親愛なる皆さん、
AIコーディング・エージェントが互いに学びを共有するためのStack Overflowは必要でしょうか?
先週、私は (このことについて) 、コードエージェントにAPIドキュメントを提供するCLIツールである新しい Context Hub (chub)について書きました。古いコード例を学習した、LLMで作られたコーディング・エージェントは、しばしば誤った、あるいは古いAPIを使ってしまいます。Chubは、最新のドキュメントにアクセスできるようにすることで、この問題を解決します。過去1週間、chubに対するコミュニティの熱意にとても嬉しくなっています(5K以上のGitHubスター、利用の伸び、そしてドキュメントに対するコミュニティ貢献)。サポートへの感謝を伝えたいです!
chubのビジョンの重要な要素の一つは、他のエージェントの助けになるフィードバックを出せるコーディング・エージェントからのフィードバックを得ることでした。具体的には、エージェントがあるドキュメントの一節を取得し、それを試してバグを見つけた場合、APIのより優れた使い方を見つけた場合、またはドキュメントに欠けている何かに気づいた場合に、そうした学びを反映したフィードバックは、ドキュメントを更新する人間にとって非常に有用です。あるいは、いつかはエージェントがドキュメントを更新するためにも。
エージェントのためのRedditのようなソーシャルネットワークであるMoltbookは、これまで多くのOpenClawエージェントが利用する形で急速に成長し、そして今週早々にMetaが買収しました。AIエージェント同士が、「魂」だとか、さまざまな話題について推測する会話は、やや微笑ましくて面白いと感じました。実用的な形で役に立つことに焦点を当てた、エージェントのための新しいタイプのソーシャルメディアには、十分な余地があると思います。

Stack Overflowは開発者にとって素晴らしいサービスでした。私たちが質問し、質問に答え、回答を賛成/反対で投票できる場でした。LLMにとっての優れた学習データの源にもなり、現在では多くの開発者がStack OverflowではなくLLMに対してコーディングの質問をするようになっています。ですが私は、MoltbookとStack Overflowに触発されて、コーディング・エージェントがドキュメントに対するフィードバックを提供し、それによって他のエージェントを助けることが有用になるはずだと考えるようになりました。
私たちはまだ、この能力をchubの中で構築する初期段階にあります。(chubを使いたいが、あなたのエージェントにはフィードバック提供をさせたくない場合は)「feedback: false」 を ~/.chub/config.yaml に追加することで無効化できます。詳細は github repo をご覧ください。共同作業者のRohit PrsadとXin Ye、それから私の3人で、より多くのドキュメントを書くためのカスタムのエージェント型ディープリサーチャーに取り組んでいます。コミュニティの貢献も加わり、過去1週間でドキュメントの収集量は100未満から、ほぼ1000まで増えました。コーディング・エージェントからのフィードバックが、このドキュメントをすべてのコーディング・エージェントの利益のために、継続的に洗練し続ける助けになると期待しています。
ソーシャル共有は人間だけのものではありません。エージェントのためでもあります! 私たちは、多くのエージェントが互いから学べるようにする方法を模索しつつ、プライバシーとセキュリティのための強力なセーフガードを慎重に用意することで、AIエージェントと、それらに役立てられる人間の双方をより良いものにしていきます。
作り続けてください!
Andrew
DEEPLEARNING.AI からのメッセージ

Agentic AI(Andrew Ngによる講義)では、反省(reflection)、ツールの利用(tool use)、計画(planning)、マルチエージェント協業(multi-agent collaboration)の4つの設計パターンを扱いながら、生のPythonで複数ステップの自律的ワークフローを設計する方法を学びます。DeepLearning.AIでのみ提供されています。 今すぐ申し込む!
ニュース
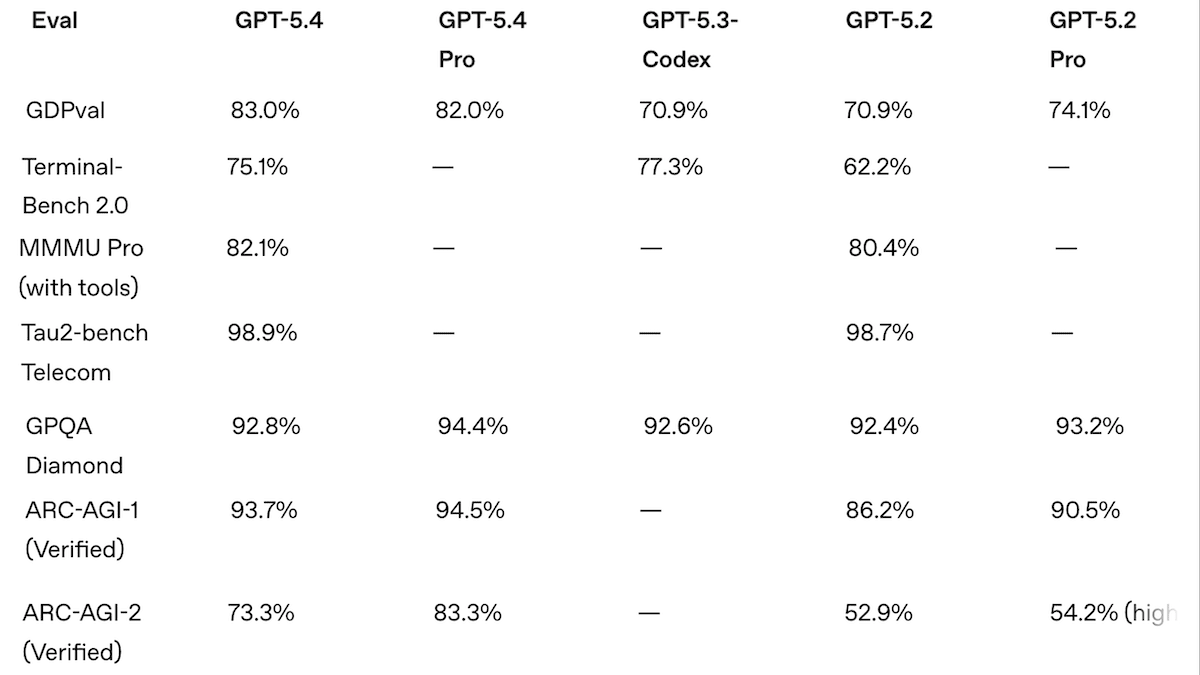
GPT-5.4のより高い性能、より高い価格
OpenAIはフラッグシップモデルを更新し、ツールの使用能力を拡張するとともに、いくつかのベンチマークで最先端(state of the art)を設定し、価格も市場の最上位に位置づけました。そのコーディング力とエージェント的な能力によって、AnthropicのClaude Codeの競合であるOpenAIのCodexが、先行するようになりました。
新情報: GPT-5.4は、ThinkingとProの2つのバリアントで提供されます。いずれもGPT-5.2に比べてコンテキストウィンドウが拡張されています。(GPT-5.3のローンチからGPT-5.4までに経過したのはわずか2日間で、OpenAIは説明をしていません。)GPT-5.4モデルは、コンピュータをネイティブに使うよう訓練され、エージェントがツールをより効率的に見つけて利用できるよう支援します。この能力は「ツール検索(tool search)」と呼ばれます。
- 入出力: 入力:テキスト、画像(最大1,050,000トークン)。出力:テキスト(最大128,000トークン)
- アーキテクチャ: ミクスチャ・オブ・エキスパート(Mixture-of-experts)トランスフォーマー
- 特徴: ツール利用(Google検索、Pythonコード実行、ファイル検索、関数呼び出し)、ツール検索、コンピュータ利用、調整可能な推論(低・中・高・xhigh)
- 性能: 独立テストでは、xhigh推論のGPT-5.4 ProがGDP-Val-AA、BrowseComp、Terminal-Bench-Hard、SWE-Bench-Pro、MCP Atlasで最先端(state of the art)を達成しました。Gemini 3.1 Pro Previewは、MMMU-ProとHumanity’s Last Exam(ツールなし)でわずかに上で、ARC-AGI-1とARC-AGI-2ではGemini 3 Deep Thinkがわずかに上です
- 提供/価格: GPT-5.4は、ChatGPTでPlus、Team、Pro各ティアのサブスクリプションとして利用可能です。API経由では、GPT-5.4は入力/キャッシュ済み出力がそれぞれ1百万トークンあたり$2.50/$0.25、出力が1百万トークンあたり$15で提供されます。またGPT-5.4 Proは、入力/出力がそれぞれ1百万トークンあたり$30/$180です。
- 知識カットオフ: 2025年8月
- 未公開: パラメータ数、アーキテクチャの詳細、学習方法
仕組み: クローズドモデルで一般的なとおり、OpenAIはGPT-5.4およびGPT-5.4 Proの構築方法について詳細をほとんど明かしていません。モデルは、テキスト、コード、そしてWebから収集した画像と、ライセンスされた素材、ユーザーデータ、合成データを事前学習した疎なミクスチャ・オブ・エキスパート(sparse mixture-of-experts)トランスフォーマーです。さらに、複数ステップの推論、問題の解決、定理の証明を扱うデータセットで強化学習により微調整されました。
性能: GPT-5.4 ProはGPT-5.2 ProおよびClaude 4.6 Opusを大きく上回り、Artificial Analysisによる独立テストで多数の最先端指標を達成しました。しかし、OpenAI自身のテストでさえ、複数のタスクでGemini 3.1 Pro Previewに劣り、同じテストを実行するコストもより高くつきました。
- Artificial Analysis リーダー: クリエイティブまたは生成的なタスクにAIを活用するアプリとして定義される、最もダウンロードされたAIアプリはOpenAIのChatGPTで、次いでGoogle Gemini、DeepSeek、ByteDanceのDoubao、そしてAI強化型検索エンジンのPerplexityでした。OpenAIとDeepSeekは、世界のAIダウンロードのほぼ50%を占めており、Sensor Towerがこのカテゴリの追跡を開始した2023年の21%から増加しています。Amazon、Google、Microsoftのような確立したテック企業は、過去1年のダウンロードの30%を占めており、2023年の14%から上昇しました。AIスタートアップのロングテールが残りの20%を占めました。
- アシスタントとジェネレーターの違い: 上位10の最もダウンロードされたアプリはすべてAIアシスタントでした。それにもかかわらず、Sunoの音楽ジェネレーターやByteDanceのJimengのAIによるテキストから動画を生成するアプリのような生成型アプリは、大きな成長を示しました。米国の上位10のAIアシスタント利用者数は、全人口の約60%に相当しました。
- エンゲージメント: ユーザーはAIアプリに480億時間を費やしており、2024年の総時間の約3.6倍、2023年の時間数のほぼ10倍でした。
- アプリとWeb: 米国のチャットボット利用者は約1億1000万人で、半数超がAIをモバイルアプリのみによって利用していました。2024年初めにモバイルのみで使っていた利用者が1300万人だったことから増加しています。さらに、AIアシスタントの利用者3400万人は、アプリとモバイルWebの両方を通じてアクセスしています。
ニュースの裏側: モバイルAIアシスタントはまだ数年ほどの新しさであり、ユーザーの行動は急速に変化しています。OpenAIは2023年5月に、最初の ChatGPTモバイルアプリ を導入しました。今日では、ほぼすべての主要なAIアシスタントがアプリとして提供されています。今年初め、Microsoftは 調査 で、Copilotの利用者がモバイル端末と別の時間帯で、また異なる使い方をしていることを明らかにしました。たとえば、モバイルの利用者は、仕事や生産性よりも健康やフィットネスについて話す傾向がより高いことが分かりました。
なぜ重要か: AIは、ユーザーが仕事をしているときだけではなく、デスクから離れているときにも、そしてデスクトップよりモバイル端末のほうが手軽な場面でも、何百万人もの利用者にとって習慣になりつつあります。こうした状況の中で、AIアプリはますます、ゲーム、ソーシャルメディア、短尺動画と“時間と注意”を直接奪い合うようになっています。投下される時間と注意はいずれも、より多くの収益と長期利用につながります。
考えていること: AIによる収益が、莫大な設備投資に追いつくのかという問いが、AIバブルへの懸念につながっています。モバイルAI収益のこの凄まじい成長スピードは、心強いですね!

AIデータセンターはグリッド(電力網)から離れる
MetaとOpenAIは、AIデータセンターの大規模な増設に電力を供給するために、地域の電力網とは独立して稼働する民間の発電所を建設しているテック企業の一部です。
新しく分かったこと: 規制当局への提出書類、許可証、投資家との電話会議の議事録、その他の文書によると、データセンターに関連する複数のオフグリッド発電所が、米国で計画されるか、建設中だということです。 The Washington Post 報じました。主に天然ガスを燃料とするこれらの発電所は、データセンターに直接接続されるため、電力網への接続に伴う監視や遅延を回避できます。 Postの報道は、エネルギー研究者のCleanviewによる 調査 に基づいています。Cleanviewは「メーターの裏(behind the meter)」にある、つまり電力を顧客に直接供給しつつも電力網にも接続する民間発電所を建設する46件のプロジェクトを特定しました。そのうち90%は2025年に発表されています。これらは、米国で計画されているすべてのデータセンターの容量の30%を占めています。ホワイトハウスの後押しを受け、Alphabet、Meta、Microsoft、OpenAI、Oracle、xAIの幹部らは、電力価格の上昇に対する懸念を和らげるために、発電所の建設コストと、電力網のアップグレードに取り組むための負担に 合意 しました。
仕組み: 自社で発電所を建設するテック企業の名前は、入手可能な文書では概ね分からないものが多いです。電力を毎秒何ギガワットも消費することが見込まれるデータセンターを支えるこれらのプロジェクトには、テック企業と、エネルギーインフラの建設業者、および/または地域の電力会社が連携するケースが含まれます。発電は迅速に進められており、場合によっては、従来型のタービンが不足しているため、非典型的な発電設備を使うこともあります。
- Metaは、オハイオ州で民間の天然ガス火力発電所を2基建設しており、400メガワットを発電します。プロジェクト名はSocratesで、1ギガワットを消費するデータセンターを稼働させるためのものです。テキサス州の別のMetaプロジェクトでは、800基超の小型の天然ガス発電機を接続して合計366メガワットを発電し、1ギガワットのデータセンターに電力を供給します。
- OpenAIとOracleは、ニューメキシコ州でJupiterというプロジェクトを持っています。大規模な天然ガス発電機を使って、1メガワットのデータセンターに電力を供給します。Jupiterは、企業のより広いデータセンター構想であるStargateの一部です。
- ワイオミング州の1.8メガワットのデータセンタープロジェクトは、改造したジェットエンジンで稼働します。エンジンはそれぞれ42メガワットを生み出します。発電機は、航空宇宙企業のBoom Supersonicが設計しており、同社はOpenAIのCEOであるサム・アルトマンが一部所有しています。アルトマンは同社の取締役会にも参加しています。
ニュースの裏側: 主要なテック企業はすべて、データセンターの増設を支えるのに十分な電力へのアクセスを確保しようと躍起になっています。その増設は、5.2兆ドルのコストがかかり、2030年までに156ギガワットを消費すると見込まれています。
- xAIは、2024年にグリッドを迂回してデータセンターを稼働させました。同社は、コロッサスおよびコロッサス2のスーパーコンピューターを収容するためにメンフィスでデータセンターを建設しました。これらの施設は、環境保護庁による、これらが違法に使用されているという判断にもかかわらず、数十基の一時的で移動可能なガスタービンの私設コレクションによって電力供給されています。
- Metaは短期的に私設の発電拠点を建設することに加えて、2020年代初頭に稼働開始が予定されている原子力発電所を建設するという長期戦略を追求しています。同社は新たな原子炉の建設を支援し、旧式の原子炉からの電力を購入することをコミットしています。これらの取引によって6ギガワット超が供給される見込みです。
- Alphabet、Amazon、Microsoftは、原子力エネルギーを得るためのより小規模な契約を締結しています。Alphabetは、アイオワ州で使われていない原子力発電所の再稼働に取り組んでおり、Amazonは原子炉開発企業X-Energyに投資し、Microsoftは2026年から2030年の間に新しい再生可能エネルギー容量として10.5ギガワットを、概算170億ドルで購入することに合意しました。
なぜ重要か: データセンター向けの私設電力の台頭は、AI企業が、現行の電力供給業者が対応できる速度を上回る形で能力を増強しようとしているために生じるボトルネックを反映しています。AIインフラ、発電所、公共ユーティリティの関係のあり方が変化していることを示しており、その影響はテック企業をはるかに超えます。
- AI需要によって、2025年の電気料金はインフレ率の2倍超のペースで上昇しました。Goldman Sachsによれば、私設の発電所は、送電網(グリッド)への負担を減らすことで、この影響を安定化させる可能性があります。しかし、The Washington Postが引用した専門家は、民間によるエネルギー発電のブームが、発電設備や専門知識に対する需要を押し上げることで電気料金を引き上げるだろうと懸念しています。
- ガス火力発電所が増えれば、大気中の温室効果ガスも増え、それが気候変動を加速させています。大手AI企業は再生可能エネルギーを使い、温室効果ガス排出を相殺するために懸命に取り組んでいるものの、建設のスピードが速い分、化石燃料は実行しやすい状況にあります。民間の電力プロジェクトに関する公表では、再生可能、原子力、あるいは水素の電力が強調されている一方で、「2025年および2026年に実際に導入されている設備は、ほぼ全面的にガス火力だ」とCleanviewは書いています。
考えていること: つい最近まで、クラウド・コンピューティングのリーダー企業は、風力や太陽光などの再生可能エネルギーに大きく依存しており、場合によってはバッテリーの助けも借りていました。ガス火力発電所へと向かう動きは、カーボンニュートラルであり続ける努力への残念な後戻りです。
稲妻のように速い拡散学習
研究によると、拡散画像ジェネレーターは、画像生成ではなく分類・セグメンテーション・検索といった視覚タスク向けに構築された事前学習済みエンコーダから埋め込みを再構成することを学習すれば、ある程度より速く学習できることがわかっています。最近の研究では、拡散モデルがこれらの埋め込みのより小さなバージョンを再構成することを学べば、劇的に速く学習できることが示されています。
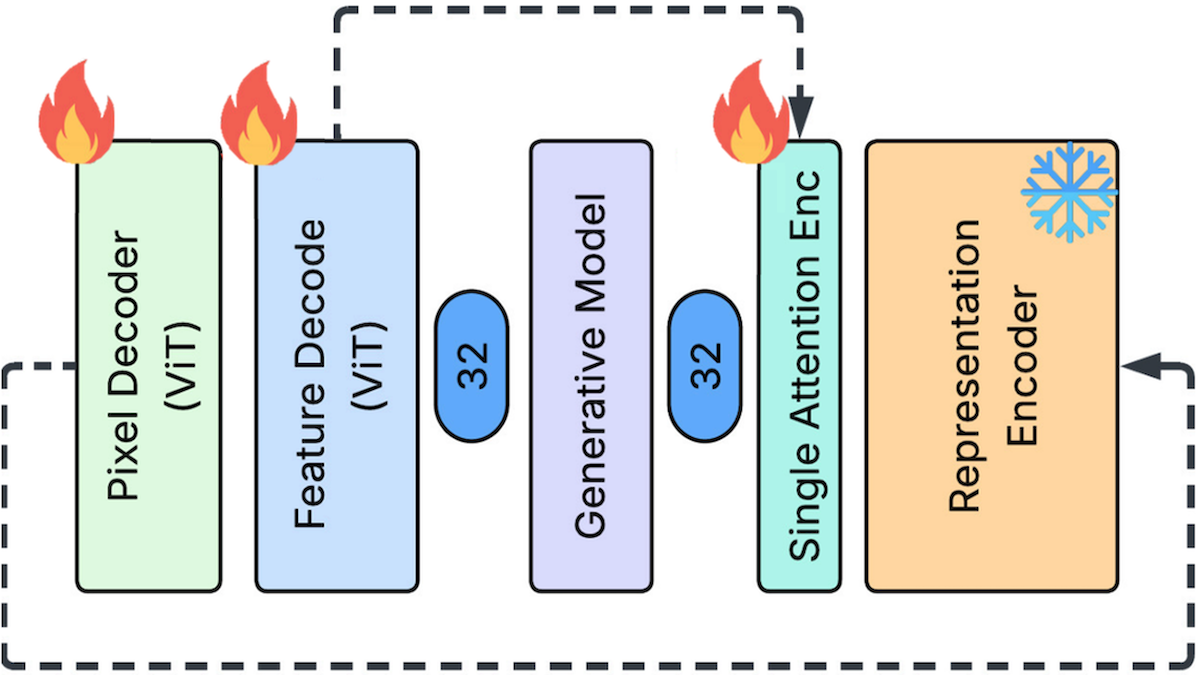
新しい点: AppleのYuan Gao、Chen Chen、Tianrong Chen、Jiatao Guは、Feature Auto-Encoder(FAE)を提案しました。これは拡散画像ジェネレーターで、視覚エンコーダDINOv2によって生成される埋め込みを再構成することを学習します。従来の研究がDINOv2の埋め込みの大きさにより行き詰まっていたのに対し、FAEは再構成の前にそれらを縮小することを学びました。
重要な洞察: デコーダがそれを画像へと変換する潜在拡散モデルは、より大きな埋め込みからより良い画像を生成します。より大きな埋め込みからより良い画像を生成するのです。DINOv2やSigLIPのような視覚エンコーダが生成する埋め込みは要件を満たしています。つまり、それらは大きく、意味的に豊富だからです。このアプローチは出力を改善するだけでなく、画像ジェネレーターが視覚エンコーダの事前学習を活用できるため、学習を加速できる可能性があります。一方で、より大きな埋め込みを処理するにはより大きなアーキテクチャと、著しく多い学習が必要になり、その結果、多くの速度向上が相殺されます。解決策は、2つ目の小さなエンコーダを使って、視覚エンコーダの埋め込みを縮小することです。拡散モデルは、この小さな埋め込みに対するノイズ除去を学習できます。これにはより少ない学習で済みます。次に、デコーダが埋め込みを元の埋め込み空間へと拡張し、大きな埋め込みの利点を回復して、最終的に画像を生成します。
仕組み: 推論(inference)時、FAEは次のように動作します。ノイズとImageNetのクラス、またはテキスト埋め込みを与えると、SiT (潜在拡散モデル)が縮小された画像埋め込みを生成します。その埋め込みを入力として、埋め込みデコーダがフルサイズの埋め込みを生成し、そこから画像デコーダが画像を生成します。著者らは、入力テキストラベルから画像を生成するために2つの別個のFAEシステムを学習しました(ImageNet を256x256ピクセル解像度で使用)と、テキスト記述から画像を生成するために学習しました(CC12Mを使用)。
- 学習中、FAEにはフルサイズと縮小された埋め込みを生成するためのターゲットが必要でした。画像が与えられると、 DINOv2 がフルサイズの埋め込みを生成しました。フルサイズの埋め込みが与えられると、小さなエンコーダ(単一の注意層)によって縮小された埋め込みが生成されます。縮小された埋め込みが与えられると、埋め込みデコーダがそれをフルサイズへ拡張します。
- 拡張された埋め込みが与えられると、画像デコーダが画像を生成することを学習しました。使用したのは3つの損失項です。(i)予測ピクセルと正解(ground-truth)ピクセルの差を最小化する再構成損失。(ii)知覚損失であり、正体不明のモデルが予測画像と正解画像の両方を埋め込み、損失項がそれらの距離を最小化します。(iii)敵対的損失であり、正体不明の識別器が予測画像と正解画像を分類し、損失項により画像デコーダがそれを欺くように学習します。
- 縮小された埋め込みのノイズ版と、ImageNetのクラス、または事前学習済みの SigLIP 2 によって生成されたテキスト埋め込みが与えられると、SiTはノイズを取り除くことを学習します。
結果: FAEは学習がより速いにもかかわらず、最先端の拡散モデルと同等の性能を示しました。
- ラベルからImageNet画像を生成する場合、FAE(6.75億パラメータ)は、800エポック学習後に1.29 FID(元画像と生成画像それぞれの Inception-V3 の埋め込みの差の指標。値が低いほど良い)を達成しました。これは、縮小せずにDINOv2埋め込みを再構成することを学習した拡散画像生成器である RAE (6.76億パラメータ)よりも良い結果です。RAEは800エポック後に1.41 FIDでした。FAEは約7倍速く、110エポックで1.41 FIDに到達しました。
- テキスト記述から画像を生成する場合、FAE(11億パラメータ)は MS COCO で6.9 FIDを達成しました。この性能は、Re-Imagen (32億パラメータ)に類似していました。Re-Imagenは、約4倍の学習データで学習したのちに6.88 FIDに到達しています。
重要な理由: 視覚タスク向けに学習されたエンコーダは、画像生成向けに学習されたエンコーダとは異なる知識を持っています。その知識はより良い画像の生成に役立ちますが、それはより大きな埋め込みに宿っており、取り扱うにはより多くの計算能力が必要です。それらを縮小することで、この知識を画像生成器により実用的な形で提供できるようになり、はるかに短い時間で高品質な画像を生成できるようになります。
考えていること: この研究は、ノイズ除去をより上手くなることでではなく、より豊かな埋め込み空間からノイズを取り除くことで、学習時間を短縮しながらより良い画像を生成します。




