親愛なる皆さま、
まだエージェントワークフローを構築していないなら、ここで紹介する簡単なレシピを使って試してみることをお勧めします!数行のコードで、高度に自律的で、程よく能力があり、しかし非常に信頼性の低いエージェントを作れます。
フロンティアのLLMが複数ステップを自律的に実行できる能力がこれを可能にしています。具体的には、ディスクアクセスやウェブ検索などのツールをLLMに与え、ゲーム作成や調査といった高レベルなタスクをプロンプトで指示し、自由に動かして結果を見ることができます。
重要な注意点:今日の実用的かつ商業的に価値のある多くのエージェントワークフローはこの単純な方法で作られていません。現在のエージェントは、ツールへのアクセスを与えて全自律的に判断させるのではなく、ステップバイステップの動作を誘導するコード(スキャフォールディング)を多く必要とします。信頼性のあるエージェントを構築するには多くの誘導コードが必要ですが、モデルの性能が向上すれば、その必要性は減るでしょう。
実用的なエージェントを作りたいなら、我々のAgentic AIコースが最適です。しかし、この単純で実用性は低いレシピでも遊んで楽しむことができます!
このレシピをすばやく実装するには、Rohit Prasadと私が開発しているオープンソースのaisuiteパッケージ(pip install "aisuite[all]")がおすすめです。このパッケージは、LLMプロバイダーの切り替えを容易にし、膨大なコードを書かずにツール(関数呼び出し)を使わせることができます。
Aisuiteは、私が個人的にLLMプロバイダーの切り替えを簡単にする方法を探していた週末プロジェクトとして始まりました。特定のLLMでワークフローを作ったあと、別のLLMで性能やコスト、レイテンシが改善されるか試したくなるのです。aisuiteを通してAPI呼び出しを行うことで、この切り替えをとても簡単にしました。多くのオープンソースコミュニティのメンバーもこの開発に貢献しており、最近RohitがMCPサポートを追加し、基本的なエージェントワークフローの構築が簡単になりました。
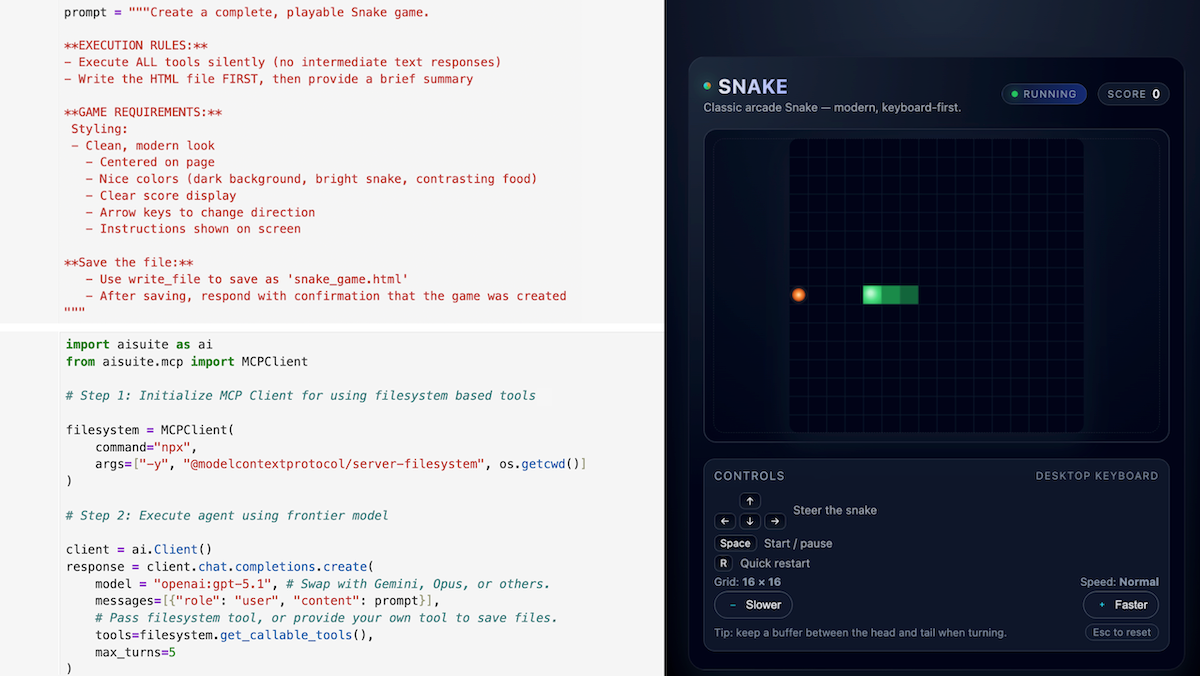
上の画像には、Snakeゲームを生成するために必要なコード全体が表示されています。また、こちらのJupyterノートブックからもアクセス可能です。LLMに"HTMLファイルとしてのsnakeゲームを作成せよ"とプロンプトで指示すると、以下の2ステップです。
- MCPベースのファイルシステムツールを初期化してファイル書き込みを可能にする。
- フロンティアモデル(GPT-5.1、Claude Sonnet 4.5、Gemini 3など)を解き放つ。
これにより通常、LLMはsnakeゲームを作成し、MCPサーバーを介してsnake_game.htmlというファイルを保存します。このファイルはウェブブラウザで開けます。(パラメータmax_turns=5は、LLMの呼び出しとツール実行を交互に最大5回繰り返すことを意味します。)
もう一つの例として、LLMにウェブ検索ツールへのアクセスを与え、複数の都市の天気に関するレポートやHTMLダッシュボードを自律的に構築させる2つ目のノートブックもあります。
まだエージェントを作ったことがなければ、この簡単なレシピで最初の1体を作れることを願っています。ぜひpip install "aisuite[all]"を実行して楽しんでください!
これからも作り続けてください!
アンドリュー
ディープラーニング.AIからのメッセージ

Qdrantと共に、新しいショートコースでマルチベクター画像検索を学びましょう。ColBERTを使ってテキストのマルチベクター検索の仕組みを理解し、ColPaliで画像のパッチレベル特徴を抽出、MUVERAで高速HNSW検索用に単一ベクトルに圧縮、これらを組み合わせてマルチモーダルRAGパイプラインを構築します。今すぐ登録
ニュース
Claudeは少ないトークンでより多くをこなす
Anthropicの旗艦モデル最新バージョンClaude Opus 4.5は、コーディング、コンピューター利用、エージェントワークフローの強みを拡張しながら、生成するトークン数を削減しています。
新要素: Claude Opus 4.5は前モデルを1/3の価格で上回る性能を発揮します。
- 入出力:テキストと画像入力(最大200,000トークン)、テキスト出力(最大64,000トークン)
- 特徴:レスポンス、ツール呼び出し、推論にまたがるトークン生成を制御する調整可能なeffort(低・中・高)、推論トークン用の予算を増やすextended thinking、ウェブ検索やコンピューター使用ツールの利用含む
- 利用可能性/価格: Claudeのアプリ(Pro、Max、Team、Enterpriseプラン)、APIはAnthropic、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry経由で$5.00/$0.50/$25.00(入力/キャッシュ/出力トークンごと)+キャッシュストレージ費用
- 非公開:パラメーター数、アーキテクチャ、学習詳細
動作原理:AnthropicはClaude Opus 4.5をハイブリッド推論モデルと表現。Claude Sonnet 3.7以降と同様、通常モードでは高速応答し、extended thinkingを有効にすると推論トークン処理に時間をかけます。
- 同社はウェブからの公的データや第三者の非公開データ、有償契約者、オプトアウトしなかったAnthropicユーザー、社内運用のデータでモデルを訓練し、ヒトやAIのフィードバックによる強化学習で有用性を向上。
- 消費者向けアプリは会話の過去部分を自動的に要約し、任意長の対話が可能になりました。
性能:人工分析社による独立ベンチマークで、コーディングタスクに秀で、他分野でも上位付近。Anthropicのテストで高性能かつトークン効率が良好。
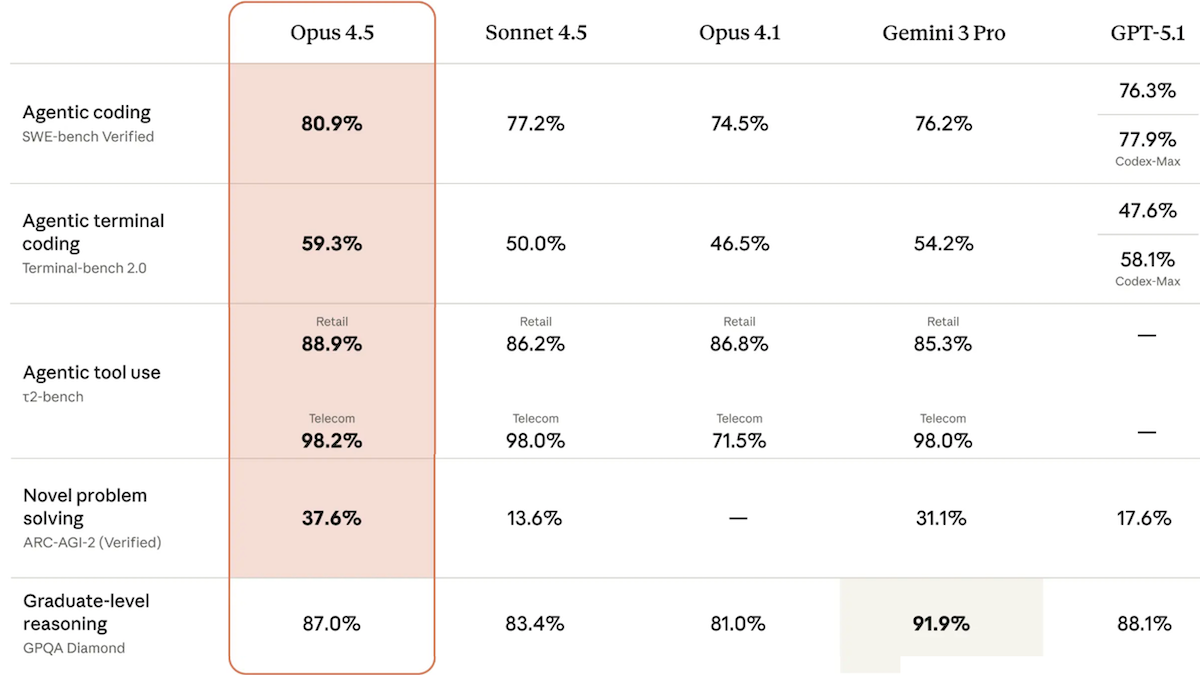
- 人工分析インデックス(10ベンチの加重平均)で、Claude Opus 4.5(70)は2位でOpenAI GPT-5.1と同点、Google Gemini 3 Pro(73)に次ぐ。非推論モードでのスコア60はテストされた非推論モデル中最高。AA-全知インデックスでは事実知識と虚偽傾向を測定し、Claude Opus 4.5(10)はGPT-5.1(2)を上回るがGemini 3 Pro Preview(13)に劣る。
- Terminal-Bench Hard(コマンドライン課題)でClaude Opus 4.5(44%)は人工分析社の他モデルをすべて上回る。
- Anthropicによると、中努力設定でClaude Opus 4.5はSonnet 4.5のSWE-bench Verified性能と同等ながら出力トークン数は76%削減。高努力ではSonnet 4.5を4.3ポイント上回り、48%少ないトークン使用。
- 64,000トークン思考予算と高努力の「並列テスト時計算能力」を用いたテストで、Claude Opus 4.5はAnthropicのエンジニアリング試験(2時間)を受けた全人類を上回った。
背景:一般にClaude Opus 4.5は競合より少ない出力トークン数で同等の結果を出す。人工分析インデックスのテストでClaude Opus 4.5は48百万トークン使用、Gemini 3 Proの高推論設定(9200万トークン)やGPT-5.1(8100万トークン)の約半分。とはいえ単価が高いため総コストは相対的に大きい。テスト費用はClaude Opus 4.5が1,498ドル、Gemini 3 Proが1,201ドル、GPT-5.1は859ドル。
重要性:Claude Opus 4.5はAnthropic中堅モデルのSonnet 4.5が高価格帯のOpus 4.1に匹敵または上回っていた期間の次にリリースされた。例えば人工分析インデックスでSonnet 4.5は63、Opus 4.1は59だった。そのため一時期、ユーザーのOpus高価格支払い意欲が減退していた。しかしClaude Opus 4.5はClaudeファミリー内で明確な序列を復活させ、最上位モデルが中堅より7ポイント上となった。
考察:フロンティアモデル間の性能差は縮まっている。スタンフォードの最新AIインデックスによると、2024年から2025年にかけてLM Arenaのエローレーティングによる1位と10位のモデル間ギャップは11.9%から5.4%に縮小。トップ2間の差は0.7%に。今後もこの傾向が続けば、リーダーボード上の差は多くの用途で重要度を失いつつある。

ホワイトハウスが科学のためのAIを指示
トランプ大統領は科学の発展を加速するためAIを活用する米国の取り組みを開始しました。
新要素: ジェネシスミッションが大統領令で設立され、エネルギー省が17の国立研究所と最先端スーパーコンピューターを統合し、エネルギーから医療まで幅広い分野の研究にAIを活用。政府の研究者はAnthropic、Nvidia、OpenAIなど民間企業と協力し、連邦の独自データセットでモデル訓練や実験を実施します。
仕組み:エネルギー省は政府データへのアクセスを提供するAIプラットフォームを構築し、連邦機関、研究所、企業が協働して科学基盤モデルとAIエージェントを開発。賞金付きコンペやフェローシップ、パートナーシップ、資金提供の機会も組織し、平時には別々の政府・学術・民間リソースを連携。ホワイトハウス科学技術政策局のマイケル・クラツィオス長官はこれを「アポロ計画以来最大の連邦科学リソース動員」とBloombergに語りました。
- 自動化:ロボットラボで人間の関与度合いが異なる形で科学研究を構想・実施するAIモデルの訓練が目標。
- 重点分野:バイオテクノロジー、製造、材料、核分裂、量子情報科学、半導体の6分野。
- 目標:(i) 科学発見の加速、(ii) 国家安全保障、(iii) 低コストエネルギーへの道探求、(iv) 納税者に対する政府投資の収益向上。
- 資金:大統領令として新規資金配分はなし。最初は既存リソースを利用し、議会が追加支出を承認する可能性あり。
- Nvidiaは政府研究所向けに7台の新スーパーコンピューターを構築、CEOジェンセン・ファン氏が発表。AMD、Dell、Nvidiaは新施設建設も合意とNew York Timesが報じる。
背景:科学研究において、AIは受動的ツールから研究の仮説立案から結果までを管理する能動的な協力者に進化中。
- GoogleのAI共科学者は深堀り研究提案を生成し、白血病や肝線維症向け薬物候補を特定し、実験で検証済み。
- AI ScientistはLLMを活用したエージェントワークフローで、AI研究のアイディア生成、コード作成、検証記録を行い、研究論文の作成能力を示した。
- RoboChem(アムステルダム大学)は統合ロボットラボで化学合成を最適化し、人間の化学者を上回る成果を出した。リバプール大学では移動ロボットアームがラボ操作やサンプル解析を高速で実施。
- AI搭載検索エンジンConsensusやSciteは、大量の査読済み研究を統合して文献探索と要約を効率化。
懸念点:ジェネシスミッションはデータ依存だが、政府はデータ収集能力を体系的に低下させている。ホワイトハウスはNOAAの気象データ予算削減、CDCの健康データ収集中断、複数施設の閉鎖を行い、Politicoが報告。大規模かつ最新のデータ不足はAIと人類の世界理解の妨げになる恐れ。
重要性:米国の科学研究へのAI適用と連邦・学術・民間資源の連携推進は、中国のAI投資・進展への対応。CSISによると、中国は量子コンピューティングや電池技術など科学技術の多分野で成果を上げている。ジェネシスミッションの研究促進のための競技会や資金インセンティブはAI業界にも好ましい。
考察:研究アイデアを生成・評価・実行する自律システムは興味深い進展を示している。十分な資金とデータアクセスがあれば、産学官連携で加速される可能性。
アマゾンが前進
アマゾンは基盤モデルの競争力を高め、カスタムモデル訓練やブラウザ自動化エージェント向けプラットフォームを追加しました。
新要素: Nova 2ファミリーはマルチモーダル推論、生成、スピーチ対話に対応。最高峰のNova 2 Pro Preview(マルチモーダル入力、テキスト出力)とNova 2 Omni Preview(マルチモーダル入出力)を年間10万ドルの新サービスNova Forgeで提供。独自データとAmazonデータの組み合わせが可能。さらに自然言語やPythonコードでWebナビゲート、フォーム入力、データ抽出できるブラウザ自動化エージェント構築サービスNova Actを開始。(補足:アンドリュー・ングはアマゾン取締役。)
Nova 2 Pro Preview:最新のNova旗艦モデル、Nova 2 Pro PreviewはAnthropic、Google、OpenAIのモデルと選択ベンチで対抗。
- 入出力:テキスト、画像、動画、音声入力(最大100万トークン)、テキスト出力。
- 特徴:推論レベルの調整(低・中・高)、API経由で同一ワークフロー中にPythonコード実行・評価可能なコードインタープリター、API経由のウェブグラウンディング(引用付き情報取得)。Amazon Bedrockモデル蒸留経由で教師として提供。
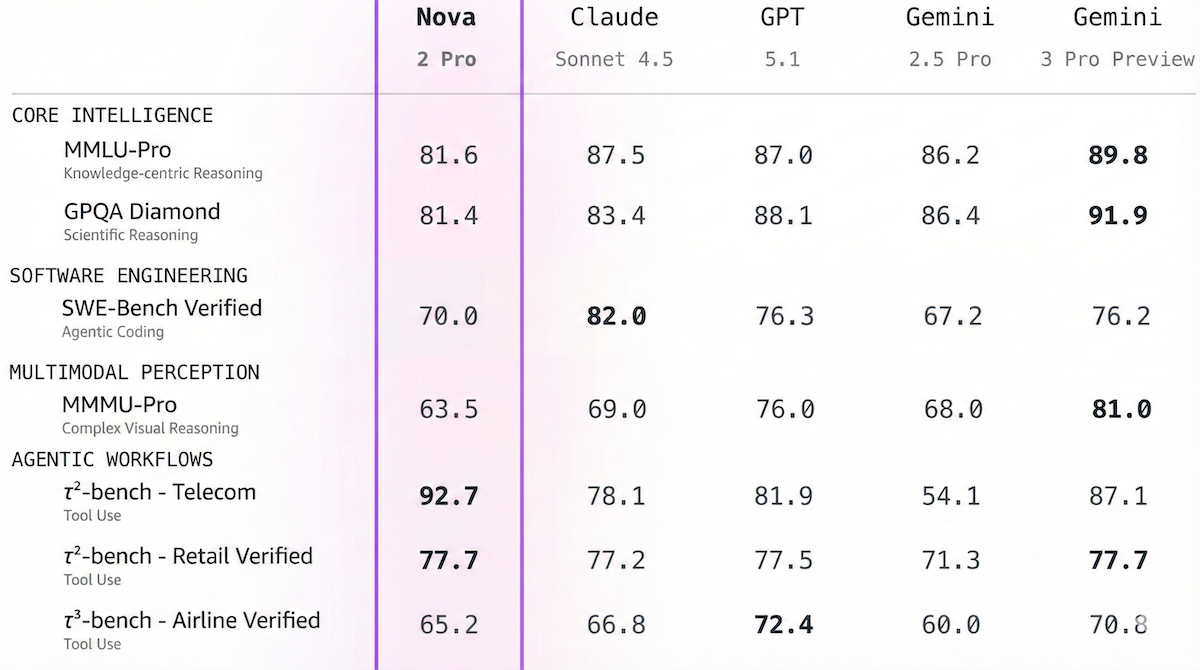
- 性能:アマゾンのテストではNova 2 Pro PreviewはAnthropic Claude Sonnet 4.5を16のベンチマークのうち10で同等以上、Google Gemini 3 Pro Previewを8で同等以上、OpenAI GPT-5.1を8のベンチマークのうち同等以上で上回る。人工分析インテリジェンスインデックスではNova 2 Pro Preview中推論設定(62)および非推論設定(42)は旧モデルNova Premier(32)を凌ぐが、現状トップのGemini 3 Pro Preview(73)には届かず。さらに𝜏²-Bench Telecomのエージェント行動ではNova 2 Pro Preview(93%)がGrok 4.1 Fast、Kimi K2 Thinkingと同率トップ。IFBench指示遵守テストではNova 2 Pro Preview(79%)がGPT 5.1高推論(73%)やMiniMax-M2(72%)を上回る。人工分析は高推論設定での評価は未実施。
- 価格:Amazon Nova Forge経由で$1.25/$0.31/$10(入力/キャッシュ/出力トークンごと)。
Nova 2 Lite:高速でコスト効率の高い推論モデル。多くのベンチマークでAnthropic Claude Haiku 4.5、Google Gemini Flash 2.5、OpenAI GPT-5 Miniに匹敵または上回る。Amazon Bedrock経由で$0.3/$0.03/$2.50(入力/キャッシュ/出力トークンごと)。
Nova 2 Omni Preview:Nova 2 Omni Previewはテキスト、画像、動画、音声をネイティブに処理できる唯一の広く利用可能な推論モデル(最大100万トークン、200以上言語のテキスト、10言語の音声入力可)で、テキストおよび画像を生成。Amazon Nova Forge経由で$0.30/$0.03(入力/キャッシュのテキスト・画像・動画トークン)、$1.00/$0.10(入力/キャッシュ音声)、$2.50/$40(出力テキスト・画像トークン)。
Nova 2 Sonic:Nova 2 Sonicは7言語の多言語音声間変換モデルで、会話を中断せずにツール呼び出し可能。アマゾンのテストでGPT RealtimeやGemini 2.5 Flashより好まれた。Amazon Bedrock経由で$3/$12(入出力音声トークン)、$0.33/$2.75(入出力テキストトークン)。音声モデルはAmazon ConnectやAudioCodes、Twilio、Vonageと統合。
重要性:Nova 2ファミリーはアマゾンのモデルポートフォリオの穴を埋める。これまで推論レベル調整可能なモデルがなく、AnthropicやGoogle、OpenAIと競合困難だった。さらにNova Forgeは競合他社と大きく異なる魅力的なサービスであり、Nova Actによるブラウザ自動化はAmazon Bedrockのエージェンティック機能を強化。
考察:これまで競合に遅れをとっていたアマゾンの基盤モデルは、Nova 2の性能向上で差を縮める意思が見える。
小型モデルが難解パズルを解く
大規模言語モデルは、スドクのような複数の要素が正確に揃わなければ解答にならず、一つのミスで全体が無効になるようなパズルに苦戦する。研究者らは、小型ネットワークが反復的に解決策を洗練することで、この種のパズルを効果的に解けることを示した。
新展開:サムスンのアレクシア・ジョリクール=マルティノーはTiny Recursive Model(TRM)を開発。少ない情報から抽象的ルールを推論してグリッドを埋める視覚パズル、具体的にはスドク、メイズ、最新のARC-AGIベンチマークで、DeepSeek-R1やGemini 2.5 Proを含む大規模事前学習LLMを上回る。
主な洞察:ニューラルネットに解を反復的に洗練させる方法は3段階:(i) ランダム解を与え解を計算させる、(ii) 出力をフィードバックして新解を計算、(iii) これを再帰的にバックプロパゲーションし、反復でより正確な解を出すよう学習。ただし欠点として、推論時にネットワークは変更履歴を記憶しないため、反復ごとに改善した変更を元に戻す恐れがある。これを防ぐため、別のコンテキスト埋め込みを生成し、各反復でフィードバックさせる手法を採用。この手法は、特別な損失関数なしにパフォーマンス向上に役立つ情報を保持可能にする。
作動原理:TRMは2層ネットワークで、対象パズルに合わせて構造が変わる。著者らは9x9行列のスドク「Sudoku-Extreme」に5百万パラメータのバニラNNを使い、30x30行列の「Maze-Hard」「ARC-AGI-1」「ARC-AGI-2」には7百万パラメータのトランスフォーマーを使用。これらは論理、経路探索、視覚的推論を要する難度の異なる課題。
- 学習中、パズル(トークン表現)、解トークン(初期はランダム)、コンテキスト埋め込み(初期はランダム)を入力し最大16サイクル反復。
- 各サイクル内でコンテキスト埋め込みを18回再帰的に更新。更新はネットワークのフォワードパス。
- 各サイクルは1回のフォワードで改善解を出し、真値との差異を最小化し正解解を分類。正解と判定した時点で停止。
- 推論時は同様の手順を経て解を生成。
結果:TRMは先行するHierarchical Reasoning Model (HRM)(2700万パラメータ)および事前学習済LLMを上回った。
- Sudoku-ExtremeおよびMaze-HardでTRM(87.4%、85.3%)はHRM(55%、74.5%)を上回り、Anthropic Claude Sonnet 3.7、DeepSeek-R1、OpenAI o3-miniの高推論は0%。
- ARC-AGI-1では、TRM(44.6%pass@2)はxAI Grok 4(思考モード有効66.7%)に及ばずも、HRM(40.3%)、Gemini 2.5 Pro(37%)、Claude Sonnet 3.7(思考有効28.6%)を上回る。
- より難解なARC-AGI-2ではTRM(7.8%pass@2)はGrok 4(16.0%pass@2)に劣るが、HRM(5.0%)、Gemini 2.5 Pro(4.9%)、Claude Sonnet 3.7(0.7%)より優位。
重要性:小型モデルが多面的に完璧な解を必要とする複雑パズルに強い。シンプルで特化したアーキテクチャの訓練は単純なスケールより効果的かつ効率的。
考察:LLMは最終出力の前に1回のモデル実行で連鎖的思考を生成。一方TRMは最終出力前に1回のモデル実行でコンテキスト埋め込みを再帰的に更新し推論。