Gemma 4: バイト単位で、最も高性能なオープンモデル

お使いのブラウザは音声要素をサポートしていません。
本日、Gemma 4 — これまでで最も知能の高いオープンモデル — を発表します。高度な推論とエージェント型のワークフローのために設計されたGemma 4は、パラメータあたりの知能において前例のない水準を実現しています。このブレークスルーは、驚くべきコミュニティの勢いに支えられています。最初の世代の提供開始以来、開発者はGemmaを4億回以上ダウンロードしており、100,000を超えるバリエーションからなる活気あるGemmaverseを築いてきました。私たちは、AIの限界を押し広げるために次に必要なものを、イノベーターの声をもとに慎重に耳を傾けました。そしてGemma 4は、その答えです。Apache 2.0ライセンスのもとで、ブレークスルー級の能力を広く利用できるようにしました。
4/1時点の、Arena.aiのチャットアリーナにおけるオープンモデルの性能とサイズの比較。
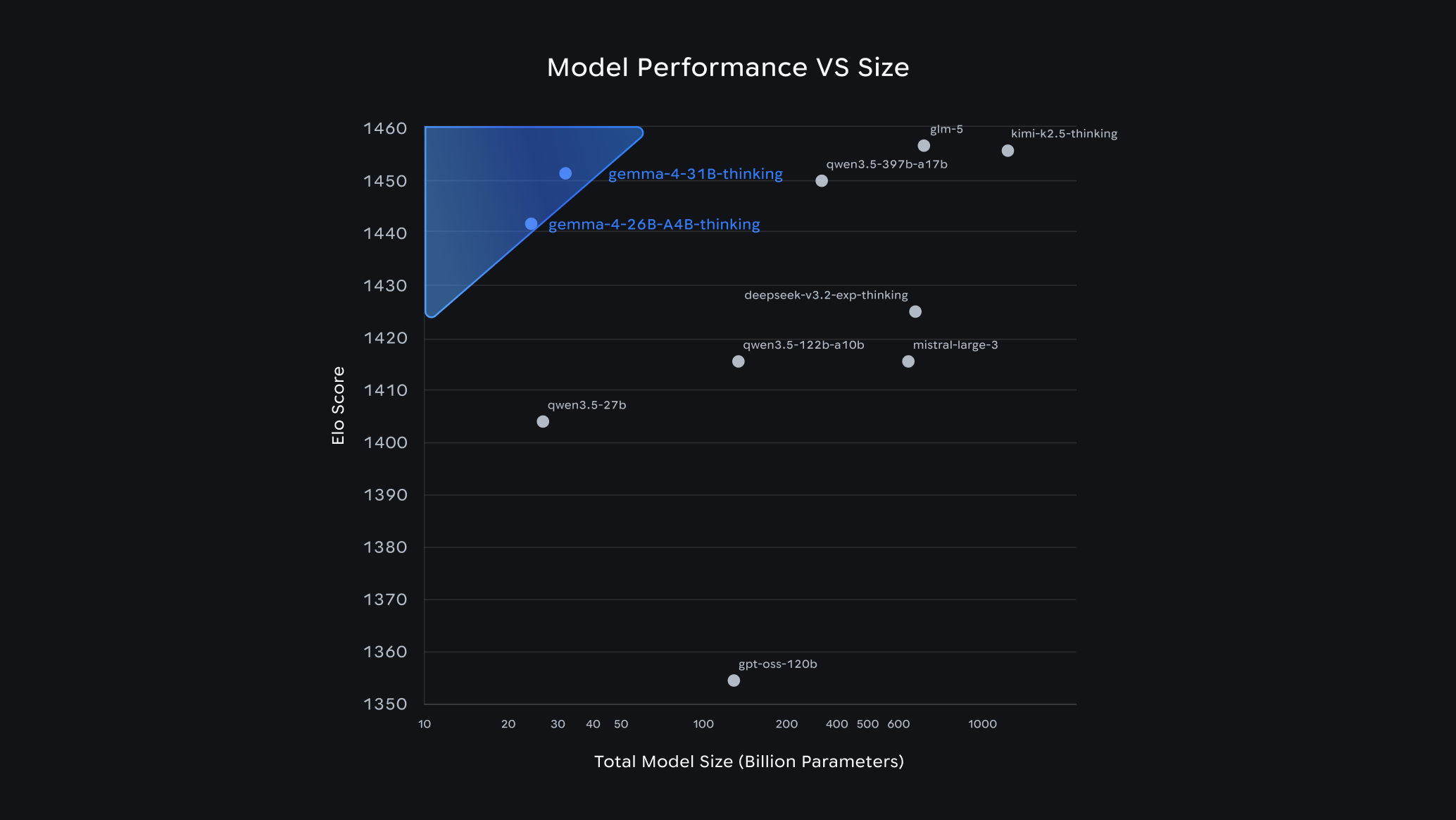
Gemini 3と同じ世界クラスの研究と技術をもとに構築されたGemma 4は、あなたのハードウェアで実行できる中で最も高性能なモデルファミリーです。私たちのGeminiモデルを補完し、開発者に対して、オープンとプロプライエタリ(独自)のツールの両方を兼ね備えた業界最強の組み合わせを提供します。
業界をリードする機能とモバイル・ファーストのAI
Gemma 4を、用途に応じて使い分けられる4つの多用途サイズで提供します:Effective 2B (E2B、Effective 4B (E4B)、26B Mixture of Experts (MoE)、そして31B Dense。このファミリー全体は、単なるチャットを超えて、複雑なロジックやエージェント型のワークフローを扱えるようになっています。より大きなモデルは、それぞれのサイズにおいて最先端の性能を提供します。現在31Bモデルは、業界標準のArena AIテキスト・リーダーボードで世界のオープンモデル中#3にランクインしており、26Bモデルは#6を確保しています。ここでは、Gemma 4が、自分のサイズの20倍に相当するモデルを上回っています。開発者にとって、この新しい「パラメータあたりの知能」水準により、大幅に少ないハードウェア負荷で、最前線レベルの能力を実現できます。
エッジでは、E2BおよびE4Bモデルが、オンデバイスの有用性を作り直し、生のパラメータ数よりも、マルチモーダル機能、低遅延の処理、そしてエコシステムへのシームレスな統合を優先します。
強力で、手に届く、オープン
次世代の先駆的な研究と製品を支えるために、私たちはGemma 4モデルを、実行とファインチューニングを効率よく行えるよう、特定のハードウェア向けにサイズ設計しました。世界中の数十億台のAndroidデバイスから、ノートPCのGPU、さらに開発者のワークステーションやアクセラレータまで、幅広い環境に対応します。
こうした高度に最適化されたモデルを使うことで、Gemma 4をあなたの特定のタスクに合わせてファインチューニングし、最先端の性能を実現できます。このアプローチで、私たちはすでに驚くべき成功を目にしてきました。たとえばINSAITは、先駆けとなるブルガリア発の言語モデル(BgGPT)を作りました。また、イェール大学と共に、Cell2Sentence-Scaleに取り組み、がん治療の新しい経路を発見する研究を行いました。もちろん、ほかにも多くの例があります。
ここが、Gemma 4が現時点で私たちの最も高性能なオープン・モデルファミリーである理由です:
- 高度な推論:マルチステップの計画と深いロジックが可能で、Gemma 4は、それを必要とする数学や指示追従のベンチマークで大幅な改善を示しています。
- エージェント型ワークフロー:関数呼び出し、構造化されたJSON出力、そしてネイティブのシステム指示に対するネイティブ対応によって、さまざまなツールやAPIとやり取りし、ワークフローを確実に実行できる自律エージェントを構築できます。
- コード生成:Gemma 4は高品質なオフラインコードをサポートし、あなたのワークステーションをローカル・ファーストのAIコードアシスタントに変えます。
- ビジョンと音声:すべてのモデルが動画と画像をネイティブに処理し、可変解像度をサポートします。OCRやチャート理解といった視覚タスクで優れた性能を発揮します。さらに、E2BおよびE4Bモデルには、音声認識と理解のためのネイティブな音声入力機能があります。
- より長いコンテキスト:長文コンテンツをシームレスに処理します。エッジモデルは128Kのコンテキストウィンドウを備え、大きなモデルは最大256Kを提供します。これにより、リポジトリや長いドキュメントを1つのプロンプトで渡せます。
- 140+言語:140以上の言語でネイティブに学習されており、Gemma 4は開発者がグローバルな視聴者に向けて、包括的で高性能なアプリケーションを構築するのを支援します。
多様なハードウェア向けの、汎用性の高いモデル
私たちは、特定のハードウェアとユースケースに合わせたサイズで、Gemma 4のモデル重みをリリースします。どこで必要としても、最前線クラスの推論を得られるようにするためです:
26Bおよび31Bモデル:個人のパソコン上でオフラインに動く最先端の知能
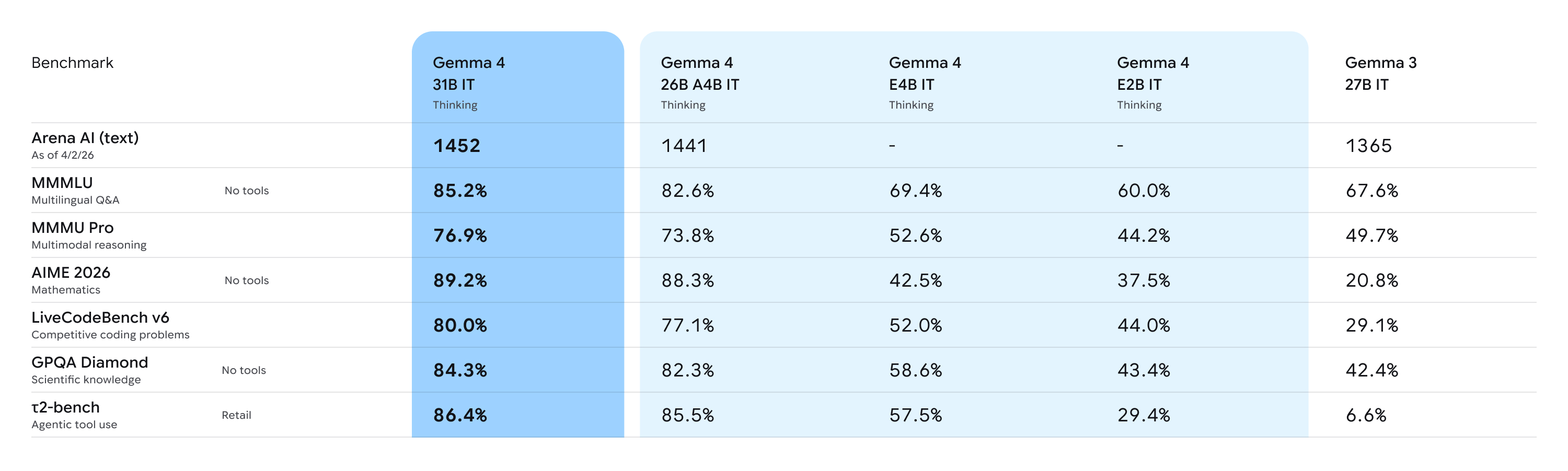
研究者や開発者に、手に届くハードウェアで最先端の推論を提供することを目的に最適化された、非量子化のbfloat16重みは、単一の80GB NVIDIA H100 GPUに効率よく収まります。ローカル環境では、量子化版がコンシューマーGPU上でネイティブに動作し、IDE、コードアシスタント、エージェント型ワークフローにパワーを与えます。26BのMixture of Experts(MoE)は遅延に重点を置き、推論時に総パラメータ数のうち3.8ビリオンのみを有効化することで、例外的に高速なトークン/秒を実現します。一方、31B Denseは、生の品質を最大化しており、ファインチューニングのための強力な土台を提供します。
これらのモデルは、テキスト生成のさまざまな側面をカバーするために、多数の異なるデータセットと指標に対して評価されました。追加のベンチマークは、私たちのモデルカードをご覧ください。
E2BおよびE4Bモデル:モバイルおよびIoTデバイスのための新たなレベルの知能
最大限の計算能力とメモリ効率のためにゼロから設計されたこれらのモデルは、推論時に有効な20億および40億パラメータのフットプリントを起動し、RAMとバッテリー寿命を保ちます。Google PixelチームおよびQualcomm TechnologiesやMediaTekのようなモバイルハードウェアのリーダーと緊密に連携し、これらのマルチモーダルモデルは、スマートフォン、Raspberry Pi、NVIDIA、Jetson Orin Nanoといったエッジデバイス上で、ほぼゼロのレイテンシで完全にオフライン動作します。Android開発者は、Gemini Nano 4とのフォワード互換性を見据えて、今日からAICore Developer Previewでエージェント的なフローの試作を行えるようになりました。
オープンソースのライセンス
フィードバックをいただき、私たちはそれに耳を傾けました。AIの未来を築くには協調的なアプローチが必要です。そして、制限のある障壁なしに開発者エコシステムの力を引き出すことが重要だと考えています。そこでGemma 4は、商用利用にも許容的なApache 2.0ライセンスのもとで公開されます。
このオープンソースのライセンスは、開発者の完全な柔軟性とデジタル主権のための土台を提供します。データ、インフラ、モデルを完全にコントロールできるようにすることで、自由に構築でき、オンプレミスでもクラウドでも、あらゆる環境で安全にデプロイできるようになります。
信頼と安全性の土台の上に構築
これらのモデルは、当社のプロプライエタリ(独自)モデルと同じ厳格なインフラストラクチャのセキュリティプロトコルを通過します。Gemma 4を選ぶことで、企業やソブリン組織は、最先端の能力を提供しながら、セキュリティと信頼性について最高水準の要件を満たす、信頼でき透明性のある土台を得られます。
選択肢に満ちたエコシステム
- 数秒で試し始める:Gemma 4にすぐにアクセスして、すぐに構築を開始できます。Google AI Studio(31Bおよび26B MoE)でGemma 4を探索するか、GoogleのAI Edge Gallery(E4BおよびE2B)で確認してください。Android開発では、Android Studio内のAgent Modeを駆動するためにそれを使用し、ML Kit GenAI Prompt APIを使ってAndroid向けの本番アプリの構築を開始できます。
- お気に入りのツールを使う:Hugging Face(Transformers、TRL、Transformers.js、Candle)、LiteRT-LM、vLLM、llama.cpp、MLX、Ollama、NVIDIA NIM、およびNeMo、LM Studio、Unsloth、SGLang、Cactus、Baseten、Docker、MaxText、Tunix、Kerasへのデイワン対応により、プロジェクトに最適なツールを選ぶ柔軟性があります。
- モデルをダウンロード:モデルの重みはHugging Face、Kaggle、またはOllamaから取得できます。
- Gemma 4を特定のニーズに合わせてカスタマイズ:Google Colab、Vertex AIなど、お好みのプラットフォームでモデルを学習・適応させることができ、さらにゲーム用GPUでも可能です。
- Google Cloudで本番規模にスケール:オンデバイスのローカル推論はオフライン利用に理想的ですが、Google Cloudは計算の上限をすべて取り除きます。Vertex AI、Cloud Run、GKE、ソブリン・クラウド、TPUによる加速の提供、そして規制対象のワークロードに対する最高水準のコンプライアンス保証など、さまざまな方法でデプロイできます。Google Cloudでの始め方についてはこちらをご覧ください。
- 複数のハードウェアプラットフォームにまたがるAI開発を加速:Gemma 4は、業界をリードするハードウェア向けにデフォルトで最適化されています。NVIDIA Jetson Orin NanoからBlackwell GPUまで、NVIDIAのAIインフラで最大限のパフォーマンスを体験し、オープンソースのROCm™スタックを通じてAMD GPUと統合するか、TrilliumおよびIronwoodのTPUにデプロイして、大規模かつ効率的に運用できます。
- インパクトを競い合う:世界における有意義で前向きな変化を生み出すプロダクトを作るために、KaggleのGemma 4 Good Challengeに参加してください。



