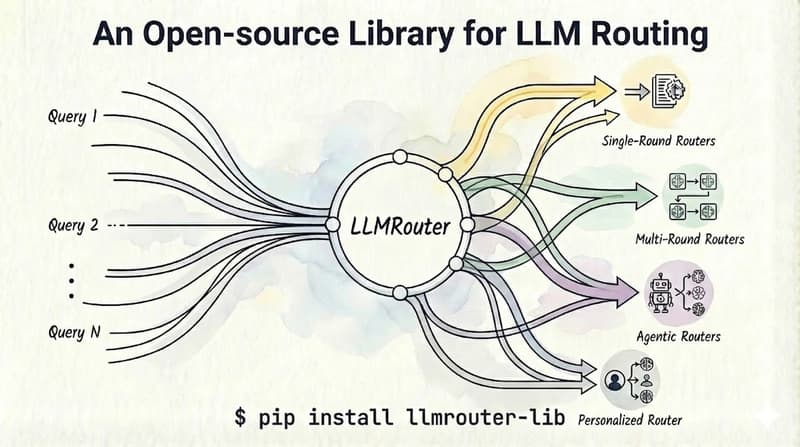
NVIDIA Researchによる新しい論文が、vLLMバックエンドを用いて、推測デコーディングをNeMo RLに直接統合します。これにより、8Bおよび予測される235Bモデル規模の両方で、ロスレスなロールアウト加速を実現します。
この投稿 A New NVIDIA Research Shows Speculative Decoding in NeMo RL Achieves 1.8× Rollout Generation Speedup at 8B and Projects 2.5× End-to-End Speedup at 235B は、MarkTechPostに最初に掲載されました。