親愛なる皆さん、
私は、あらゆる階層の人たちから「仕事の不安定さを感じる」という声を聞いています。高校生は、自分たちに仕事があるのかと疑問に思い、エンジニアはついていき続けることを心配し、Cレベルの役員はAIによる事業変革を自分たちが支えられるのかと考えています。さらに多くの人が同じように不安を抱えています。AIの進歩が目まぐるしく、そして複数の地政学的な不確実性が重なっている中で、未来は、私がこれまでに思い出せるどの時点よりも、今は不確実に感じられます。このようなとき、私はこれから先にあるワクワクする可能性を活かすために、私たちが何を作れるのかを考えます。しかし同時に、私が頼りにできて安定しているもの、たとえばコミュニティやスキルについても考えます。不確実な環境の中を歩んでいる皆さんに、これが少しでも安心につながればと思います。
AIの進歩が目まぐるしいため、仕事の将来や多くの企業の将来は不確実です。事業面では、ベンチャー投資家のChamath Palihapitiya氏が、AIによって企業が混乱に直面することで株価がどう影響を受けるかについて、思慮深いarticle を書いています。内容は、AIによる破壊が起きたときに企業がどうなるか、それにより株価がどう影響を受けるかという話です。tl;dr。多くの企業の価値は、長期的に生み出すことが期待されるキャッシュフローにあります。そして、AIによる混乱によってそのキャッシュフローが損なわれる可能性があるなら、企業の価値は大幅に下がります。
さらに、最前線のAIラボの代表者が将来について自信に満ちた予測を語ることが多いとしても、私が彼らの一部と個人的に話したところ、「数年後に本当に何が起きるのかは、実は自分たちにも分からない」と共有してくれました。ソフトウェアに関しては、いくつかの流れは明確です。高度にエージェント化されたコーディング・システムは引き続き改善していくでしょう。すでに深刻になっているプロダクトマネジメントのボトルネックは、さらに悪化するでしょう。そして、ますます多くの人がコーディングをするようになるはずです。しかし、こうした傾向がある一方で、将来のソフトウェアエンジニアリングが具体的にどのような姿になるのか、またソフトウェアエンジニアリングチームがどう組織化されるのかは、いまはまだゆっくりと輪郭が見えてきている段階にすぎません。
AIの進歩の速さとは別に、未来には多くの火種があり、それがリスクを増やしています。イランでの戦争は、痛ましい民間人の死者を生むだけでなく、ホルムズ海峡の封鎖にもつながっています。台湾の平和の将来に関する不確実性や、半導体供給への影響もあります。さらに、AIインフラへの過剰な投資の可能性、そしてレアアース(希土類)金属に対する中国の支配です。私たちの世界が相互につながっている以上、これらのいずれもが世界のどこにいる人にも大きく影響し得ます。つまり、結果としてリスクは誰にとっても高まります。
ジェフ・ベゾスは、有名な言葉として「今後10年で変わらないことを知っていれば、それを土台にして事業を築くための安定した基盤ができる」と述べました。世界の中には、今と同じように10年後も変わらないことが非常に多くあります。しかし、仕事の不安定さを心配している個人に対しては、この期間において安定していると思うものを2つ挙げたいです。コミュニティとスキルです。

まず、10年後も私は、友人や家族が自分のそばにいてくれると分かっています。どんなことがあっても、私は彼らのそばにいると同じように分かっています。関係性は非常に長く続くことがあります。コロナ禍の間、多くのコミュニティが結びつき、互いを支え合いました。だからこそ、不確実な局面では、コミュニティ――関係性のネットワーク――を持つことが、誰にとっても助けになります。だから、関係性を築くための機会はとても価値があり、私たちがより多くのことを成し遂げると同時に、起こり得る下振れのリスクから身を守ることにもつながります。だから私は、人と実際に会う集まり――新しい友人を作り、既存の関係をリフレッシュできる場――が特に価値があると感じています。もしイベントに参加したい場合は、4月28日〜29日にサンフランシスコで開催されるAI Dev にぜひお越しください。
さらに、ある特定の企業がうまくいくかどうかは別として、多くのスキルは引き続き価値を持ち続けます。あなたのスキルは、いつでも自分と一緒に持ち運べるものです。そして、あなたが獲得したスキルを誰かが失わせることは決してできません。どのスキルが価値を持つかは変わっていくので、より多くの選択肢を得るためにも幅広いスキルに投資する価値があります。すぐには役に立たないかもしれないスキルでも、学んでおくことが有益になる可能性があります。また、スキルは互いに積み重なります(たとえば、プロンプトの理解はコーディング・エージェントを使うのに重要であり、AIの構成要素の理解は、特定のアプリケーションをどう設計するかを理解するのに重要です)。つまり、スキルを身につけることで、追加の知識を得やすくなります。そして、今のうちに幅広いスキルを作り上げておけば、どんなことが起きても、多種多様で価値のあることを成し遂げられるようになります。
私が今見ている多くのリスクは、うまくいって最終的には良い結果につながると楽観しています。私たちが共有するAIの未来は、今日のそれよりもはるかに明るいものになるでしょう。私は、皆さんを支えるためにここにいますし、AIコミュニティを支えるためにもここにいます。この変化が速く、不確実な世界を私たちが進んでいく中で、互いに助け合い、コミュニティを築き、そして互いが価値あるスキルを身につけ続けられるよう支え合いましょう。
作り続けましょう!
Andrew
DEEPLEARNING.AIからのメッセージ

オラクルとの共同制作による最新コースでは、LLMがセッションをまたいで知識を保存・検索・洗練できる、完全なエージェント用メモリシステムを構築します。これにより、ステートレスなエージェントを、時間とともに学習し改善していくエージェントへと変えられます。 こちらから登録
ニュース
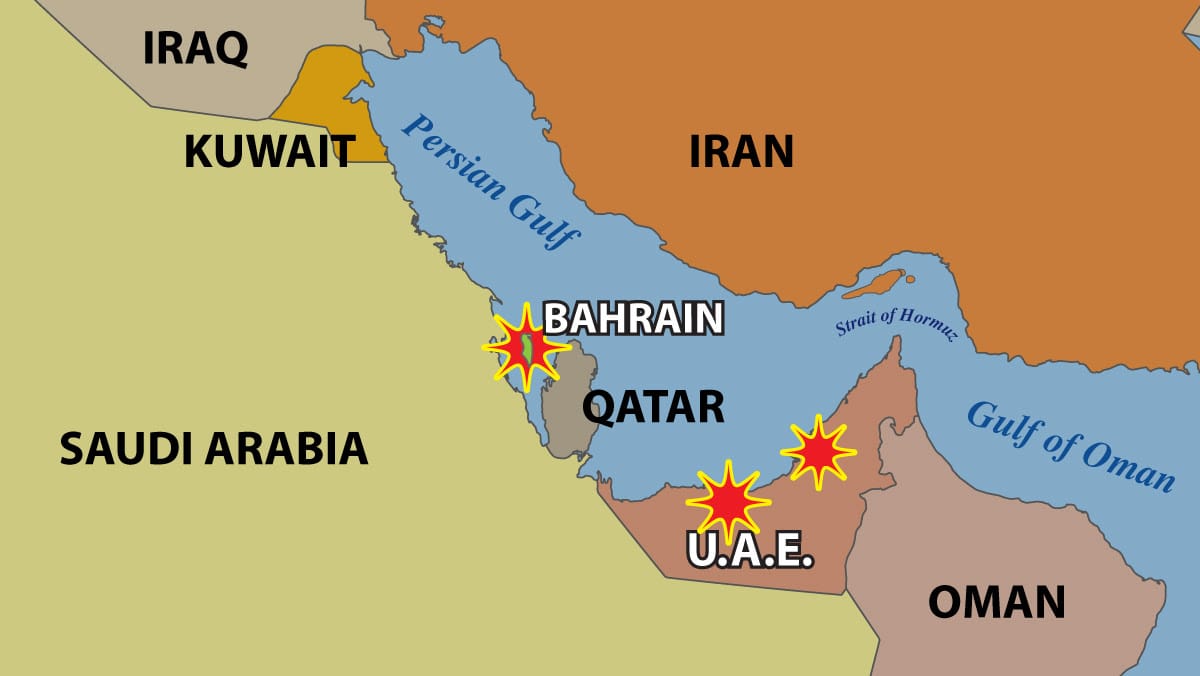
ドローンがペルシャ湾岸のデータセンターを攻撃
イランは中東にある少なくとも3つのアマゾンのデータセンターを攻撃した。これは、米国がイランと戦う上でAIが重要な役割を担っていることを示す兆候であり、さらに、この種の施設が戦闘の過程で標的にされたのが初めてである可能性もある。
何が起きたか: イランのドローンが 損傷を受けたのはバーレーンのアマゾン・ウェブ・サービス(AWS)施設で、さらにUAE(アラブ首長国連邦)の2施設でも被害が出た。これにより、銀行、決済、配車サービス、フードデリバリー、ビジネス用ソフトウェアなどを含むオンラインサービスが中断された。米軍は、 AWSを使用して、分類されていない版のAnthropicのClaudeや、場合によっては他の計算システムを稼働させている。しかし、攻撃がその運用に影響したかどうかは明らかにしていない。
ドローン攻撃: 3月1日の早い段階で、ドローンがUAEのAWSデータセンター2カ所を攻撃し、その後まもなくバーレーンのデータセンターでも被害が出た。アマゾンは、バーレーンでの攻撃について「当社施設の一つに近接した場所でのドローンによる攻撃」だったと述べる一方、イランは、これらの施設が「敵の軍事・諜報活動を支える役割を特定するため」に施設を狙ったのだと主張した。 と、イランの国営ファールス通信(Fars News Agency)がメッセージングサービスのTelegramを通じて伝えた。
- データセンターは、消防隊による消火に伴う構造的な損傷、停電、そして水害を受けた。その結果、サービスの停止が発生し、通常よりも高いエラー率となった。3月3日時点で、アマゾンは 推奨しており、クラウド・コンピューティングの顧客に対してデータのバックアップを取り、AWSの中東リージョンから米国、ヨーロッパ、またはアジア太平洋へとワークロードを移すよう求めている。
- 今回の攻撃は、ペルシア湾岸地域にAIハブを建設するための数兆ドル規模の投資を危険にさらすことになります。ニューヨーク・タイムズ 報じた。
- 湾岸協力会議(GCC)の加盟国は、バーレーン、クウェート、オマーン、カタール、サウジアラビア、アラブ首長国連邦を含む経済連合および軍事同盟ですが、データセンターの収容能力として2.0ギガワットを受け入れており、さらに0.4ギガワットの計画もあります。ビジネス・インサイダー 報じた。
ニュースの裏側:データセンターへのリスクは、戦争におけるAIの役割が高まっていることを映し出しています。最近、米軍が、Anthropicの大規模言語モデルであるClaudeの防衛目的での使用を禁じるという決定を下したにもかかわらず、米軍部隊はイランやその他の地域で、日常的にClaudeやほかのシステムをさまざまな目的に使っています。一方、イランは、ある程度の自律性を持つ武装ドローンを使用しています。
- Claudeは、米国がイランに対して戦争を開始して最初の24時間に、1,000以上の目標を選定するのを支援したシステムの一部でした。これにより、米軍は攻撃のテンポを大幅に加速できました。ワシントン・ポスト 報じた。Claudeは、Palantirが構築した、目標設定とロジスティクスのためのシステムであるMaven Smart System(MSS)に組み込まれています。致命的な局面では、誤りを避けるため、人間のアナリストが同システムの出力を確認します。演習では、MSSによって目標設定のプロセスが12時間から1分未満に短縮され、従来2,000人規模で必要だったものを、定員20人のスタッフで達成しました。アーミー・タイムズ 報じた。Claude/MSSは、ベネズエラ大統領ニコラス・マドゥロを拘束した1月の作戦にも関与しましたが、イランでの行動は「大規模な戦争作戦」での初使用です。
- 安価なドローンの使用は、最近の米国とイランの戦争における特徴的な要素になっています。イランは、大規模な攻撃ドローンの波——その多くは、低コストの「特攻」タイプで、自律航行し、命令を受けて攻撃する——で、最初の米国による爆撃キャンペーンに応じました。狙いは地域のインフラ、軍事施設、そして米国の資産でした。これに対して米国は、イランのShahed-136をモデルにしたLUCASシステムを含む、一方向攻撃用ドローンを自国でも解き放ちました。この種の戦い方は、ウクライナの革新に大きく依拠しています開発されたロシア・ウクライナ戦争の間に、ドローンの群れが――多くの場合ソフトウェアやAIと連携して――戦車、砲兵、そして兵站(ロジスティクス)の標的を破壊してきました.
はい、ただし: AIが軍事における意思決定のスピードを引き上げるほど、致命的な誤りが起きるリスクも同様に高まります。たとえばイランへの空爆の最初の波の間、爆弾が学校を破壊し、170人以上が死亡しました。犠牲者の大半は子どもでした。後続の調査では、予備的な結果が 示すところによれば、米軍が爆弾を投下した可能性が高いとされています。標的のデータが古かったことが、建物を狙う要因の一部になったかもしれません。というのも、その学校は約15年前に近隣の海軍基地の一部だったからです。
なぜ重要か: AIを活用した戦争の急激な増加は、戦闘のスピードが人間から機械のスピードへと移行していることを示しています。AIにより、成功につながる可能性が最も高い行動を特定するために大量のシミュレーションを実行して任務を計画することが現実的になります。AIは、戦場の現実を覆い隠しうるいわゆる「戦場の霧」を減らしながら、戦場における意思決定と行動を加速させます。これまで、戦場の通信、画像、その他の情報の洪水を分析する際に人間の注意が足かせとなって実現できなかった任務が、実行可能になります。この加速によって紛争の一部フェーズが短縮される可能性はある一方で、壊滅的な結果を招き得る「瞬時の判断」を迫られる圧力も高まります。
私たちはこう考えています: AIが生成した提案は、情報を検証する必要、前提に疑問を投げかける必要、そして武力行使を用いることの道徳的・戦略的な帰結を比較考量する必要をなくしません。
Qwen3.5 はより大きなモデルを上回り、ビジョンのベンチマークで先頭に立つ
Qwen3.5ファミリーのオープンウェイトのビジョン言語モデルには、印象的な大型モデルに加えて、OpenAIのオープンウェイトモデルより10倍大きいものを上回る小型モデルも含まれています。
新しい内容: Alibabaは、8つのオープンウェイト・ビジョン言語モデルからなる Qwen3.5ファミリーを公開しました。最大のモデルはQwen3.5-397B-A17B(パラメータ3970億、トークンあたりアクティブ17B)で、オープンウェイトが提供されます。また、Qwen3.5-PlusはQwen3.5-397B-A17Bのホスト型(提供・稼働環境が用意された形)で、より大きな入力コンテキストと、自律的に選択できる内蔵ツールを提供することで、エージェント型アプリケーションをサポートします。中規模の4つのモデルには、オープンウェイトのQwen3.5-122B-A10B、Qwen3.5-35B-A3B、Qwen3.5-27Bに加えて、エージェント型アプリケーション向けに装備されたホスト型のQwen3.5-Flash(Qwen3.5-53B-A3Bの派生)が含まれます。ファミリーの中でもより小型のQwen3.5メンバー――Qwen3.5-9B、Qwen3.5-4B、Qwen3.5-2B、Qwen3.5-0.8B――では、パラメータ90億版と40億版が、はるかに大きいモデルの性能に匹敵します。
- 入出力: 入力(オープンウェイトモデルは254,000トークンまで拡張可能で最大1,000,000トークン、ホスト型モデルはデフォルトで最大1,000,000トークン)、出力テキスト(最大64,000トークン)
- アーキテクチャ: 混合専門(Mixture-of-experts)または密なトランスフォーマに、混在アテンションとGated DeltaNet層を組み合わせた構成。ビジョンエンコーダは明記されていません
- 性能: 全体として優れたビジョン性能。Qwen3.5-9B(90億パラメータ)は、多くの言語タスクでgpt-oss-120B(1200億パラメータ)を上回ります。
- 利用可能性: オープンウェイトはApache 2.0ライセンスの下で自由に 利用可能です。Alibaba CloudのModel Studio経由で提供される、ホスト型オープンウェイトモデル向けのAPI(価格は特定のモデルにより異なり、入力/出力1,000,000トークンあたり$0.20〜$0.60/$2〜$3.6)。Qwen3.5-PlusのAPIは$0.4/$0.04/$2.4。Qwen3.5-FlashのAPIは、入力/キャッシュ/出力1,000,000トークンあたり$0.1/$0.01/$0.4です。
- 特徴: 201の言語、ツール利用、Web検索、推論(chain-of-thought)
- 未公表: 視覚エンコーダ、学習データ、手法
仕組み: Alibabaは、Qwen3.5ファミリーをどのように構築したかについてほとんど情報を明かしていない。
- Qwen3.5は、Qwen3-Nextのアーキテクチャ、Qwen3-30B-A3Bのアーキテクチャと学習手法のバリエーションで、学習の効率と安定性を高めるように改変されている。
- Qwen3.5は、Qwen3よりも「はるかに大規模な視覚-テキストトークン」を用いて学習された。
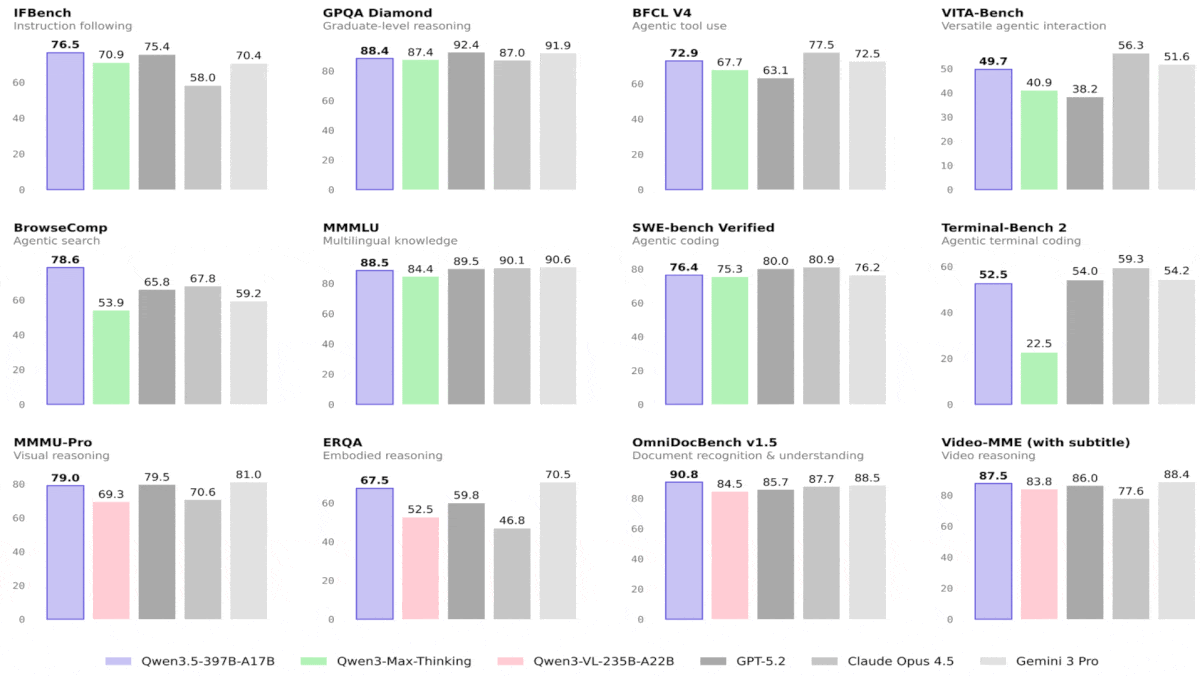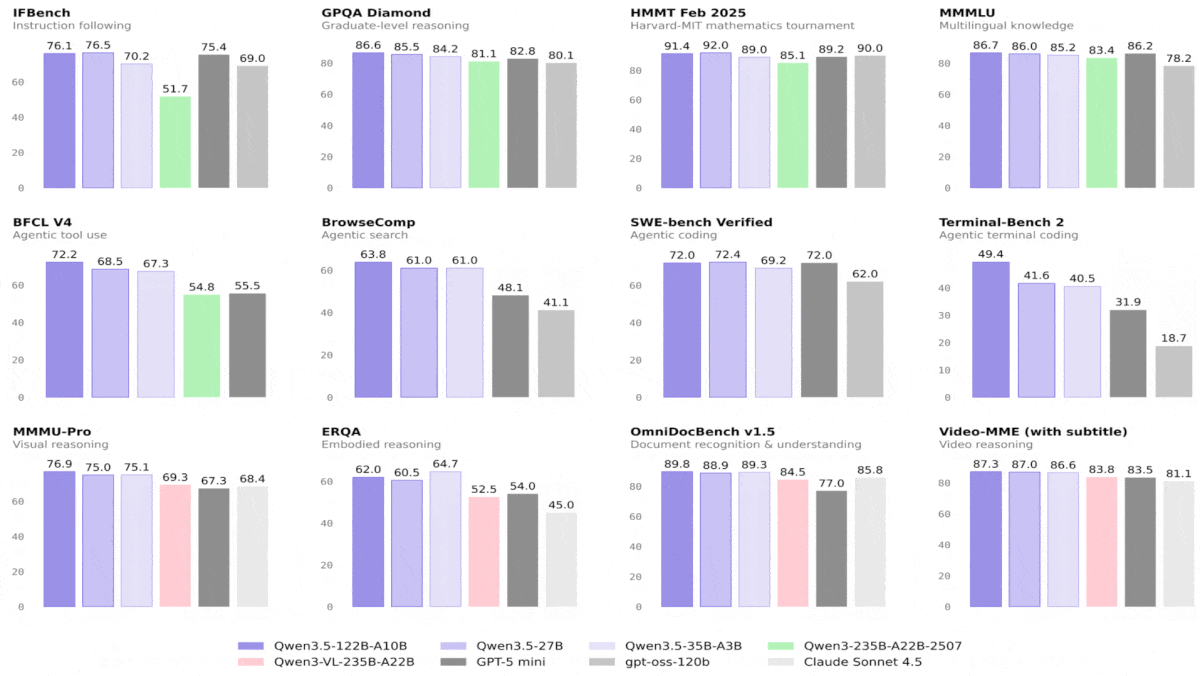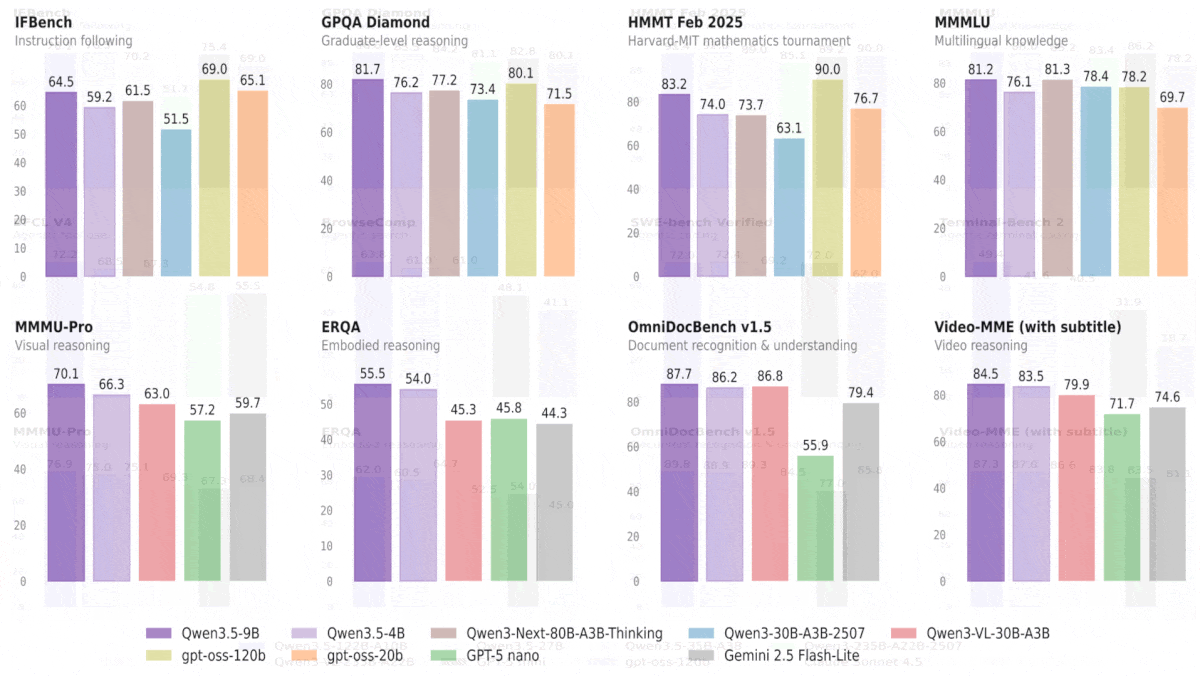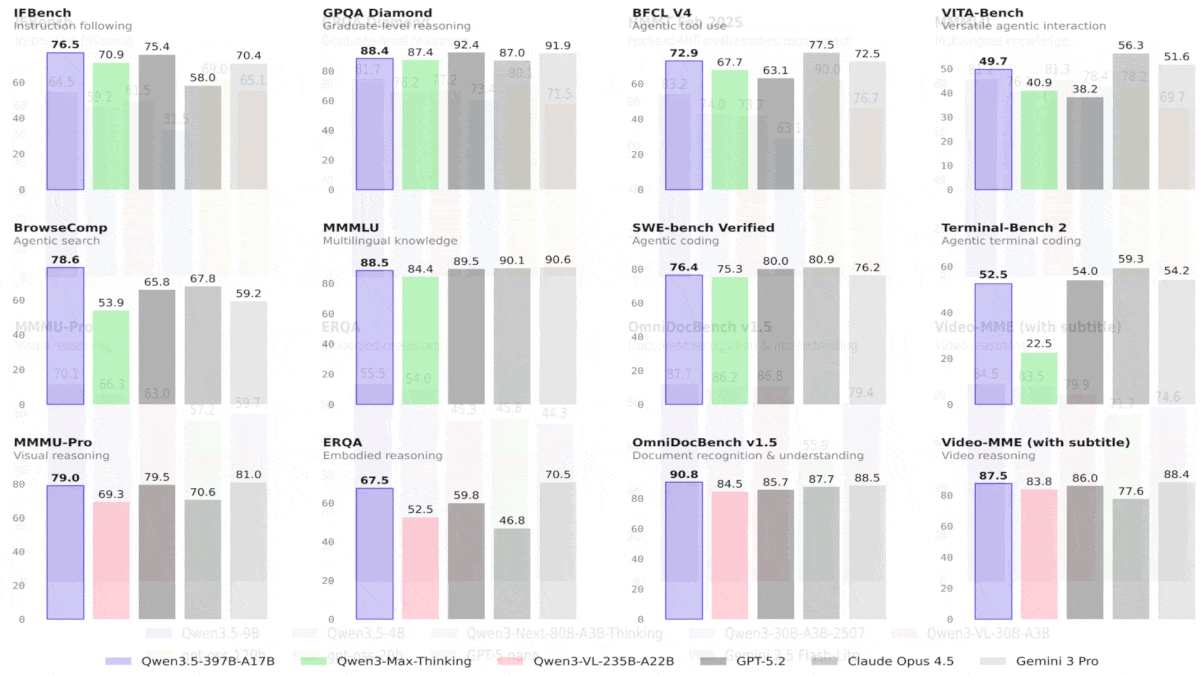
結果: Alibabaがテストしたところ、すべてのQwen3.5モデルは視覚タスクで優れた性能を示し、はるかに大きなモデルを上回った。さらに、一部のモデルは言語タスクでも競争力のある結果を出した。Qwen3.5-9BとQwen3.5-4Bは、全体として最も印象的な性能を示し、視覚・言語の両方のタスクで、はるかに大きなモデルと比べても光った。最小の2つのバリエーションには比較指標がない。
- 44の視覚ベンチマーク中28で、Qwen3.5-397B-A17Bが、GPT-5.2、Claude 4.5 Opus、Gemini-3 Proに勝った。これらはいずれもパラメータ数が非公開だが、ほぼ確実にQwen3.5-397B-A17Bよりずっと大きい。さまざまな言語タスクでも、Qwen3.5-397B-A17BはGPT-5.2、Claude 4.5 Opus、またはGemini-3 Proのいずれかを上回ったが、一般的には3つすべてを上回ることはなかった。
- テストされたほとんどの言語および視覚ベンチマークで、Qwen3.5-122B-A10BとQwen3.5-27BはGPT-5-mini(パラメータ数は非公開)を上回った。一般に、トークンごとに100億パラメータを活性化する混合専門家(mixture-of-experts)アーキテクチャであるQwen3.5-122B-A10Bは、270億パラメータの密な(dense)アーキテクチャであるQwen3.5-27Bを上回った。Qwen3.5-35B-A3Bは概して小型のQwen3.5-27BおよびQwen3.5-122B-A10Bに及ばなかったが、それでもテストされた74のベンチマーク中58でGPT-5-miniを上回った。
- Qwen3.5-9Bは、推論およびコーディングのタスクを除くほとんどの言語ベンチマークで、OpenAIの言語モデルgpt-oss-120b(それより10倍以上大きい)を大きく引き離した。同様に、Qwen3.5-4Bも、推論およびコーディングのタスクを除くほとんどの言語ベンチマークで、OpenAIの言語モデルgpt-oss-20bを上回った。テストされたほとんどの視覚ベンチマークでは、Qwen3.5-9BとQwen3.5-4Bの双方が、視覚-言語モデルであるGPT-5-nanoおよびGemini-2.5-Flash-Liteを上回った。
裏側のニュース: Qwenファミリーの展開が始まってまもなく、モデルの技術リードであり主要なアーキテクトでもあるLin Junyangが、X(旧Twitter)上で「Bye my beloved qwen.(愛するQwenよ、さようなら)」と読める投稿を行った直後に、突然辞任した。その後、中国のテック系ニュース媒体36kr.comは、彼に続いてチームの他の4名のメンバーも辞任したと報じた。1月の公開登場で、Linは「私たちは手一杯だ——納品の要求を満たすだけで、ほとんどのリソースを使い切ってしまう」と述べた。Bloombergは、さらに詳しく報じた。Alibabaは対応として、Qwenプロジェクトを上級幹部によるより厳格な監督下に置き、AI開発への投資することを約束した。
重要な理由:すべてのQwen3.5モデルは、そのサイズに応じて卓越した視覚性能を提供しますが、なかでも小型モデル——とりわけQwen3.5-9B——は、消費者向けノートPC上で動かせるほど小さく、それでいて、以前ならNvidia H100のような80GB級のGPUが必要だったレベルの性能を実現しています。
考えていること:推論能力を備えたビジョン・ランゲージ・モデルが、ローカルで動かせるほど小型になれば、コストの削減、より高いプライバシー、新しいビジョン・ランゲージ応用の可能性が広がります。

DeepSeekがNvidiaを外してHuaweiへ
優れたオープンウェイトモデルを開発する中国企業DeepSeekは、同社のフラッグシップモデルの今後のアップデートについて、米国の半導体メーカーからの提供を拒んだ。これは、米国と中国の間でAI競争が激化していることをさらに強める動きだ。
新しくなった点:DeepSeekは、開発の最終段階にある予定の次期DeepSeek-V4について、まだNvidiaやAMDに対して、自社のチップ上で問題なく動作することを確認する機会を与えていない。これは、大規模モデルのアップデート前に通常行われる慣行とは異なる。しかし同社は、Huaweiに対してモデルのリリース前バージョンを共有しており、中国の半導体メーカーが自社のハードウェア向けにソフトウェアを最適化するために数週間の猶予を持てるようにした。Reuters 報じられた。ただし、当該の判断に至ったDeepSeekの推論(理由)については報告されていない。
仕組み:Reutersによると、チップメーカーは通常、新しいモデルが自社のハードウェア上で効率的に推論(インファレンス)できるかを確認するために、そのモデルを検証する。過去には、DeepSeekはNvidiaと緊密に連携して自社のモデルを学習してきた。
- 名前を明かしていないトランプ政権の上級当局者は、米国の輸出規制がそうした製品に適用されているにもかかわらず、DeepSeek-V4はNvidiaの最先端チップを使って中国で学習されたと述べた。Reuters 報じられた。ただし、当局者がこの情報をどのようにして入手したのかについては、把握できなかった。
- Nvidiaは、DeepSeek-V3を学習させる際にDeepSeekへ広範な技術支援を提供し、「大きな学習効率の向上」を達成したという。米下院の中国特別委員会の委員長は、1月にこう述べた。述べた。
報道の背景:長年、米国は高度なチップや、それらを生産するために必要な設備の輸出を制限することで、中国のAIの取り組みを鈍らせようとしてきた。しかし、この取り組みは大きく裏目に出ており、中国が国内の半導体産業を構築することを後押ししてしまった。さらに、中国政府は、その国内企業に対して国内チップの使用を奨励、あるいは義務付けるための措置も講じている。
- 中国で生産されたチップは、まだNvidiaが設計し、台湾のTSMC(台湾積体電路製造)で製造されたものに匹敵するには至っていないものの、中国企業、特にHuaweiはここ数年で着実に進歩している。
- 米国は2022年以降、制限を段階的に強化した後、1月には、そうした販売に対して25%の課徴金を課すことを条件に、最上位のAIチップの輸出をケースバイケースで認め始めた。ただし当局は、新たな輸出制限を検討している。
- 昨年、中国政府は、中国向けに設計されたNvidiaのH20チップについて安全保障上の審査を義務付けた。一方で、中国のAI企業には、必要な場合に限って外国チップを購入するよう求めた。
重要な理由:DeepSeekが米国のチップメーカーからDeepSeek-V4のリリース前アクセスを差し控えた判断は、実質的というより象徴的な意味合いが強いかもしれないが、米国に拠点を置くAIコミュニティの部分と、中国に拠点を置く部分との分断をさらに深めることになる。この判断は、中国が長年掲げてきた技術的自立の目標とも整合的であり、敵対者がそれを阻もうとする取り組みにかかわらず、重要なAI能力が利用可能な状態を保てる。
考えていること:DeepSeekが最新モデルをNvidiaのチップで学習した可能性は、輸出規制だけでは国際的な競合が米国のチップにアクセスすることを止められない、という複数の兆候のうちの1つだ。世界にとってより良いのは、交渉による制限の枠組み、相互協力、アイデア、技術、貿易の自由な交換である。

視覚メディアのための単一トークナイザー
マルチモーダルモデルは通常、異なるメディア種別を埋め込むために異なるトークナイザーを使い、また分類ではなくメディアを生成するように学習する際には、異なるエンコーダを用います。Appleのチームは、多次元トークナイザーを作成し、画像や動画だけでなく3Dオブジェクトも、これらの視覚メディアのいずれにも共通のトークン空間へマッピングしました — さらに、そのようなオブジェクトを同定することと生成することの両方で良好に機能する共通のエンコーダも用意しました。
新規性: AppleのJiasen Lu、Liangchen Song、および同僚たちは、 AToken、あらゆる用途の視覚トークナイザーを備えたトランスフォーマー・モデルを学習させました。この新しいモデルは、画像・動画・3Dの生成と分類の両方が可能であり、これらの入力と出力タイプごとに特化したモデルに近い性能に到達しています。
重要な洞察: 画像生成モデルは、エンコーダ(VAEやVQ-VAEのようなもの)を使って視覚的な細部(猫やボールの表面はオレンジか?)は保持しますが、セマンティクス(それが猫なのかボールなのか?)は捨ててしまうため、分類モデルほどにはオブジェクトを認識できません。 一方、画像分類モデルは、CLIPやSigLIPのようなエンコーダを使ってオブジェクトの種類(たとえば「cat」や「ball」)を捉えますが、視覚的な細部を取り逃します。そのため生成が苦手になります。静止画像から動画や3Dへ移ると、さらに状況は複雑になります。符号化(エンコード)される前に、動画や3Dは通常、画像を、エンコーダが処理できるデータへ分解するためにそれぞれ別々のトークナイザーを必要とし、それぞれが固有のアーキテクチャと埋め込み空間を持っています。 3種類のメディアを同じトークナイザーで単一の形式として解析すれば、1つのトランスフォーマーがそれらすべてに対して機能するように学習できます。さらに、これらのメディア種別を再構成して、対応するテキスト記述と整合させるようにモデルを学習させることで、埋め込みが微細な視覚的ディテールとセマンティックな参照の両方を保持するよう強制され、別々の生成モデルと分類モデルを用意する必要がなくなります。
仕組み: ATokenは、事前学習済みのSigLIP2 視覚エンコーダ(4億パラメータ)— ここでは2次元から4次元へ拡張しています — と同サイズの未学習デコーダから構成されています。著者らは、3つの画像セット(two public と1つの非公開)から学習させ、同時に3つの public sets of
動画、および一致するテキストを伴う2つの公開データセットの 3D。- 著者らは、あらゆる入力を空間・時間の座標(t, x, y, z)でトークンに分割しました。画像は1つの2次元(x,y)スライスとしてマッピングし、t = z = 0 を設定しました。動画には時間のための追加座標(t, x, y)が含まれ(z = 0)、3Dオブジェクトは t = 0 として (x, y, z) グリッドにマッピングされました。単一の線形層が各トークンを埋め込みへ変換しました。
- また、4D Rotary Position Embedding を用いて、時間・高さ・幅・奥行き(t, x, y, z)に沿った角度方向の位置をエンコードしました。エンコーダは、各線形埋め込みに対して相対的な位置情報を加え、入力を表す埋め込みを生成しました。
- デコーダは、エンコーダの埋め込みから入力を再構成しました。画像と動画についてはRGBピクセルを生成し、ガウス・スプラット — 小さく色付けされた3Dの塊で、これらをまとめてレンダリングすると一貫した3D形状になるもの — を3Dオブジェクト用に生成しました。ATokenは4つの損失によって入力を再構成することを学習しました。(i)最初の損失は、予測されたピクセルと正解のピクセルの差を最小化します。(ii)LPIPS(ランディングページが見つかりません)で、元の AlexNet の埋め込みと、再構成されたものの埋め込みとの距離を最小化します。(iii)CLIPのパーセプチュアル損失で、再構成結果のCLIP埋め込みと元のCLIP埋め込みの距離を最小化します。(iv)Gram行列損失で、再構成と元画像に対する埋め込みの相関を、名前の明かされていない事前学習済みネットワークから最大化することにより、スタイルや個々の特徴の違いを最小化します。
- 視覚入力の埋め込みを、それに対応するキャプションの埋め込みと整合させるために、著者らは、注意によってエンコーダのすべての埋め込みを結合し、入力を要約する1つのグローバル埋め込みを生成しました。このプロセスはattention poolingと呼ばれます。彼らは、対応するキャプションに対するグローバルな視覚埋め込みとSigLIP2のテキスト埋め込みの類似度を高める一方で、不一致のキャプションの埋め込みとの類似度を下げるために、コントラスト損失を用いました。
結果: ATokenは、画像、動画、または3Dを処理する最先端モデルに一致するか、非常に近い性能を達成しました。
- 画像分類では、ATokenはImageNetの分類精度82.2%を達成し、スタンドアロンのSigLIP2(83.4%)のような専用の画像エンコーダに非常に近い結果でした。画像生成では、0.21 rFID(再構成品質の指標。低いほど良い)を達成しました。これは、UniTokのような統一トークナイザを用いる従来モデルを上回り、これは入力の種類ごとに専用のエンコーダを使用するものです。また、FLUX.1 [dev]のような専用モデルにも迫り、FLUX.1 [dev]は0.18 rFIDを達成しています。
- 動画をTokenBench データセット上で再構成するとき、ATokenは36.07 PSNR(フレームごとの画素類似度で、すべてのフレームにわたって平均—高いほど良い)と3.01 rFVD(再構成品質の指標—低いほど良い)を達成しました。これは、Wan2.2(36.39 PSNR、3.19 rFVD)や、HunyuanVideo(36.37 PSNR、3.78 rFVD)を上回りました。一方でATokenは、動画品質という点ではこれらを上回っていたものの、画素類似度の点では下回っていました。テキストプロンプトから動画を特定するよう求められたとき、ATokenは MSR-VTTMSR-VTT データセットにおいて、正しい動画を見つけた割合は40.2%でしたが、依然として強力な動画専用エンコーダの下でした。VideoPrism-gは、52.7%に到達しました。
- 3DオブジェクトをToys4K データから再構成すると、28.28 PSNR(再構成された3Dレンダリングが元のものにどれだけ近いかを測る指標で、高いほど良い)を達成しました。これは、専門的な3DトークナイザであるTrellis-SLATが記録した26.97 PSNRを上回りました。
重要な理由:大規模言語モデルの大きなイノベーションの1つは、コード、対話、テーブル、書籍など、すべての言語入力に対して単一のトークナイザを用いる点です。この汎用性により、学習中にあるデータソースから別のデータソースへと知識を転移しやすくなります。モデルがテキストの理解や生成が上手になるほど、コードも同様に上手になります。ATokenは、視覚モデルに対しても同様の汎用性を提供し、特に2Dおよび3Dオブジェクトにおいてその効果が期待されます。ATokenが複数の種類の視覚メディアの生成と再構成で強い性能を示していることは、ここでも共有トークナイザとエンコーダによって、あるモダリティでの改善が他のモダリティへも引き継がれ得ることを示唆しています。
考えていること:ATokenのようなモデルは、合成3Dデータや動画データの生成に役立つ可能性があります。あるメディア種類から別の種類へと一般化できるモデルは、各タスクを学習するために必要な総データ量を一般に減らします。たとえば、高品質で適切にラベル付けされた2次元画像データは、動画や3Dに比べて豊富です。動画と3Dはいずれもロボティクス用途に不可欠です。




