[ニューラルネットワーク] 今こそ起源を見つめる時 Ep.5 (最終話) 〜情熱の連鎖が明日を照らす〜

生成AIを形作る「ニューラルネットワーク」という技術がいかにして誕生したのかを紐解くシリーズの第5話です。
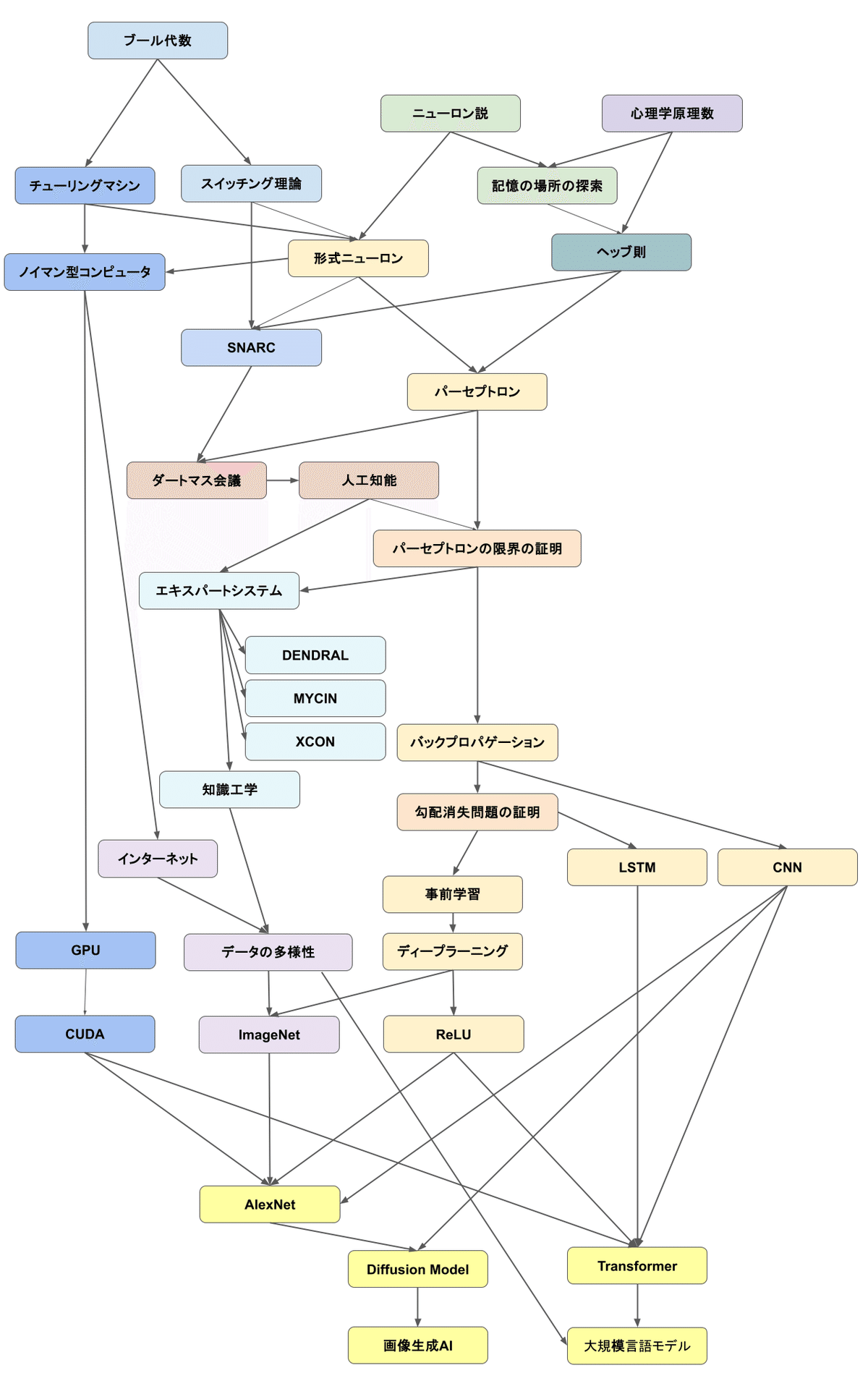
前回は、知能をプログラムすることに過熱した第2次AIブームと、その限界により金食い虫のレッテルを貼られたAIの冬の時代を見つめました。しかし、世間の関心が薄れたその影で、ニューラルネットワークの技術の根は着実に成長を遂げていたのです。
一度は否定されたニューラルネットワークの数学的破綻に、生きる道を与えたジェフリー・ヒントン博士によるバックプロパゲーションの研究。AIに視覚を与えたヤン・ルカン博士による畳み込みニューラルネットワーク(CNN)の研究。そしてAIの記憶管理に革新を生むユルゲン・シュミットフーバー教授らによるLSTMの研究。これらの研究が、現代AIの地盤をしっかりと固めていたのです。
そして2006年。再びジェフリー・ヒントン博士が放つ1通の論文により、世界が動き出します。
さて、物語の続きを見ていきましょう。
理論は出来た、しかしまだ残る課題
ニューラルネットワークを何層にも重ねた多層ニューラルネットワーク。それは、複雑な現実を読み解かせるためには必要不可欠でした。
第4話で触れた通り、バックプロパゲーションの計算式は、理論上、多層ニューラルネットワークの学習を可能にしました。具体的には、いわゆるバケツリレー方式の学習を行います。
高層ビルをイメージしてください。屋上では、あるイベントが開催されています。このビルの1階から屋上までお客さんが移動して、屋上にたどり着いた時に初めてどんなイベントなのかがわかります。
各階にはスタッフが立っています。そして、屋上までたどり着いたお客さんが見た結果を、各階のスタッフが伝言ゲームで1階まで伝えます。
これにより、全ての階のスタッフは適切なアナウンスができるようになります。これが、バケツリレーの学習です。
しかし、高層ビルの階数が大きくなればなるほど、伝言ゲームは難しくなります。上の階層から下へと降りるにつれて、もとの声が薄れていき、下の階層まで届かなくなったり、どこかで見当違いな伝言をしてしまい、全く別の声が下層に届いてしまったりするのです。

これを、実際のAIの専門的用語に対応づけると、高層ビルが多層ニューラルネットワークを示します。各層のスタッフはニューロンの重み、そして、お客さんは入力されるデータです。1階から屋上へのお客さんの移動はフォワードプロパゲーション(順伝搬)と呼び、入力データが各層(階層)を通り抜け、最終的な予測を出力するプロセスです。屋上のお客さんのリアクションが実際の正解と予測のズレ(誤差)に相当します。このときの、リアクションを各階のスタッフが上から下へ伝言ゲームするのが、バックプロパゲーション(誤差逆伝搬法)です。屋上でわかったズレを、「どう修正すればいいか」という指示(勾配)として下の階層へ順番に伝えていく学習プロセスです。この伝言ゲームで声が薄れてしまう現象は「勾配消失」と呼ばれます。
第4話でも説明したこの勾配消失問題を再度見つめると、バックプロパゲーションでは「連鎖律(チェインルール)」という仕組みを使い、各階層を降りるたびに数字のかけ算を繰り返します。
昔のAI(シグモイド関数などを使用)では、このかけ算の係数が必ず小さい値(例:0.25など)になっていました。
たとえ1回あたりは少しの減衰でも、高層ビルになればなるほど致命的です。例えば、1階降りるごとに声の大きさが $${0.9}$$ 倍になるとします。これが100階建て(100層)のビルだとどうなるでしょうか。
$${0.9^{100} \approx 0.000026}$$
1階にいるスタッフ(入力層に近いネットワーク)には、元の声の 「0.0026%」 しか届きません。これでは「1階のスタッフは何をどう改善すればいいか全くわからない(学習が進まない)」という状態に陥ってしまいます。逆に、係数が1より大きいと、声が爆音になりすぎてエラーを起こすのが「勾配爆発(見当違いな伝言)」です。
この勾配消失と勾配爆発の課題は多層ニューラルネットワークにとって、最大の問題でした。
層を増やせば賢くなる。計算方法もある。しかし、上手くいかないというもどかしさが残ったのです。
そして、2006年、再びヒントン博士は新たな概念を生み出します。
これが、このもどかしさを晴らすことになるのです。
いきなり屋上を目指さない、各階での自主練
これまでのやり方は、1階から屋上まで一気に人を歩かせ、そのフィードバックを一気に下までの全階層の認識を修正させるという、ビルのスタッフ全員を一気に学ばせるスタイルでした。
ここで、ヒントン博士は発想の転換をしたのです。
「上からの指示が届かないなら、まずは各階のスタッフが、自分の階の役割を整理する練習(事前学習)を済ませておけばいいのではないか?」
そして、2006年、ヒントン博士は『A fast learning algorithm for deep belief nets』という論文を世に放ちました。
【論文情報】
https://www.cs.toronto.edu/~hinton/absps/fastnc.pdf
Hinton, Geoffrey E., Simon Osindero, and Yee-Whye Teh. "A fast learning algorithm for deep belief nets." Neural computation 18.7 (2006): 1527-1554.
事前学習という概念の誕生
ヒントン博士が提案したのはゼロから全体を学習させるのではなく、2つのステップに分けて学習すれば、学習を安定させられるというものでした。
ステップ1では各階の自主練(事前学習)を行います。
まず、練習用のお客さんを1階から2階に移動してもらい、2階から1階へ声を届ける練習を繰り返します。これによってスタッフ達は情報の扱い方を屋上からのフィードバック無しに自主練するのです。これを2階、3階……と順番に、1層ずつ積み上げていきます。つまり、階を1つずつ増やして、特に屋上の声が届きにくい下の階のスタッフの経験を事前に積ませておくのです。
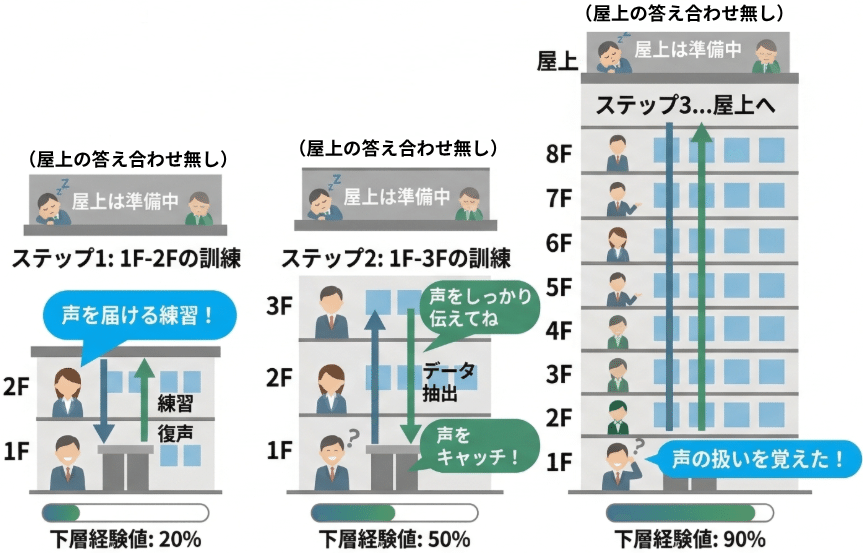
これは、ヒントン博士の正式な言葉で言うと、層ごとの事前学習(Layer-wise Pre-training)と呼びます。
この作業を繰り返す学習は、屋上のフィードバック(つまり正解との誤差)を使わないため、非教師あり学習(自己学習)と呼びます。ちなみに、正解と比較して学習する方式は教師あり学習と呼びます。
通常、学習と言えば答え合わせをすることで何が正しかったのかを知って考えを修正していく作業だと思いますよね。
しかし、ヒントン博士はその発想を脱ぎ捨て、正解を教えなくても自主練させるための仕組みを作ったのです。
その名も、Deep Belief Nets(DBN)という仕組みです。
これは、入力されたデータの特徴を捉える作業、そして、捉えた特徴から再び入力データを再現するという、抽出と復元のネットワークです。
入力データ→「抽出」→ 特徴データ →「復元」→ 再現データ
単に、抽出と復元を行うだけのネットワークですが、元のデータを再現する力を学ぶことができるため、取り扱うデータの本質的な特徴(形や模様のルール)を理解させることが出来ます。
似顔絵師をイメージしてください。まず、じっくり相手を見て、「垂れ目で口が小さい」など特徴を読み取ります。これが「抽出」の作業です。その後、その特徴のイメージを元に絵で顔を再現していくという「復元」の作業です。
似顔絵師はこれをたくさん繰り返すことで、自動的に顔の特徴を捉えるのが上手になります。これこそ自主練の学習なのです。
例えば、大量の『猫』の画像をDBNに入力すると、この自主練の学習を通して、勝手にDBNは猫の顔がもつ本質的な特徴を捉えるのが得意になるのです。
この自主練の学習は、取り扱うデータさえあれば、答え合わせのフェーズがなくてもその特徴を学べます。
この発想は、ニューラルネットワークの学習にとって革命的なできごとでした。
正解から学ぶ教師あり学習は、データの全てに答え合わせ表が必要です。この正解を作る作業は基本的に人力で行う必要があります。1000個の問題集であれば、なんとかなりますが、1億の問題集を人手で作るのはコスト的にも時間的にも大変ですよね。そんな中、答え合わせ表は不要で、ただ入力されるデータだけあれば良いとなったらどうでしょうか。データは世の中に沢山あるので、それを流し込めばよくなり、大量のデータで学習することが実現可能になります。
ヒントン博士によるDBN手法は、現代AIのトレンドでもある自己教師あり学習(Self-supervised Learning)の先駆けとなるものでした。まさに、大規模言語モデル(LLM)をはじめとする膨大なデータを学習した現代のAIの躍進を支える鍵となったのです。
各階のスタッフが自主練を終え、自分たちの階が扱うべき情報のクセを熟知したら、ステップ2へと進みます。
ステップ2は、最終的な全体仕上げの工程です。ここで、初めて、屋上のリアクションという正解を使って、1階までのスタッフに伝言ゲームの学習を開始します。つまりバックプロパゲーションです。
各階のスタッフはステップ1の自主練によって基礎が固まっている(良質な初期値を持つ)状態で、バックプロパゲーションの工程に移るのです。
すると、従来のいきなりバックプロパゲーションした場合(つまり各階の初期値がランダムな状態)と比べて、劇的に学習が安定し、賢く学習できたのです。

この成功とともに、一つの言葉が現代に続くAIの代名詞となります。
それが、ディープラーニング(深層学習)です。
層を深くすれば賢くできる、でも、伝言が消えて学習できない。
そんな牙城がやっと崩れ、深いネットワークが現実的な存在になった瞬間、夢物語だったディープラーニングという言葉は、リアリティのある言葉へと代わり学会の常識を塗り替えていくのです。
加速する洗練
2006年のヒントン博士の功績により、「ディープラーニングには可能性がある」という認識のもと、その進化は連鎖し、現代のディープラーニングの土台となるパーツが確立されていきます。
関数の洗練
勾配消失は、各パーセプトロン(ニューロン)の出力値の変化率(勾配)が0.25ほどの小さな値であるため、層の数だけそれらが掛け合わさると、値が小さくなるという問題でした。各パーセプトロンの内部で求まった「$${-\infty \sim \infty}$$」の値は活性化関数によって「$${0 \sim 1}$$」へ変換されて最終的に出力されます。
この時、従来の活性化関数にはシグモイド関数$${\sigma()}$$が用いられていました。
$${\sigma(x) = \frac{1}{1 + e^{-x}}}$$
式の通り、シグモイド関数$${\sigma()}$$は入力$${x}$$の増加に対して1に向って収束するような曲線を描きます。そのため、その出力の変化率(勾配)は最大でも0.25であるため、勾配消失に繋がっていたのです。
この問題を根本的に打開する方法が表れました。
それが、$${\text{ReLU}()}$$という関数を活性化関数に利用するという方法です。
$${\text{ReLU}(x) = \max(0, x)}$$
この関数はとてもシンプルで、入力$${x}$$が負のときは0を出力し、正のときはそのまま$${x}$$を出力します。
これにより、「$${-\infty ~\sim \infty}$$」の計算値を「$${0 \sim \infty}$$」の範囲へ変換するのです。
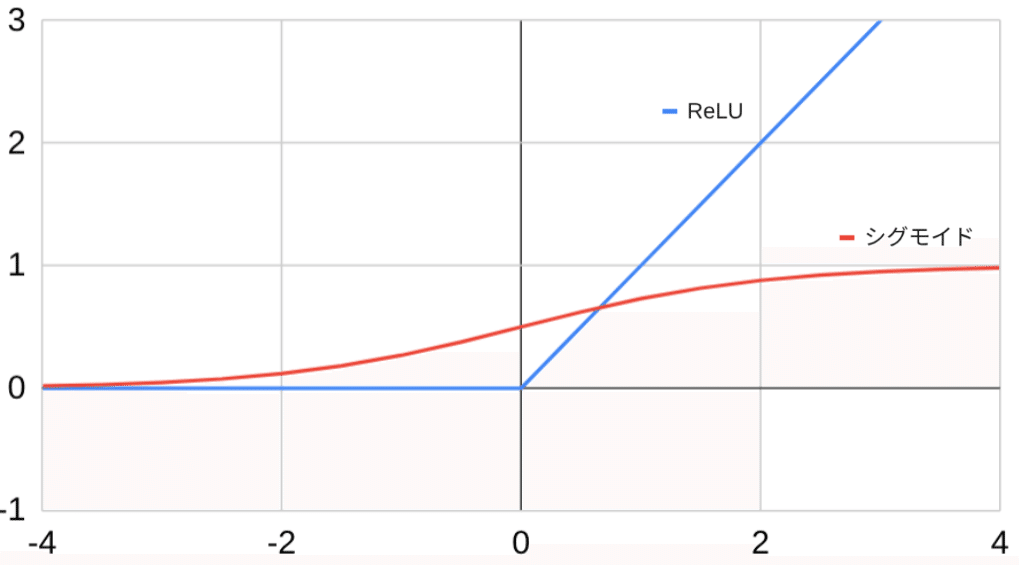
ReLUの単純な処理は計算コストも小さく、それでいて、正の$${x}$$をそのまま$${x}$$として出力するため、この時の変化率(勾配)は1で一定となります。そのため、層が進んで勾配を何度も掛けても$${1 \times 1 \times \dots = 1 }$$と、根本的に勾配消失が発生しなくなるのです。
この認識を確実なものとしたのは2011年、モントリオール大学のザビエル・グロロらが発表した論文『Deep Sparse Rectifier Neural Networks』です。
この論文により、深いニューラルネットワークにおける勾配消失問題を根本的に解決する救世主として、ReLUの優位性が決定づけられました。
ここで、読者の皆さんは不思議に思うかもしれません。ReLUが登場して勾配消失が解決したのなら、先ほどのDBNによる事前学習は不要になるのではないか?と。結論から言えば、その通りです。ReLUができたことで勾配消失を防ぐ目的で事前学習を行う必要はなくなりました。しかし、ヒントン博士の提案した事前学習の考え自体が消えたわけではありません。現代において、LLMなどのAIが膨大なデータから知識を抽出するために「自己教師あり学習」という新たな形で、現代AIを支える核となっています。
世界が震撼したAIの衝撃
こうして、着実に洗練を重ねたディープラーニングは、従来のニューラルネットワークと比べ物にならないほどの賢さを手にしました。
そのことを世間が目の当たりにしたのは、2012年、ヒントン博士の教え子で大学院生のアレックス・クリジェフスキーが作ったAIモデル「AlexNet」です。
彼の名を冠したこのAIモデルは当時のコンピュータービジョン(画像解析分野)における最高精度を大幅に塗り替える大革命を起こしました。
現在、AIというとLLMなどの言語モデルをイメージする人も多いかもしれませんが、当時、AIというと画像解析(例えば、物体検知や顔認識など)が主戦場でした。
従来のコンピュータービジョン技術では、人間が特徴を上手く計算できるように頑張って加工したり、計算する仕組みを人手で調整したりして造られており、それでもなお、数%改善するかしないかと言う中でしのぎを削っていました。そんな中、ディープラーニングのAlexNetは、人がルールを示さなくてもAI自らが画像の中の特徴を見つけ出して、人の手を借りずに勝手に学ぶというまさに知能が宿ったかのような振る舞いを見せました。
そして、AlexNetは2位に圧倒的な差をつけ、さらには、前年比で誤り率を10ポイント以上改善するという異次元の能力を見せたのです。コンテストの歴史を一夜で十年分飛び越えたかのような衝撃です。
この歴史的快挙の裏側には、AlexNetの開発者アレックスによる天才的な実装力、そして、一人の女性研究者によるデータへの信念が織りなす壮絶な挑戦の物語がありました。
AI界のゴッドマザーによるデータ革命
当時のAI研究では、より優れたモデル構造を生み出すことに力と情熱を注いでいました。
そんな中、スタンフォード大学のフェイフェイ・リエ博士は、他の研究者とは異なる部分に目を向けていました。
リエ博士の頭の中にあったのは、AIの構造ではなく、AIを学ばせる教材の質に対する疑問だったのです。
リエ博士は、人の赤ちゃんは世界をどう学ぶのかに注目しました。子供の目は、起きている間、絶え間なく大量の視覚データを脳に送り続けています。多様な世界の映像を膨大に見続けているから、赤ちゃんは賢くなれるのだ。では、今のAIが賢くなれないのは、見せるデータの多様性と量が圧倒的に足りないからではないか?
当時のコンピュータービジョンに用いられる学習用画像データは、数百枚が一般的で、写されている内容も限定的でした。AIの学習を実現するには特定の限られた世界の映像ではなく、世の中にある無数の世界の映像を見せる必要があると確信したのです。
博士の有名な言葉に「数学的なモデルをいくらこねくり回しても、データが貧弱であれば、それは地図を持たずに暗闇を歩くようなものだ」という言葉があります。AIの進化には、まず世の全てを写した巨大なデータの塊を作る必要があると信念を強く持っていたのです。
当時の学会では、「データの収集に時間を費やすのは科学ではない」と冷遇されたとの話もあります。しかし、彼女の信念はそんな言葉には屈しません。
質より量?いやいや、質も量も大切だ。1,400万枚以上にものぼる画像をなんと2万以上のカテゴリに人の手で分類しました。膨大な画像の仕訳にはクラウドソーシングの力を使い、世界中の人々が協力しました。
そして、彼女は「ImageNet」という画像データセットを完成させます。
ImageNetはオープンソースとして世界中の研究者に解放され、現代までの様々なAIモデルに影響を与える事となります。
もちろん、今回の物語の主人公でもある、AlexNetに使われた学習データも、まさにこのImageNetです。リエ博士がデータへの信念と情熱を注がなければ、AlexNetは誕生しなかったのです。
この、ImageNetの成功を引き金として、「データの量と多様性が知能を作る」というリエ博士の哲学は、現在のLLMにそのまま継承されています。
多層で膨大なネットワークを計算する演算装置
ディープラーニングを生み出すのに、全ての道具が揃ったかに見えました。しかし、最後の最後に立ちふさがったのは、学習しようとすると絶望的に処理時間がかかるという計算機(CPU)の処理能力の限界でした。
ニューラルネットワークの学習は、ひたすら巨大な行列の演算を繰り返す作業です。高校の線形代数を思い出してください。3x3の行列の掛け算でも筆算で一つずつ掛けて足してするの大変でしたよね。超巨大な行列ともなると、とんでもない数の演算をひたすら繰り返すことになるのは想像が出来ると思います。
一般的なCPUは、1回1回の計算速度は高速なのですが、一度に並行して計算できるのが数十程度ととても少ないという特徴があります。
そのため、1,400万枚を超えるImageNetデータをCPUで学習させようとすると、数ヶ月から数年かかるという計算結果になり、研究そのものが成立しない状態だったのです。
しかし、アレックスは、じゃぁ無理かぁと諦めたりはしませんでした。彼はゲーマーたちが3Dゲームを楽しむために使っていたNVIDIA製のGPUに目をつけました。
アレックスがGPUに目をつけるきっかけとなったのは、スタンフォード大学のアンドリュー・ン教授らが発表した論文です。2009年、彼らは「GPUを使えばディープラーニングの学習を70倍以上速くできる」という論文『Large-scale Deep Belief Networks on Graphics Processors』を発表しました。
GPUは、画面上の数百万個のピクセルを同時に描画するために、単純な計算を同時にこなす「コア」を数千個持っています。
「大量のデータを、単純なルールで一斉に計算する」というGPUの仕組みが、ディープラーニングの行列演算に驚くほどピタリと一致したのです。
ただ、ン教授の論文が発表されてもなお、当時はまだ「理論的には速いはずだが、実際に扱うのは恐ろしく面倒で、誰も使いこなせていない」という状態であり、知る人ぞ知る理論上の武器という状態でした。
もちろん、当時は現在のようにGPUを簡単にAIで扱うためのライブラリ(PyTorchやTensorFlowなど)など存在しないのです。
しかし、アレックスは天才的なプログラミングの才能がありました。
アレックスは、NVIDIAが提供していたCUDAという言語を使い、GPUのメモリ管理まで細かく制御する専用の学習プログラムを自作したのです。
GPUをAIに利用できないだろうか?
これこそ、現代ではあたりまえとなったGPUでAIを動かすという試みが、現実に動き出した瞬間です。
彼らの試みは大正解でした。
CPUでは数年かかると言われた学習を、わずか1週間程度に短縮することに成功したのです。
研究室の片隅で、ゲーム用のGPUと格闘したアレックスの挑戦がなければ、ディープラーニングは机上の空論として再び冬の時代に埋もれたかもしれません。
しかし、彼の功労が最後のピースとなって、AlexNetそして、ディープラーニングが世界の常識を塗り替えることに繋がったのです。
GPUによる科学計算とディープラーニングの交わり
2000年代前半、一部の研究者たちは「このゲーム用のチップ、科学計算に使えるんじゃないか?」と考え始めました。これをGPGPU(General-Purpose computing on GPU:GPUによる汎用計算)と呼びます。ここでNVIDIAのCEO、ジェンスン・フアン氏が決断を下します。
「グラフィックスの知識がなくても、C言語のような標準的なプログラミング言語でGPUを直接操れるようにしよう」
こうして生まれたのがCUDAです。CUDA言語が誕生したことで、グラフィックの専門知識が必要だったゲーム用チップに対して、汎用計算への道が切り開かれたのです。
GPUを計算機として利用できるようにするCUDA言語の存在があったから、アレックスはAlexNetを完成させることが出来ました。
なお、アレックスがCUDAを触りはじめた頃、当時のCUDAには今のように便利なライブラリは整っていません。アレックスが凄かったのは、誰もが面倒だと避けていたCUDAの泥臭いプログラミングを、極限まで突き詰めて完成させたことにあります。
ディープラーニングという最先端理論をCUDAという出来立ての言語で書き上げるのは、未だ誰も挑戦していない未知の領域でした。そんな中、ハードウェアの限界ギリギリまでチューニングする職人芸を見せ、本当に実装を果たしてしまったのです。
例えるならば、アレックスはまさに、最新のエンジンを自ら分解・改造して、爆速のレーシングカーを組み上げた凄腕メカニックのような存在だったと言えるのではないでしょうか。
繋がる過去と今、そして未来
AlexNetの衝撃から始まった第3次AIブームは、今もなお続く生成AIブーム(第3.5次AIブーム)へとバトンをつなぎ現代のAIへと進化を続けています。
言葉の知性を生んだTransformerと、イメージの創造を可能としたDiffusion Modelというディープラーニングの革命児たちが誕生し、まさに今、大きな台風の目となり、現代社会に大きな革新をもたらしているのです。
ここまで、5回に渡るAIの起源を見つめる物語にお付き合いいただきありがとうございます。
私は、この『[ニューラルネットワーク] 今こそ起源を見つめる時』の執筆を通して、いかにして今があるのかを問い続けていました。
AIの物語には様々な科学が連鎖し、多様な人物達の情熱が交差して、一歩一歩、時には大きく、AIの道を歩み進めてきたことがわかりました。
歴史の起点は、AIという言葉自体が存在しない「考えるとはなにか?」という哲学から始まりました。そこから、思考が生まれる理由を探る解明の科学へと発展し、やがてその情熱は、人工的な知能を生み出すという創造の科学へと燃え上がりました。そして、今、ChatGPTやGeminiといった身近で便利な存在にまで進化を遂げているのです。
ここに、偶発的に生まれたものは存在しませんでした。唯一偶発的に生まれたものを挙げるとしたら、それは人間を含む自然の摂理でしょう。
自然が生み出した人間を見つめ、疑問を持つことで、科学の追求と創造のアイディアへと昇華し、次なる一手を繋いできたのです。
全ては繋がっています。
一度、投げ捨てられ、不要な存在と切り捨てられても、見つめた事実が論文のような文書として形に残れば、時代のどこかで、そのバトンが繋がり、次の科学の連鎖へと広がっていくのです。
この物語は終わったわけではありません。
まさに、今、私たちはこの物語の中を生きています。
今あなたは、未来へと続くこの物語をどのように見つめますか。
私は一度ここで筆を置きますが、また未来で科学の歴史をまとめるときが楽しみです。




