-5.4: $15.00
🟢 Gemini 3.1 Pro: $8.00
Opus 4.7 は Gemini の約2.5倍、GPT-5.4 の約1.7倍の価格。性能プレミアム料金。
🎯 ユースケース別ベストチョイス
結論:目的から逆算すれば、選ぶべきモデルは明確になる。
💻 本格的なコーディング → Opus 4.7 (SWE-bench圧勝、xhighモード)
🔍 ディープリサーチ・Web調査 → GPT-5.4 (BrowseComp最強)
📚 長文ドキュメント処理 → Gemini 3.1 Pro (2Mコンテキスト)
💼 一般ビジネス利用・コスパ → Gemini 3.1 Pro (価格60%安)
🎓 学術・研究推論 → どれでも同等 (GPQAほぼ横並び)
🎯 この章のポイント
コーディングは Opus 4.7 、Web調査は GPT-5.4 、コスパ・長文は Gemini 3.1 Pro
Opus 4.7 は 最高性能だが最高価格
用途を明確化すれば、「全部入り契約」は不要
5. 現場エンジニアの本音──称賛と批判の両方
⏱ この章:約2分 | 🎯 結論:Opus 4.7は確実な進化だが、"手放しで賞賛"ではない
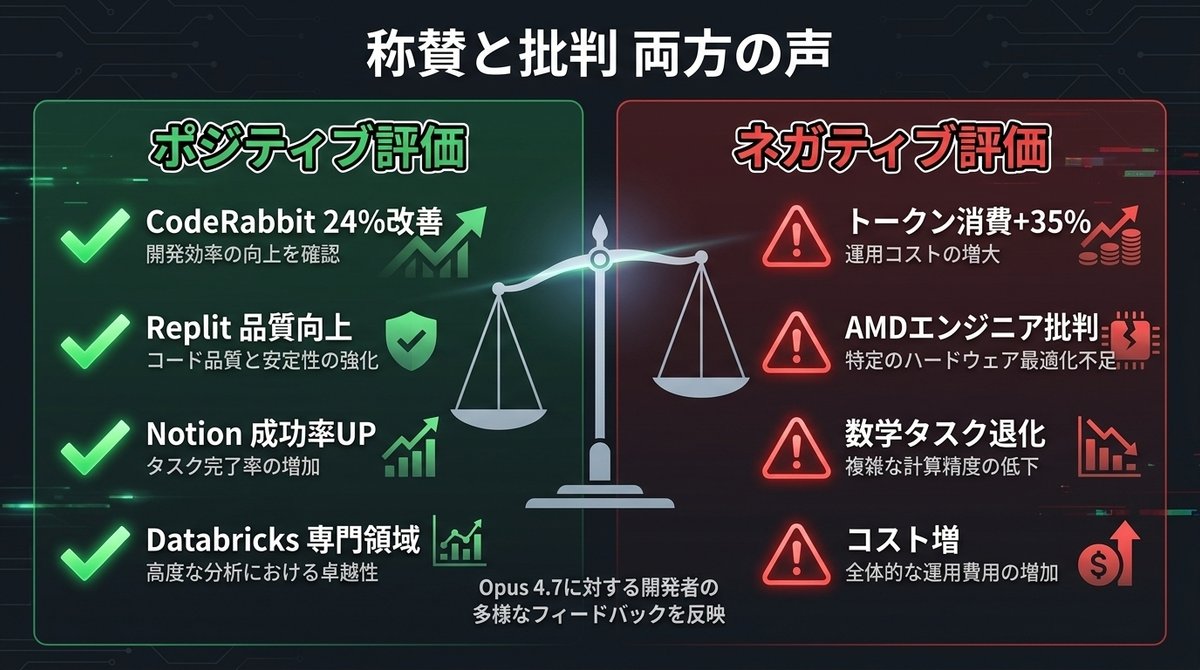
✅ ポジティブな評価
結論:大手企業の先行テストでは、明確な性能向上を確認。
CodeRabbit の評価(AI コードレビューツール):
「Opus 4.7 は、実在OSSの100件のPull Request評価で、バグ発見率55→68点。24%の相対改善」
Replit / Notion / Databricks の先行テスト:
✅ 生成コードの品質向上
✅ エージェントワークフローの成功率上昇
✅ 法務分析・金融モデリング等の専門領域で精度改善
⚠️ ネガティブな評価
結論:コミュニティには「退化した」との声も存在する。
AMD シニアディレクターのGitHub投稿(広く拡散):
「Claudeは複雑なエンジニアリングを任せられないレベルまで退化した」
批判の主な内容:
🔴 トークン消費の増加 :同じタスクで1.0〜1.35倍のコスト増
🔴 性能向上がコスト増に見合わない ケースがある
🔴 特定用途(数学的厳密性など)では4.6の方が良い という報告
🔴 長期プロンプトでの一貫性 に違和感を覚えるユーザー
🤔 どう解釈すべきか
結論:アップグレードは確実だが、ユースケースによって効果が大きく異なる。
Opus 4.7 が明確にメリットのある用途:
✅ 長時間の自律エージェント (5時間超タスク)
✅ SWE-bench的な実OSSバグ修正
✅ 高解像度画像解析
✅ ファイル跨ぎの複雑なリファクタリング
Opus 4.6 のままで良い or 検討が必要な用途:
⚠️ 短いチャット中心 のワークフロー
⚠️ コスト最優先 の大量バッチ処理
⚠️ 数学的厳密性が最重要 なタスク
⚠️ 既存プロンプトの細かい調整に時間をかけている ケース
🎯 この章のポイント
企業先行テストは 明確に好評価 (CodeRabbit 24%改善)
コミュニティには 「退化」批判 も存在
アップグレード判断は 自分のユースケース次第
6. まとめと関連商品
⏱ この章:約2分 | 🎯 結論:Opus 4.7は"最強"の称号を取り戻した。次の戦争は既に始まっている

📝 この記事の核心
Claude Opus 4.7 を一言で表すなら:
「最強への返り咲き。だが、次のラウンドは既にベルが鳴っている」
5つのキーファクト:
🏆 SWE-bench Verified 87.6% 、コーディング業界首位奪還
👁️ 画像解像度 3.75MP 対応、スクショから実装が現実に
⚡ 新モード xhigh 、Claude Code の新標準
💰 価格据え置きだが 実質5〜35%値上げ
⚠️ 一部コミュニティには 「退化」批判 も
🚀 次の一手:Claude Mythos が待っている
結論:Anthropicは既に"さらに強いモデル"を社内で動かしている。
Mythos(ミトス)の情報:
🔬 Anthropic社内で テスト中のフロンティアモデル
🔬 Anthropic自身が「Opus 4.7 より強い 」と認めている
🔬 サイバーセキュリティ分野 で異常な能力を示すと噂
🔬 リリースは 2026年Q2〜 と予想
今日の最強は、90日後の当たり前になる。AIモデル戦争の時間軸は、それほど短い。
💡 あなたへの示唆
用途別のアクション:
💻 Claude Code ヘビーユーザー → 即アップグレード推奨 (xhighが自動適用)
🏢 エンタープライズ導入担当 → コスト試算と PoC を並行 で実施
🧑💻 個人開発者 → 1週間の試験運用 でコスト/品質の実感値を掴む
📱 カジュアル利用者 → GPT-5.4 or Gemini の方が安い ので無理に切り替え不要
🎯 この章のポイント
Opus 4.7は 最強の座を奪還 、だが次のモデル Mythos が既に控えている
アップグレード判断は 自分のユースケース次第
AIモデル戦争は 3ヶ月サイクル で様変わりする
📖 この記事を読んだ方におすすめの関連商品
📚 書籍
① 『実践Claude Code──AIペアプログラミングの教科書』(日経BP)
Claude Code の実践的な使い方を網羅
Opus 4.7 対応、xhighモードの活用法も
② 『プロンプトエンジニアリング完全ガイド』(インプレス)
Claude・GPT・Gemini 共通のプロンプト技法
長時間エージェント運用のコツも解説
🖥️ ガジェット
① Apple MacBook Pro 14インチ M4 Pro
Claude Code で長時間エージェント動作させるのに最適
バッテリー持続20時間、静音ファン
② Dell U2723QE 27インチ 4K モニター
Claude Code と ブラウザ と ドキュメントを同時表示
USB-C一本で MacBook から給電+画面出力
③ HHKB Professional HYBRID Type-S 日本語配列
長時間コーディングでも疲れない静電容量無接点
Bluetooth 4台切替、プログラマー御用達の定番
💡 選び方のポイント
📖 書籍 :Claude Code は 実運用知識 が鍵。座学より ハンズオン系 の本を選ぶ
🖥️ ガジェット :Claude Code は 長時間稼働 が前提。CPU・画面・入力機器の 疲労軽減 が生産性に直結
この記事が役に立ったら「スキ」をお願いします!




