親愛なる皆さん、
反AI連合は、AIの進歩を遅らせるための議論を見つけようと、引き続き動き回っています。たとえば、AIがもたらす特定の影響について、真剣な懸念があるのであれば(人類の絶滅につながるかもしれない、など)、私はその立場に深く同意しないとしても、その知的誠実さを尊重します。しかし、私が心配しているのは、世論を調査して、ロビイストや、選挙区の有権者を不安に陥れようとする政治家によって、あるいは規制の囲い込み(regulatory capture)を狙う企業や自社技術の力を推し進めようとする企業によって、さらに、注目を集めるため、あるいは挑発的であることで利益を得るために、拡散されたときに人々をAIに反対させるどんなメッセージでも見つけようとする組織です。
イギリスのグループによる大規模な 研究 (AI Panic ブログへの敬意を込めて紹介)では、AIについて警鐘を鳴らすよう設計されたさまざまなメッセージを検証しました。その研究では、「AIが人類の絶滅を引き起こす」と言うことは、概ね失敗に終わったことが分かりました。破滅論者たちは数年前にこの主張を押し進めていましたが、幸いにも私たちのコミュニティはそれを押し返しました。しかし、AIを可能にする戦争や環境への懸念のほうが、よりよく響きます。私たちは、(すでに始まっている)こうした根拠をもとにAIに反対するメッセージの洪水が来ることに備えるべきです。さらに、失職や子どもへの害といったメッセージは、人々が行動するよう動機づけます。
誤解のないように言うと、私はAIを可能にする戦争に不安を感じています。AIの環境への影響を監視し、緩和するための真剣な取り組みは継続する必要があります。失職が起きることは悲劇であり、個人や家庭を傷つけます。そして、父親として私は、あらゆる子どもの福祉の重要性をとても大切にしています。これらそれぞれの話題は、最大限の注意を払って、真剣に向き合い、丁寧に扱うに値します。
しかし、反AIのプロパガンダを担う人々が、自分たちの組織の利益のために、複雑な問題を一面的に捉えて、広く世間一般の損失となるように利用するとき—たとえば、大手AI企業が、自社の提供と競合するオープンソースのプロジェクトを自由に配布することを妨げるために「AIは危険だ」と主張するとき—そのような場合には、結局私たち全員が負けます。
たとえば、データセンターの環境への影響に関する世間の見方は、すでに 現実 よりもはるかに悪いものになっています。つまり、データセンターは、それが行っている業務に対して非常に効率的であり、その増設を妨げることは環境に役立つどころか害になります。失職は確かに現実の問題ですが、「AIウォッシング」(レイオフを、パンデミック中に過剰に採用していた企業が、最近のレイオフについてAIのせいだと責任転嫁するようなもので、AIはいまだ彼らの業務に影響を与えていないのに)によって、AIが雇用に与える影響について過大な恐れが膨らんでいます。

残念ながら、この種のプロパガンダは、すぐに誰にとってもより悪い結果につながる規制を生み出してしまいます。たとえば、石油会社は長年かけて原子力エネルギーに対する恐怖を作り出してきました。その結果、原子力発電所の安全性に関する過度に誇張された懸念が、原子力発電の開発を押しつぶし、他のエネルギー源が引き起こした大気汚染による何百万人もの時期尚早の死亡や、CO2排出量の大幅な増加につながりました。AIに関する過度の懸念が、より速いAI開発から恩恵を受ける多くの人々に対して、同じような運命をもたらさないようにしましょう。
今週、ホワイトハウスはAIのための国家的な立法枠組みを提案しました。重要な構成要素の一つは、AI開発を妨げる各州ごとのバラバラな規制(パッチワーク)を防ぐための、連邦レベルの先占(preemption)枠組みです。私はこれを支持します。
連邦レベルで勢いを得られなかった後、多くの反AIのプロパガンダは州レベルへと移ってきました。50州のうちたった1つでも、AIを非生産的な形で制限する法律を通せば、他のすべての州でのAI開発が抑え込まれ、場合によっては世界全体にまで波及しうるのです。ホワイトハウスの提案は、各州が自らのゾーニングを統制する権利、消費者を守るための一般法をどのように執行するか、そしてAIをどう使うかについて、それぞれの権利を正しく尊重しています。しかし、もし州がAI開発を制限する法律を通すなら、連邦のルールが州法に優先して適用されます。
ホワイトハウスの提案は、現時点ではまだ提案の段階にとどまっています。しかし、アメリカ合衆国議会がそれを成立させれば、有益な形でAIを開発していくための継続的な取り組みに道が開かれるでしょう。
では、私たちはここからどこへ向かうのでしょうか?人々に害を及ぼす用途を制限することを支持しましょう。AIを使うものも、使わないものも、人々に害を及ぼすなら制限します。反AI連合がAIに反対するとき、私はその主張の良し悪しを検討するだけでなく、彼らの立場が筋が通っていて説得力があるのか、それとも、ある時点で世間を動かすと思う懸念を何でも宣伝しているだけなのかも考えます。そして、AIの恩恵と、起こりうる害を天秤にかける際は、科学的なアプローチを引き続き使いましょう。そうしないと、AIが皆にもたらし得る恩恵を制限するほど過大に誇張された懸念に行き着いてしまいます。
作り続けよう!
アンドリュー
DEEPLEARNING.AIからのメッセージ

「Agent Skills with Anthropic」は、ワークフローのロジックをプロンプトから切り離して、再利用可能なスキルに移すことで、エージェントをより信頼できるものにする方法を示します。コーディング、データ分析、リサーチ、その他のワークフローにわたって、スキルを設計し適用する方法を学びましょう。こちらから登録!
ニュース
オープンソース スピード・デーモン
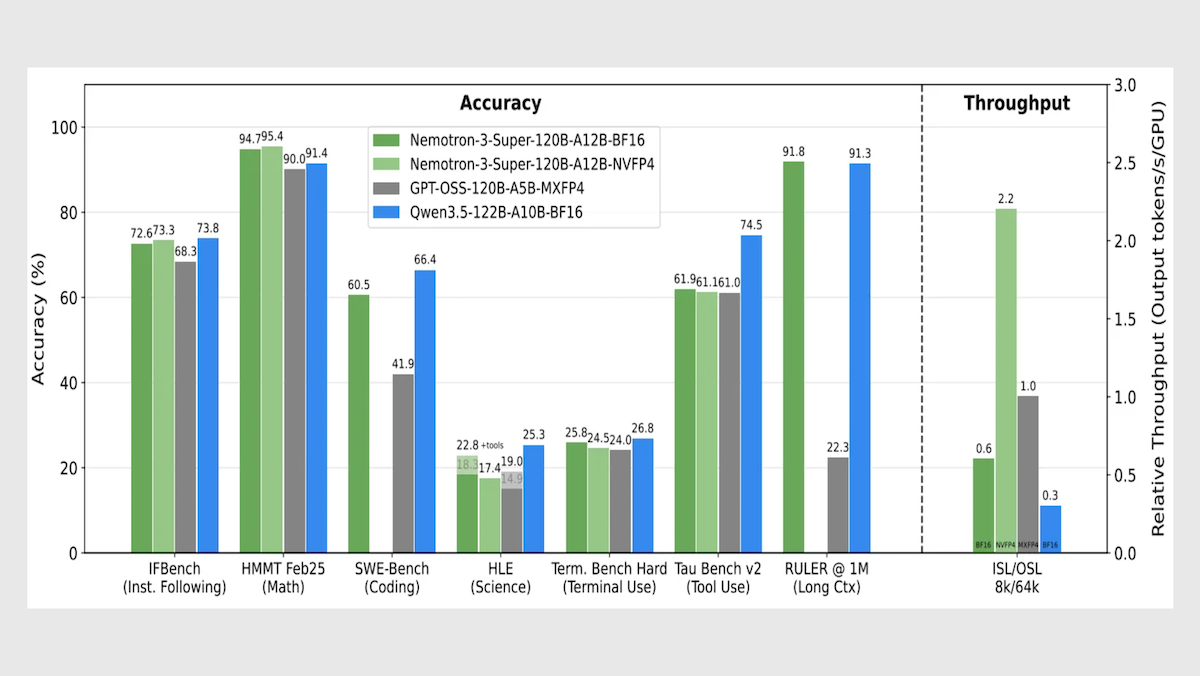
AIチップの主要サプライヤーであるNvidiaが、競争力のあるオープンソースの大規模言語モデルを公開しました。このモデルは、そのサイズ帯で処理速度がトップです。オープンウェイトのリーダーとしては、MetaがLlama 4を提供した昨年に続き、米国から登場した初の例になります。
新着情報: Nvidia が エージェント向けアプリケーションのために設計された大規模言語モデル「Nemotron 3 Super 120B-A12B」をリリースしました。これには、ウェイトだけでなく、学習データセットやレシピも含まれています。これは、計画されている3つのシリーズのうち2つ目です。Nvidia は 2025年12月に「Nemotron 3 Nano-39B-A3B」をリリースしており、「Nemotron 3 Ultra-500B-A50B」は近日登場予定です。
- 入出力: 入力(最大100万トークン)、出力(最大100万トークン)
- 知識のカットオフ: 2025年6月(事前学習データ)、2026年2月(微調整データ)
- アーキテクチャ: ハイブリッドのmamba-2/transformer/mixture-of-experts(MoE)で、多トークン予測レイヤーを採用(1200億パラメータ、トークンあたりアクティブは120億)
- 学習データ: 厳選されたデータ25兆トークン。ウェブからスクレイピングし、20の自然言語と43のプログラミング言語で合成
- 機能: ツール呼び出し、構造化された出力、7言語(中国語、英語、フランス語、ドイツ語、イタリア語、日本語、スペイン語)、推論モード(オフ、低、通常)
- 性能: 同サイズ帯で最速のオープンウェイトモデル(1秒あたり442出力トークン)。エージェント向けタスクのPinchBenchテストで、オープンウェイトモデルのトップをリード
- 利用可能性/価格: ウェイトとデータセットは こちらからダウンロード 可能。非営利および営利の用途を許可するライセンスの下で提供(安全性ガードレールが置き換えなしで削除された場合、またはユーザーがNvidiaに対して特許・著作権の訴訟を起こした場合は権利が終了)。さらに、 Nvidia およびOpenRouter経由で無料チャット可能。APIは、第三者プロバイダー経由で入力/出力それぞれ1百万トークンあたり約$0.30/$0.80
仕組み: Nemotron 3 Superのハイブリッドアーキテクチャは、mamba-2、注意(attention)、改良されたMoE層を、前向き計算のたびに一定数のトークンを生成する多トークン予測ヘッドとともにインターリーブします。
- Nemotron 3 Superの層の大部分は mamba-2 層です。入力長が長くなるにつれて二次的に計算電力を消費する注意層とは異なり、mamba-2層は各ステップで、先行コンテキストをコンパクトな表現に圧縮します。Nemotron 3 Superは、入力の遠い部分からの正確な取得が必要となるタスクを処理するために、attention層を選択的にインターリーブします。mamba-2層では苦手な領域です。
- MoE層はNvidiaの LatentMoE 設計を使用し、MoEルーターがどのエキスパートを有効化するかを決める前に、各トークンの表現を通常の1/4のサイズに圧縮します。この圧縮により、モデルは、通常で必要とされる5〜6のエキスパートとほぼ同量の計算電力で、トークンあたり22のエキスパートを有効化して動作できます。
- 多トークン予測(MTP)ヘッドは、前向き計算の1回あたりに複数の出力トークンを予測します。学習中は、モデルがより長距離のパターンを学習することを促します。推論中は、MTPヘッドが下書きのトークンを生成し、モデルが1回のパスでそれらを検証することで、出力を高速化します。確率分布と整合するものを保持し、それ以外を破棄します。
- チームは、Nvidia Blackwell GPUアーキテクチャに組み込まれている4-bit浮動小数点数値フォーマットであるNVFP4で事前学習しました。そのため、学習後に量子化するのではなく、低い精度で動作することを学習できています。
- チームは、プロンプト、推論、ツール呼び出し、最終出力から構成されるプロンプトからなる、700万以上のシーケンスでモデルを微調整しました。これらのシーケンスは、一部のタスク(数学、コード、多言語クエリなど)についてはDeepSeek V3.2とKimi K2によって生成され、ソフトウェアエンジニアリングのタスクについてはQwen3-Coder-480Bによって生成されました。その後、強化学習を3段階で行いました。すなわち、数学、コーディング、科学、パズル、そしてエージェント的なツール利用といった領域で、客観的に検証可能な出力を伴うタスク。さらに、モデルがテスト実行を報酬シグナルとして用い、GitHubの課題を解決することに特化したソフトウェアエンジニアリング段階。そして会話品質を向上させるための、人間のフィードバックに基づく強化学習です。チームは、そのPivotRLの微調整アプローチを 論文で説明しています。
パフォーマンス: Nemotron 3 Superは、速度と長いコンテキスト処理において自社のクラス上位に位置し、全体的な知能やエージェント的タスクにおいても競争力のある指標を示しています。
- Nemotron 3 Superは推論(レベルは不明)を設定しており、生成 では毎秒約442トークンを実現しており、高い推論に設定されたOpenAI gpt-oss-120b(毎秒278トークン)や、推論に設定されたGoogle Gemini 3.1 Flash-Lite(毎秒266トークン)を大きく上回っています。
- Artificial AnalysisのIntelligence Index(経済的に有用な仕事に焦点を当てた10のベンチマークの加重平均)では、Nemotron 3 Superは推論(36)でQwen3.5-122Bの推論(42)にわずかに及ばなかったものの、高い推論のgpt-oss-120b(33)を上回りました。
- RULER(Nvidiaが開発した長コンテキスト評価)で、入力100万トークンを与えた場合、Nemotron 3 Super(正解率91.75%)はQwen3.5-122B(正解率91.33%)をわずかに上回り、gpt-oss-120b(正解率22.30% a)を大きく引き離しました。
- PinchBench(モデルが、自律エージェントの意思決定の中核として、タスクをどれだけうまく完了できるかを評価する。OpenClaw)では、Nemotron 3 Super(85.6%)が、1兆パラメータのKimi K2.5(84.8%)や7440億パラメータのGLM-5(84.1%)など、はるかに大きいオープンウェイト陣営を上回り、さらに同程度のサイズのQwen3.5-122B(84.5%)も上回りました。
裏のニュース: Nvidiaは、5年間で260億ドルを投資してオープンウェイトモデルを開発する計画です。これは相当大きなコミットです。この発表は、Nvidiaの事業に影響し得るオープンウェイトの勢力図の変化と時期を同じくしています。最近、Alibaba、Moonshot AI、Z.aiなどの中国企業が、最も能力の高いオープンウェイトモデルを構築してきており、NvidiaのGPUやCudaソフトウェアの代替となるものを作り上げています。たとえばDeepSeekは、今後登場するモデルを、HuaweiのAscendチップとCannソフトウェアだけで完全に学習したと報じられています。
重要な理由: Nemotron 3 Superは、エージェント的アプリケーション向けに、学習データ、レシピ、そしてツールを重みとセットで提供する、高速で完全にオープンなモデルを開発者に提供します。このオープン性は、Nvidiaの事業目標にも役立ちます。中国のオープンウェイトモデルは、より能力が高くなっているだけでなく、Nvidia以外のチップでも動かせるように、ますます合理化されています。その結果、これまでNvidiaに依存してきた開発者が他へ目を向けるリスクが生じます。Nemotronは、彼らにそうさせない理由を与えます。
考えていること: GPU向けにモデルを最適化するのに、GPUを設計している会社ほど適任なのは誰でしょうか? カスタムの数値フォーマットから推論ソフトウェアまで、Nvidiaは他の多くのモデル開発者ができない形で、ハードウェアとソフトウェアを共同設計できるはずです。Nvidiaは、「モデルを作ることがチップを売るのに役立ち、そしてその逆も成り立つ」と賭けています。

OpenAI、AWS上でエージェントの状態を追跡
OpenAIはAmazonと提携し、世界最大のクラウド基盤上でエージェント向けのインフラを構築しました。これは、Microsoftとの密接な関係が弱まっていることを示す、さらにもう一つのサインです。
新たな動き: OpenAIとAmazonは、「状態(state)を保持するランタイム環境」を発表しました。これは、AIエージェント向けにこれから提供される計算インフラです。両社は、見込まれるリリース時期を明らかにしていません。この提携により、OpenAIのクラウド計算リソースはMicrosoft Azure以外にも広がり、Amazonは自社の製品でOpenAIモデルを利用できるようになります。この取引の一環としてAmazonは 投資 としてOpenAIに150億ドルを拠出し、さらに非公開の特定条件が満たされる場合、またはOpenAIが2029年より前に株式を一般公開する形で提供する場合は追加で350億ドルを拠出する予定です。これはGeekWireによる関連書類の 分析 に基づく報道です。さらに、クラウド提携が終了すれば、Amazonの残り350億ドルのコミットメントも同様に消滅します。今回の投資は、NvidiaやSoftbankも含む巨大な1100億ドル規模の資金調達ラウンドの一部であり、OpenAIの企業価値は7300億ドルと評価されました。(開示: Andrew NgはAmazonの取締役会メンバーです。)
- OpenAIとAmazon Web Services(AWS)は、Amazon Bedrock上で動作する「状態(state)を保持するランタイム環境」を開発します。Bedrockは、AmazonのAIアプリケーションを構築・デプロイするためのプラットフォームです。数か月以内の開始が見込まれ、この環境は、記憶、ツール接続、ユーザー権限など、エージェントの稼働状態を管理するために設計されています。
- AWSは、OpenAIの Frontier(企業内でAIエージェントを構築、デプロイ、管理するためのプラットフォーム)の独占的な第三者クラウドプロバイダーになります。Amazon経由でFrontierを購入する顧客にはAmazon Bedrockを通じて提供され、一方でOpenAIから直接購入する顧客にはMicrosoft Azureを通じて提供されます。
- OpenAIとAmazonは、Amazonの製品向けにカスタムモデルを開発します。
- OpenAIは、AmazonがAIワークロード向けに設計したTrainiumチップの使用にコミットしました)。OpenAIは、Tranium処理として2ギガワット相当を消費することを約束し、AWSとの これまでの 380億ドル規模の契約を、8年間でさらに1000億ドルに拡大しました。
仕組み: 多くの開発者は、各リクエストが独立しているステートレスAPIを通じてAIモデルとやり取りします。開発者がプロンプトを送ると応答が返ってきますが、モデルはそのやり取りを記憶しないため、開発者は毎回のリクエストにすべての文脈(コンテキスト)を渡す必要があります。ステートフルな実行環境は、その文脈を処理できることを目的としており、どこで処理しているかを見失うことなく、エージェントが長く複数ステップにわたるワークフローを実行できるようにします。さらに、顧客は、AWS上で動作するopen-weightsのOpenAIモデルをカスタマイズしたバージョンにアクセスできるようになります。The Informationが報じたとおりです。
- OpenAI は 、生産環境でのAIエージェントにはステートレスAPIだけでは不十分だと主張しています。生産環境のAIエージェントは、複数のツールからの出力に依存し、人間の承認が必要で、途中で中断された場合には中断時点から再開しなければならないためです。
- ステートフルとステートレスの違い――APIに典型的に見られる属性でもあります――は、法的な目的も果たします。OpenAIとMicrosoftの契約により、AzureはOpenAIのステートレスAPIの独占ホストになりますが、実行環境はMicrosoftの権利の範囲外です。Azureは、Amazonとの連携から生じるOpenAIモデルへのステートレスAPI呼び出しを ホスト することになります。
- この環境は、AmazonのAIエージェントをデプロイおよび管理するためのツールであるAmazon Bedrock AgentCoreと統合され、AWSを用いる顧客の既存環境上で動作します。
今回のニュースの背景: OpenAIとAmazonの提携は、初期の生成AI時代を特徴づけた、密接なクラウド提携がほどけていく流れの中での最新の一歩を示しています。2019年にMicrosoft が 10億ドル(その後は130億ドル超まで増額)をOpenAIに投資し、同社の独占的なクラウド提供者になりました。2023年にはAmazon が 最大40億ドルをAnthropicに投資し、主要なクラウド提供者になりました。いずれの案件も、AIスタートアップとクラウドの巨人を組み合わせるものでした。その両方の結びつきは、その後弱まっています。
- 2024年後半までに、MicrosoftとOpenAIはいずれも、OpenAIの需要がMicrosoftが構築する意欲のある計算資源を上回ったこと、そしてMicrosoftが自社のAI能力開発により注力したことを背景に、両者の 相互依存を減らそうと取り組んでいました。
- 2025年10月、OpenAI が 営利の公開ベネフィット法人として自らを再編した際、その条件はMicrosoftに27%の持分とOpenAIの収益の20%を与えましたが、クラウド事業に関する最優先の拒否権を取り除きました。その結果、OpenAIは他の提供事業者と協業できるようになりました。
- Amazonの案件が発表された当日、MicrosoftとOpenAI は 、提携は継続しているとする共同声明を出しました。Microsoftは、モデルの重みなどOpenAIの知的財産への独占的なアクセス権を維持し、またOpenAIが他のクラウド提供事業者と結ぶ提携からの収益分配を引き続き受け取ることになります。
- Amazon側でも、これとよく似た構図が繰り広げられました。Amazonの主要AIパートナーであるAnthropicは、Amazonが出資する以前からGoogle Cloudにいましたが、その後、Microsoftにも拡大しました。2025年11月、Microsoft が Anthropicに最大50億ドルを投資し、ClaudeモデルをAzureで利用可能にしました。これにより、Claudeは3大クラウドプラットフォームすべてで利用できる最初の主要なモデルファミリーになりました。
- 米国証券取引委員会(SEC)に提出された書類 が GeekWireによってレビューされたところによると、Amazonの株式投資とクラウド提携は契約上リンクしています。契約が終了すれば、Amazonが残り350億ドルとしてコミットしている分も、その契約とともに消滅します。
重要な理由: AIエージェントを構築する開発者は通常、ステートレスAPIの上に、自分たちでステート管理、ツールのオーケストレーション、フォールトリカバリを構築します。これらの機能をインフラとして扱うように設計された実行環境があれば、AIエージェントの導入におけるハードルを下げられる可能性があります。裏返せば、どのようなステートを保存するのか、そしてそれがどれほど移植可能なのかによっては、別のクラウドベンダーへの切り替えコストが増えるかもしれません。市場シェア最大のクラウド提供者であるAWS上で動作することになれば、開発者コミュニティの幅広い層に提供されることになります。
筆者の見立て: ステートレスとステートフルの区別は、巧妙な法務上の設計かもしれませんが、同時に現実の技術的な転換を反映しています。AIアプリケーションが自律性へと向かうにつれて、エージェントの背後にあるインフラは、モデルと同じくらい重要になる可能性があります。

xAIの低コストな動画生成器
xAIは動画生成器を立ち上げ、競合の価格の一部で独立した品質ランキングの首位に到達しました。
新たに: Grok Imagine 1.0 は、画像や/または動画を伴うテキストを受け取り、その情報から、会話、効果音、音楽を含めることができる動画クリップを生成します。
- 入出力: 入力: テキスト、画像(任意)、動画(任意)。出力: 音声付きの動画(チャットインターフェース経由で最大10秒、1,280x720ピクセル。API経由で最大15秒、1,280x720ピクセルまたは854x480ピクセル)
- パフォーマンス: ローンチ時にテキストから動画、画像から動画の両方でArtificial Analysis Video Arenaの首位を獲得
- 機能: テキスト指示による動画の編集。カメラモーション(パン、チルト、ズーム)。シーン内の物体の追加・削除・入れ替え。スタイル転送。複数のアスペクト比
- 提供/価格: ウェブインターフェース(grok.com、x.com、Grokモバイルアプリ)。X BasicおよびPremiumユーザー向けは無料(Premiumユーザーはより長い動画を生成可能)。 API $4.20/分(出力)
- 非公開: xAIは、Grok Imagine 1.0の基盤技術およびどのように構築されたかについて、情報を開示していません。
パフォーマンス: Grok Imagine 1.0はローンチ時に、 Artificial Analysis Video Arenaで首位デビューを果たしました。これは、人間の視聴者が判断する嗜好についてのブラインドな一騎打ちテストです。いくつかの競合より遅いものの、概して費用は低めです。(開示: Andrew NgはArtificial Analysisに個人的に投資しています。)
- ローンチ時、Artificial Analysisのリーダーボードでは ランク付け で、Grok Imagine 1.0がテキストから動画部門と画像から動画部門の両方で1位となり、Runway Gen-4.5、Kling 2.5 Turbo、Google Veo 3.1を上回りました。
- LM Arenaの 動画リーダーボードでは、grok-imagine-video-720pが画像から動画で1位(1,400 Elo)で、Google Veo 3.1(1,395 Elo)に先行し、テキストから動画では 4位 (1,362 Elo)となりました。Google Veo 3.1(1,371 Elo)とOpenAI Sora 2 Pro(1,369 Elo)の後ろです。
- xAIが IVEBench (指示に導かれた動画の改変の品質を評価する)を用いて行った一騎打ちテストでは、ヒューマン評価者はRunway Aleph(64.1%の割合)およびKling O1(57%の割合)よりもGrok Imagine 1.0を好みました。
- Artificial Analysis によれば、平均するとGrok Imagine 1.0は(再生時間は不明ながら)110.1秒で動画を生成しました。これはKling 2.5 Turbo(89.2秒)やVidu Q2(39.1秒)より遅い一方、OpenAI Sora 2 Pro(448.4秒)やMiniMax Hailuo 2.3(167.1秒)より速いです。
- 生成された動画1分あたりの価格(音声込み)が$4.20のGrok Imagine 1.0は、Kling 2.5 Turbo(音声なし)と同等の価格で、Google Veo 3.1 Preview(音声込みで1分あたり$12)やOpenAI Sora 2 Pro(音声込みで1分あたり$30)より安くなっています。
速報の背景: Google、OpenAI、Runwayの動画生成器が単体の製品や/またはAPIとして提供されているのとは異なり、Grok Imagine 1.0は X ソーシャルネットワークに統合されています。これにより、XユーザーはX上で直接動画を生成し、共有できます。そこでは、ユーザーが 物議 を引き起こしていました。2025年後半、XユーザーはGrokを悪用して、実在の人物(子どもを含む)に対する同意のない性的に露骨な画像を作り出し、いくつかの国で調査や禁止措置につながりました。xAIが対処すると約束した後も、この現象は続いたとロイターが 報じました。
なぜ重要か: 自分のイメージに合う動画を生成するには、通常、プロンプトを調整して何度も反復し、再生成して、結果を比較する必要があります。xAI は 、初期のパートナーから、遅延(レイテンシ)やコストのせいで反復が現実的でない状況では、品質だけでは役に立たないと同社が言われたとしています。サードパーティのベンチマークでは、Grok Imagine 1.0が、品質面でプレミアム競合の主要モデルに匹敵、あるいは上回りつつ、より低コストであることが示されています。この組み合わせは、試行錯誤のコストを下げます。
考えていること: 画像生成は、およそ2年で新奇性から“最低限必要な基盤”へ移行しました。動画生成も同様の道をたどっています。Grok Imagine 1.0と、現在は提供終了となったOpenAI Sora 2 Proの間にある7倍の価格差は、価格にはまだ大きく下がる余地があることを示唆しています。
文脈を外部変数として扱う
長い文脈を処理する際、大規模言語モデルはしばしば細部を見失ったり、ナンセンスに陥ったりします。研究者たちは、文脈を外部で管理することで、これらの影響を抑えました。
新しい動き:MITのAlex L. Zhang、Tim Kraska、Omar Khattabは Recursive Language Models (RLMs)を開発しました。これらは、書籍、ウェブ検索、コードベースなどの長いプロンプトに出会ったとき、プロンプトを外部の環境に切り出してプログラム的に管理することで処理します。
重要な洞察:外部のプログラミング環境において入力テキストを持続的な変数として扱うことで、言語モデルは文脈ウィンドウより大きい入力を含む長い入力を処理できます。モデルは、必要なテキストのチャンクだけを取得するためのコードを書くことができます。たとえば、キーワードを探して、それらの周囲の段落を取得できます。反復的にコードを書くことで、長い文脈タスクを、全体として取り組む前にサブタスクへ分解できるのです。
仕組み:RLMは、単純なリード・イバリュエート・プリントループ(REPL)環境でPythonコード実行を用い、タスク(ユーザーのプロンプトと関連ドキュメント)を読み取り、操作します。扱うタスクは、長いドキュメントから詳細を分析したり理解したり、または取得したりすることです。モデルは、新しい自身のインスタンス、あるいはサブモデルを呼び出して各サブタスクを処理し、それぞれのインスタンスの出力をルートモデルに返すプログラムを生成しました。
- 著者らは、Qwen3-8B(32,768トークンのコンテキストウィンドウを持つ)、GPT-5(400,000トークンのコンテキストウィンドウ)、Qwen3-Coder-480B(256,000トークンのコンテキストウィンドウ)に基づいてRLMシステムを構築しました。各システムは、モデルと、Python環境に対して読み書きを行い、サブモデルを呼び出すカスタムのエージェント型フレームワークで構成されていました。
- RLMシステムは、タスクデータをモデルへ直接投入するのではなく、変数 rather than feeding it directly into the model.(モデルに直接与えるのではなく)としてPythonインタプリタに読み込みました。
- システムプロンプトは、ルートモデルに対し、REPL環境と格納されたタスクとやり取りするためのPythonコードを生成するよう指示しました。たとえば、モデルはプロンプトの長さを調べ、キーワードを見つけ、論理的なチャンク(章やセクションのようなもの)に分割し、それぞれのチャンクについて質問に答えるために別のサブモデルを呼び出します。
- 各サブモデルは、ルートモデルの指示や質問に従って自分のチャンクを処理し、その結果をルートモデルに渡します。
- システムはサブモデルの出力 を変数として保存しました。ルートモデルは、この中間結果を用いて最終出力を構築します。
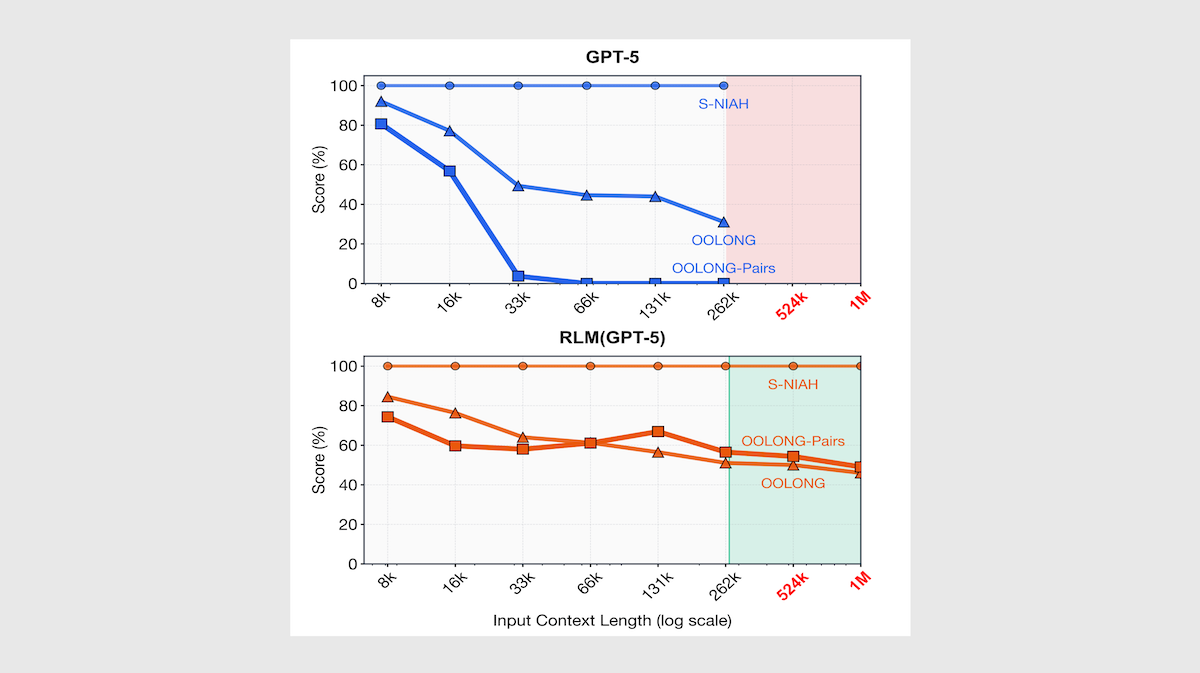
結果:著者らは、Qwen3-8B、推論が中程度のGPT-5、Qwen3-Coder-480Bに基づくRLMを、1,000,000トークンまでの長さのドキュメントに対して検索と推論を行うベンチマークを用いて、元のモデルと比較しました。また、RLMを、検索ツールを備えたCodeActエージェントや、コンテキストを圧縮または要約するカスタムエージェントとも比較しました。RLMは、複数ドキュメントの理解を要するタスク(合計最大11,000,000トークンまで)において、既成の モデル とその他のエージェント型戦略の両方を大きく上回りました。
- BrowseComp+では、複数ドキュメントにまたがる推論を必要とする質問応答ベンチマークにおいて、RLM-GPT-5(91.3%の精度)がGPT-5(コンテキスト長の制限にぶつかり、回答を生成できない)を上回りました。さらに、GPT-5を用いた要約エージェント(70.5%の精度)も上回りました。同様に、RLM-Qwen3-Coder-480B(44.7%の精度)は、要約エージェントを使ったQwen3-Coder-480B(38.0%の精度)を上回りました。RLM-Qwen3-8B(14%の精度)も、Qwen3-8B(0%の精度)を上回りました。
- 著者らは、モデルを OOLONG-PAIRS( OOLONG の長文脈推論ベンチマークのバージョン)でテストしました。OOLONG-PAIRSでは、ペアになったチャンクを集約して最終出力を構築する必要があります(たとえば、「ユーザーIDの全てのペア[… ]で、両方のユーザーが少なくとも[a値または場所]を持つものを挙げよ」など)。RLM-GPT-5(58%の精度)は、GPT-5(ほぼ0%の精度)と検索・要約エージェント(約0.3%の精度)を、32,000トークンのコンテキストにおいて上回りました。RLM-GPT-5は、1,000,000トークンのコンテキストでもおよそ50%の精度を維持しました。RLM-Qwen3-8B(5.2%の精度)は、32,000トークンの コンテキストにおいてQwen3-8B(0%の精度)を上回りました。
なぜ重要か:従来のアプローチはしばしば、検索や要約によって長い文脈を扱いますが、それによって重要な細部が失われることがあります。タスクを再帰的なサブ呼び出しに分解することで、モデルはより多くのトークンにわたって高い精度を維持できます。この方法は、モデルの 入力制限をはるかに超える数のトークンに対しても、首尾一貫した推論ができるエージェントを構築するための設計図を提供します。
考えていること: RLMは、ある時点で必要な文脈の部分だけに注意を払います。このアプローチは、人が 長いドキュメント を1セクションずつ処理するという人間のやり方に似ているように思われます。




