Qwen3モデルをvLLM、Kubernetes、AWS AIチップでデプロイすることで、インタートークン・レイテンシがより速くなることを示す実践的なベンチマーク。
推測デコード(Speculative decoding)は、AWS Trainium上でデコード中心のワークロードに対してトークン生成を最大3倍加速し、出力トークンあたりのコストを抑えつつ、出力品質を犠牲にすることなくスループットを向上させます。AIライティングアシスタント、コーディングエージェント、その他の生成AIアプリケーションを構築している場合、あなたのワークロードは「消費するトークン」よりもはるかに多くの「トークン」を生成する傾向があります。そのため、推論コストの大部分はデコード段階が占めることになります。自己回帰的デコードではトークンが逐次的に生成されるため、ハードウェア・アクセラレータはメモリ帯域に制約され、十分に活用されません。これが、生成されたトークンあたりのコストを押し上げます。推測デコードはこのボトルネックに対処し、小さなドラフトモデルが複数のトークンを一度に提案し、ターゲットモデルがそれを1回のフォワードパスで検証できるようにします。逐次的なデコードステップが減ることで、レイテンシが下がり、ハードウェアの利用効率が高まり、推論コストの削減につながります。
本記事では、次を学びます:
- AWS Trainium2で、推測デコードがどのように機能し、生成トークンあたりのコストを下げるのにどう役立つか
- TrainiumでvLLMにより推測デコードを有効化する方法
- 性能を評価するために使用したベンチマーク手法
- ワークロードに合わせてドラフトモデルの選択と推測トークンウィンドウサイズを調整する方法
- Qwen3を使って結果を再現するための手順を、段階的に説明
推測デコードとは何ですか?
推測デコードは、2つのモデルを使うことで自己回帰的生成を高速化します:
- ドラフトモデルがn個の候補トークンを素早く提案します。
- ターゲットモデルがそれらを1回のフォワードパスで検証します。
トークンの受理・拒否、EAGLEベースの推測、一般的な推測デコードの概念など、内部メカニズムをさらに深く見るには、AWS Inferentia2上でのブログ記事Inferentia2このSageMaker EAGLEの手順解説、このSageMaker EAGLEの手順解説、およびこの入門記事をご覧ください。ここでは、実際に制御できる2つの主要パラメータに焦点を当てます:ドラフトモデルとnum_speculative_tokensです。
ドラフトモデルとターゲットモデルは、同じトークナイザと語彙を共有している必要があります。推測デコードは、ターゲットモデルによって直接検証されるトークンIDに基づいて動作するためです。同一のアーキテクチャファミリからモデルを選ぶことを推奨します。次トークン予測の一致率が高くなるためです。トークナイザが共有されていれば、異なるアーキテクチャのモデル同士を組み合わせることも可能ですが、ドラフトモデルとターゲットモデルの一致が低いと、受理率が下がり、性能向上の大部分が失われます。
ターゲットモデルがドラフトトークンを受理する場合、それらは逐次デコードステップ全体のコストを支払わずにコミットされます。主に制御するパラメータはnum_speculative_tokensで、ドラフトモデルが一度に提案するトークン数を設定します。この値を増やすと、受理率が高い場合に、検証1回あたりでスキップできる逐次デコードステップが増えます。結果として、インタートークン・レイテンシが直接的に低減されます。
性能向上は、2つの効果によってもたらされます。まず、推測デコードによりターゲットモデルのデコードステップ数が減るため、KVキャッシュのメモリ往復回数が減ります。(KVキャッシュは、事前に計算されたキーおよびバリューのテンソルを保持し、モデルが過去トークンに対する注意計算を再計算しないようにします。各デコードステップでは、メモリからキャッシュ全体を読み込むため、デコードはメモリ帯域に制約されます。)次に、推測デコードはデコード中のハードウェア利用率を改善します。標準的な自己回帰デコードでは、各デコードステップが新しいトークンを1つしか生成しません。そのため、アクセラレータは1トークン分の作業を行うために高コストな行列乗算カーネルを起動するだけとなり、処理要素エンジンはほとんど活用されないままになります。一方、検証ではターゲットモデルがn個のトークンをまとめて処理します。これにより、メモリアクセスがならされ、個々の小さく非効率な「単一トークン」計算の連なりが、より計算密度の高いワークロードへと変わります。num_speculative_tokensを低く設定しすぎると、速度向上が頭打ちになります。
逆に高く設定しすぎると、早期拒否が起こりやすくなり、ドラフト側の計算が無駄になり、ターゲットモデルの検証コストが上がります。この値は、観測した受理率に基づいて、ドラフトの計算コストと検証コストのバランスを取りながら調整します。
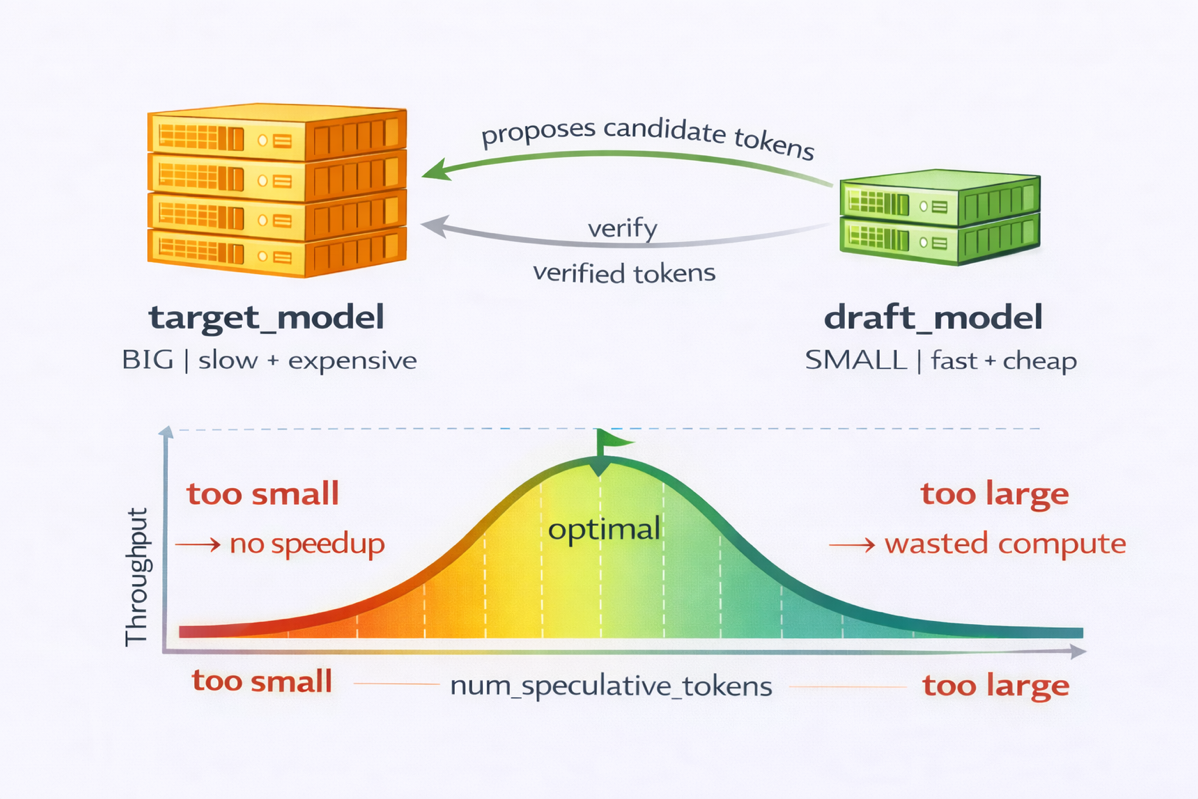
図1 推測デコード設定のトレードオフ
これらのトレードオフを示すために、Qwen3-0.6BとQwen3-1.7Bのドラフトモデルを比較しました。小さな0.6Bモデルは実行が速い一方で、受理率が約60%低く、その分だけ計算上の節約が相殺されました。Qwen3-1.7Bは、速度と受理のバランスがより良いところに着地しました。
num_speculative_tokensについては、5から15の値を評価しました。小さい設定(例えば5)では限定的なスピードアップしか得られませんでした。大きいウィンドウ(例えば15)は拒否が増え、性能が低下しました。最適な構成は、プロンプトの構造に大きく依存していました。反復、数値系列、単純なコードといった構造化プロンプトと、自由形式の自然言語の両方をテストしました。最も良いバランスは、7つの推測トークンを使うQwen3-1.7Bでした。詳細なチューニング内容は「Lessons learned」セクションをご覧ください。
NeuronX Distributed Inference(NxD Inference)がサポートするもの
AWS Neuron はAWS AIチップ向けのSDKです。NeuronX Distributed Inference(NxDI)は、TrainiumおよびInferentia上でスケーラブルかつ高性能なLLM推論を行うためのライブラリです。NxDIは、Trainiumにおける推測デコードを4つのモードでネイティブにサポートします:
- バニラ推測デコード — ドラフトモデルとターゲットモデルを別々にコンパイルします。最もシンプルに始められる方法です。
- 融合推測(Fused speculation)— 改善された性能のために、ドラフトモデルとターゲットモデルを一緒にコンパイルします。本記事で使用するのはこのモードです。
- EAGLE推測 — ドラフトモデルがターゲットモデルの隠れ状態コンテキストを活用することで、受理率を向上させます。
- Medusa推測 — 複数の小さな予測ヘッドを並列に動かしてトークンを提案し、ドラフトモデル側のオーバーヘッドを削減します。 返却形式: {"translated": "翻訳されたHTML"}
完全なドキュメントについては、Speculative Decoding ガイドおよびEAGLE Speculative Decoding ガイドを参照してください。この記事では、ドラフトモデル(Qwen3-1.7B)とターゲットモデル(Qwen3-32B)をNeuron向けに最適化された形で enable_fused_speculation=true を指定して一体的にコンパイルする、fused speculation を使用しています。
AWS Trainium での speculative decoding を始める
同一の Amazon Elastic Kubernetes Service(Amazon EKS) クラスター上の Trainium インスタンスに、vLLM の推論サービスを2つデプロイします。パフォーマンスへの影響を切り分けるため、デコード方法以外はすべて同一に保ちます。ベースラインのサービス(qwen-vllm)は、標準のデコードで Qwen3-32B を提供します。speculative のサービス(qwen-sd-vllm)は、同じ Qwen3-32B のターゲットモデルに対して、num_speculative_tokens=7 を指定した Qwen3-1.7B のドラフトモデルを追加して提供します。
両サービスは Trn2(trn2.48xlarge)上で同一の設定を実行します。すなわち、同じアクセラレータ割り当て、テンソル並列(大規模モデルに対応するために複数の NeuronCore にモデル重みを分散するもの)、シーケンス長、バッチング制限、Neuron DLC イメージです。違いは、speculative サービスに Qwen3-1.7B のドラフトモデルと num_speculative_tokens=7 を追加した点のみです。セットアップの詳細は図2を参照してください。
同一の負荷条件で2つの構成を比較するために、llmperf を使って両エンドポイントに対して同じトラフィックパターンを生成しました。インフラテレメトリは CloudWatch Container Insights で取得し、リクエスト単位のカスタムメトリクス(TTFT、トークン間レイテンシ、エンドツーエンドレイテンシ)を CloudWatch のダッシュボードに公開して、並べて分析できるようにしました。
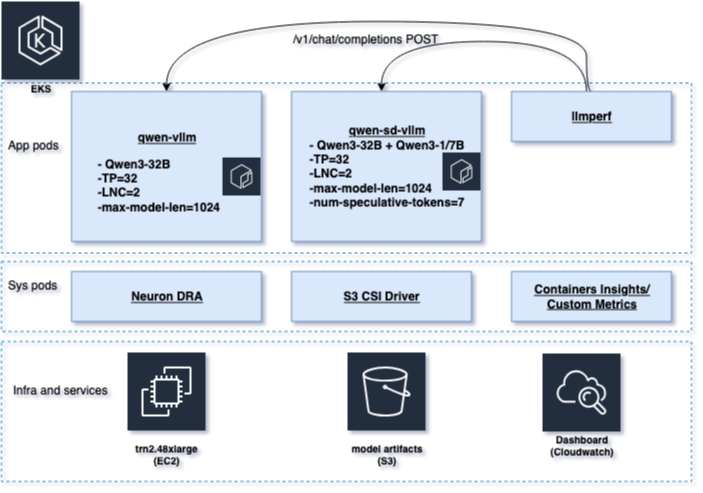
図2 システムアーキテクチャ
ベンチマークのセットアップ
私たちは LLMPerf を用いて、ベースラインおよび speculative decoding デプロイの両方に対し、構造化されデコード負荷が高いテストケースを実行しました。ベンチマークは Kubernetes のポッド内で実行されます。qwen-llmperf-pod.yaml では、両エンドポイントへ同時リクエストを発行し、トークンレベルのレイテンシメトリクスをログに記録します。テストケースは、高度に構造化されたプロンプト(反復シーケンス、数値の継続、単純なコードパターン)から、オープンエンドの自然言語補完まで幅広く含め、speculative decoding におけるベストケースとワーストケースの両方の挙動を網羅します。プロンプト一式は サンプルリポジトリで利用できます。
わかりやすさのため、分析では2種類の代表的なプロンプトタイプに絞ります。高い構造性を持つ決定的なプロンプト(反復テキスト生成)と、オープンエンドのプロンプトです。この2つのケースは、speculative decoding のベストケースとワーストケースの両方を示します。
ポッドでは、決定的なデコード経路を強調するため、入力長と出力長を制御し、temperature=0.0 で llmperf を実行しました。トークン間レイテンシ、TTFT、スループット、エンドツーエンドレイテンシなどのメトリクスを CloudWatch にログ出力し公開しました。
結果
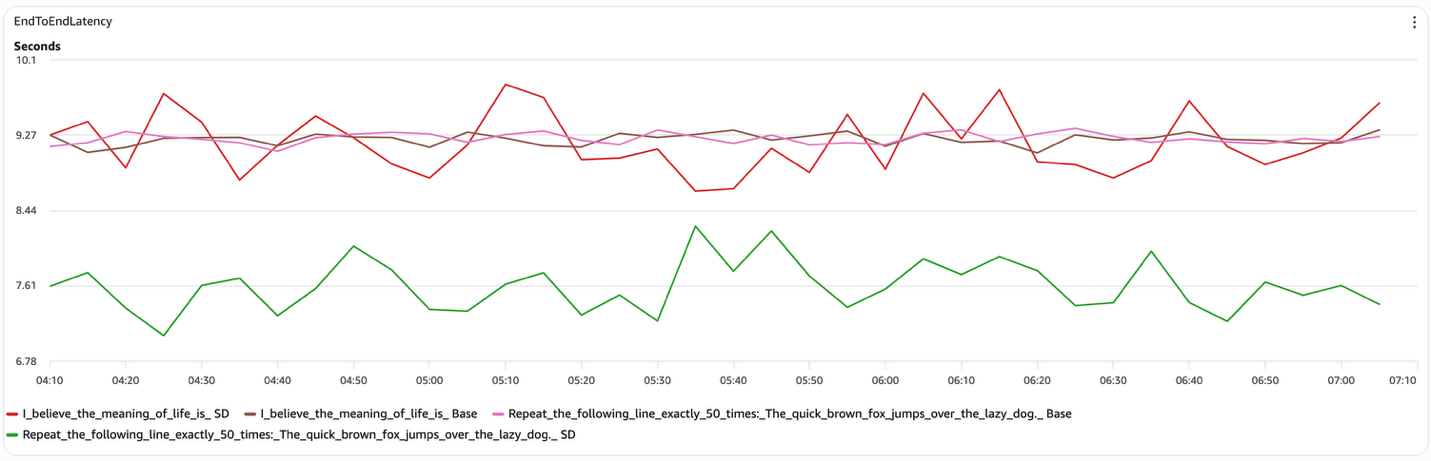
図3 speculative decoding の E2E レイテンシ
speculative decoding はレイテンシを選択的に低減します。その有効性はプロンプト構造に強く依存しており、この依存関係は計測した各指標に一貫して現れています。各プロンプトタイプで期待できることは以下のとおりです。
- 構造化プロンプト(たとえば「次の行を正確に50回繰り返して」)。speculative decoding は、エンドツーエンドレイテンシを測定可能に削減します。ドラフトモデルがターゲットモデルの生成内容を確実に予測できる場合、システムはターゲットモデルのデコードステップの相当な割合をスキップできます。私たちのテストでは、トークン間レイテンシが1トークンあたりおよそ15msまで低下しました(オープンエンドプロンプトでは約45ms)。また、speculative decoding のカーブは、実行中を通してベースラインを一貫して下回っていました。
- オープンエンドプロンプト(たとえば「人生の意味は〜だと考えています」)。speculative decoding は一貫した効果を提供しません。ドラフトモデルがターゲットモデルから頻繁に逸脱し、その結果としてトークンが却下され、潜在的な得を相殺してしまいます。speculative とベースラインのエンドツーエンドレイテンシカーブは概ね重なり、トークン間レイテンシは両構成で1トークンあたり約45msのままです。
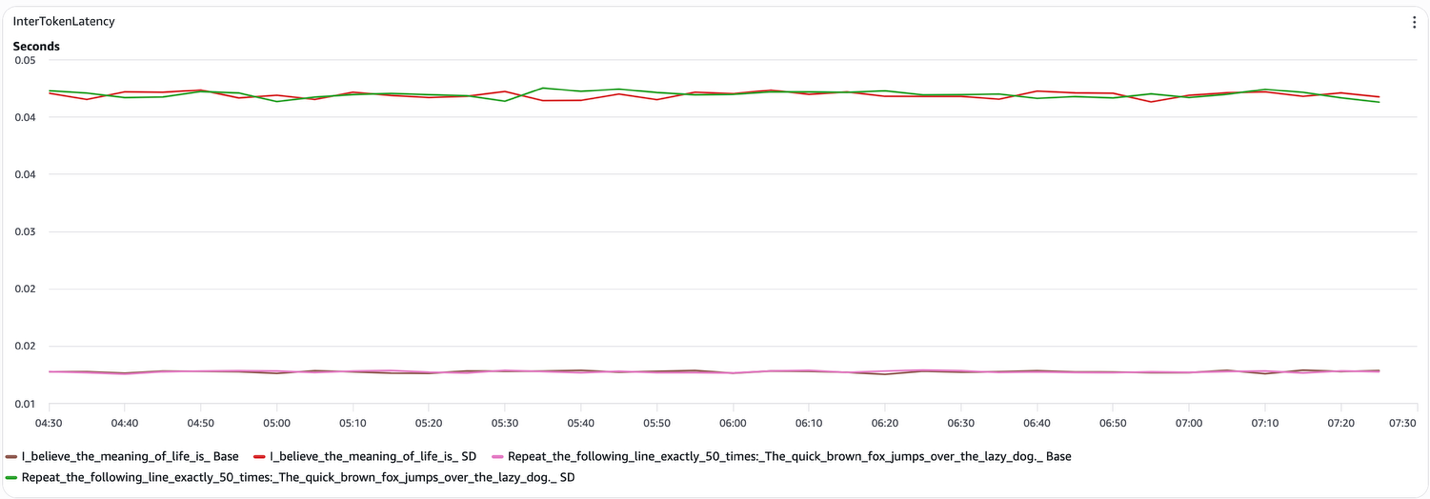
図4 speculative decoding のトークン間レイテンシ(デコード)
TTFT(Time to First Token)は、構成間で実質的に変化しません(図5)。TTFT はプリフィルフェーズに支配されます。この段階では、モデルが入力コンテキストをエンコードします。speculative decoding はこの段階を変更しないため、プリフィルのレイテンシは改善も悪化もしません。
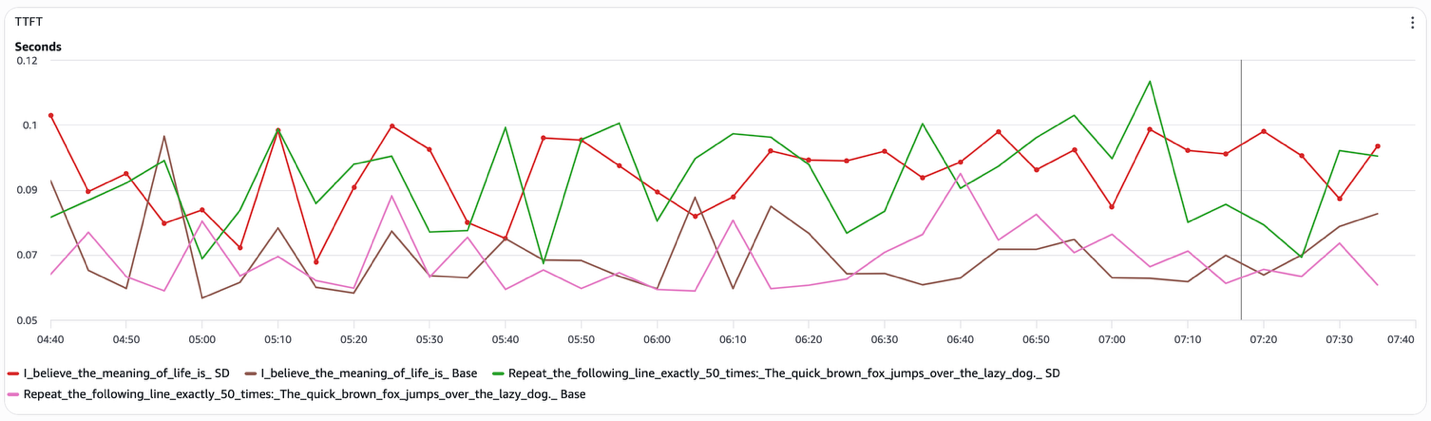
図5 speculative decoding の TTFT(プリフィル)
これらの結果を合わせると、speculative decoding はデコードステップ自体やプリフィルステージを高速化するのではなく、実行されるターゲットモデルのデコードステップ数を減らすことで、総レイテンシを改善することが示されています。したがって、構造化プロンプトではエンドツーエンドレイテンシに改善が現れる一方で、トークン間レイテンシとTTFTには改善が見られません。また、オープンエンド生成では speculative decoding がベースラインと同様の挙動に戻る理由もここで説明できます。
結果の再現
エンドツーエンドのコードサンプルと Kubernetes の構成は、AWS Neuron EKS samples リポジトリで提供しています。このリポジトリには以下が含まれます:
- Trn2でベースラインvLLMおよび推論デコード(speculative decoding)vLLMサービスをデプロイするためのKubernetesマニフェスト
- 融合(fused)推論デコードを有効化するためのvLLM設定フラグの例
- 負荷を生成し、メトリクスを収集するために使用したサンプル
llmperfベンチマークスクリプト - S3 CSI Driverを通じてモデルのチェックポイントおよびコンパイル済みアーティファクトをマウントするための手順
- Neuron DRA、テンソル並列(tensor parallelism)、およびNeuronCoreの配置を設定するためのガイダンス
これらのサンプルにより、本記事で紹介した実験環境を、モデルのデプロイからベンチマークおよびメトリクス収集まで同じように再現できます。
まとめ
デコード中心のLLMワークロードは、自回帰(autoregressive)生成の逐次的な性質によって制約されます。推論デコードは、出力全体を生成するのに必要なターゲットモデルのデコード手順の数を減らすことで、AWS Trainium2上でこのボトルネックを打破します。これにより、実質的に1回のフォワードパスあたりに生成されるトークン数が増加します。コード生成、構造化データの抽出、テンプレート化されたレポート生成、設定ファイルの合成など、出力空間が予測可能なワークロードでは、品質を犠牲にすることなく、出力トークンあたりのコストの低下とスループットの向上に直結します。推論デコードは万能の最適化ではありません。その有効性は、プロンプトの構造、ドラフトモデルの品質、推論パラメータのチューニングに依存します。適切なワークロードに適用した場合、Trainiumベースの推論システムで意味のあるレイテンシおよびコストの改善をもたらします。
次のステップ
AWS Trainiumで推論デコードを始めるには、以下のリソースを参照してください:
- AWS Trainiumプロダクトページ — Trainiumインスタンスタイプ、機能、料金について学びます。
- NeuronX Distributed Inference開発者ガイド — NxDIの推論デコード設定オプションを含む完全なドキュメントです。
- NxDI 推論デコード(speculative decoding)機能ガイド — vanilla、fused、EAGLE、Medusaの推論モードを有効化するための参照情報です。
- vLLMドキュメント — 本番環境でのLLMサービングのためにvLLMを設定する方法を学びます。
- Amazon EKSドキュメント — 推論サービスのデプロイとスケーリングのために、AWS上でのKubernetesを始めましょう。
- AWS Neuron EKSサンプルリポジトリ — 本記事のベンチマークを再現するためのエンドツーエンドのコードサンプルです。
- Amazon CloudWatchドキュメント — 推論エンドポイントを監視するためのダッシュボードとカスタムメトリクスを設定します。




